дҪҝз”Ёtensorflowе’ҢKerasзҡ„еҲқзә§ж•ҷзЁӢ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»Ӣз»Қдәәе·ҘзҘһз»ҸзҪ‘з»ң(ANNs)жҳҜжңәеҷЁеӯҰд№ жҠҖжңҜзҡ„й«ҳзә§зүҲжң¬ пјҢ жҳҜж·ұеәҰеӯҰд№ зҡ„ж ёеҝғ гҖӮ дәәе·ҘзҘһз»ҸзҪ‘з»ңж¶үеҸҠд»ҘдёӢжҰӮеҝө гҖӮ иҫ“е…Ҙиҫ“еҮәеұӮгҖҒйҡҗи—ҸеұӮгҖҒйҡҗи—ҸеұӮдёӢзҡ„зҘһз»Ҹе…ғгҖҒжӯЈеҗ‘дј ж’ӯе’ҢеҸҚеҗ‘дј ж’ӯ гҖӮ
з®ҖеҚ•ең°иҜҙ пјҢ иҫ“е…ҘеұӮжҳҜдёҖз»„иҮӘеҸҳйҮҸ пјҢ иҫ“еҮәеұӮд»ЈиЎЁжңҖз»Ҳзҡ„иҫ“еҮә(еӣ еҸҳйҮҸ) пјҢ йҡҗи—ҸеұӮз”ұзҘһз»Ҹе…ғз»„жҲҗ пјҢ еңЁйӮЈйҮҢеә”з”Ёж–№зЁӢе’ҢжҝҖжҙ»еҮҪж•° гҖӮ еүҚеҗ‘дј ж’ӯи®Ёи®әж–№зЁӢзҡ„е…·дҪ“еҪўејҸд»ҘиҺ·еҫ—жңҖз»Ҳиҫ“еҮә пјҢ иҖҢеҸҚеҗ‘дј ж’ӯеҲҷи®Ўз®—жўҜеәҰдёӢйҷҚд»Ҙзӣёеә”ең°жӣҙж–°еҸӮж•° гҖӮ
ж·ұеұӮзҘһз»ҸзҪ‘з»ңеҪ“дёҖдёӘANNеҢ…еҗ«дёҖдёӘеҫҲж·ұзҡ„йҡҗи—ҸеұӮж—¶ пјҢ е®ғиў«з§°дёәж·ұеәҰзҘһз»ҸзҪ‘з»ң(DNN) гҖӮ DNNе…·жңүеӨҡдёӘжқғйҮҚе’ҢеҒҸе·®йЎ№ пјҢ жҜҸдёҖдёӘйғҪйңҖиҰҒи®ӯз»ғ гҖӮ еҸҚеҗ‘дј ж’ӯеҸҜд»ҘзЎ®е®ҡеҰӮдҪ•и°ғж•ҙжүҖжңүзҘһз»Ҹе…ғзҡ„жҜҸдёӘжқғйҮҚе’ҢжҜҸдёӘеҒҸе·®йЎ№ пјҢ д»ҘеҮҸе°‘иҜҜе·® гҖӮ йҷӨйқһзҪ‘з»ң收ж•ӣеҲ°жңҖе°ҸиҜҜе·® пјҢ еҗҰеҲҷиҜҘиҝҮзЁӢе°ҶйҮҚеӨҚ гҖӮ
з®—жі•жӯҘйӘӨеҰӮдёӢпјҡ
- еҫ—еҲ°и®ӯз»ғе’ҢжөӢиҜ•ж•°жҚ®д»Ҙи®ӯз»ғе’ҢйӘҢиҜҒжЁЎеһӢзҡ„иҫ“еҮә гҖӮ жүҖжңүж¶үеҸҠзӣёе…іжҖ§гҖҒзҰ»зҫӨеҖјеӨ„зҗҶзҡ„з»ҹи®ЎеҒҮи®ҫд»Қ然жңүж•Ҳ пјҢ еҝ…йЎ»еҠ д»ҘеӨ„зҗҶ гҖӮ
- иҫ“е…ҘеұӮз”ұиҮӘеҸҳйҮҸеҸҠе…¶еҗ„иҮӘзҡ„еҖјз»„жҲҗ гҖӮ и®ӯз»ғйӣҶеҲҶдёәеӨҡдёӘbatch гҖӮ и®ӯз»ғйӣҶе®Ңж•ҙзҡ„и®ӯз»ғе®Ңз§°дёәдёҖдёӘepoch гҖӮ epochи¶ҠеӨҡ пјҢ и®ӯз»ғж—¶й—ҙи¶Ҡй•ҝ
- жҜҸдёӘbatchиў«дј йҖ’еҲ°иҫ“е…ҘеұӮ пјҢ иҫ“е…ҘеұӮе°Ҷе…¶еҸ‘йҖҒеҲ°з¬¬дёҖдёӘйҡҗи—ҸеұӮ гҖӮ и®Ўз®—иҜҘеұӮдёӯжүҖжңүзҘһз»Ҹе…ғзҡ„иҫ“еҮә(еҜ№дәҺжҜҸдёҖдёӘе°Ҹжү№йҮҸ) гҖӮ з»“жһңиў«дј йҖ’еҲ°дёӢдёҖеұӮ пјҢ иҝҷдёӘиҝҮзЁӢйҮҚеӨҚ пјҢ зӣҙеҲ°жҲ‘们еҫ—еҲ°жңҖеҗҺдёҖеұӮзҡ„иҫ“еҮә пјҢ еҚіиҫ“еҮәеұӮ гҖӮ иҝҷжҳҜеүҚеҗ‘дј ж’ӯпјҡе°ұеғҸеҒҡйў„жөӢдёҖж · пјҢ йҷӨдәҶжүҖжңүдёӯй—ҙз»“жһңйғҪдјҡиў«дҝқз•ҷ пјҢ еӣ дёәе®ғ们жҳҜеҸҚеҗ‘дј ж’ӯжүҖйңҖиҰҒзҡ„
- 然еҗҺдҪҝз”ЁжҚҹеӨұеҮҪж•°жөӢйҮҸзҪ‘з»ңзҡ„иҫ“еҮәиҜҜе·® пјҢ иҜҘеҮҪж•°е°Ҷжңҹжңӣиҫ“еҮәдёҺзҪ‘з»ңзҡ„е®һйҷ…иҫ“еҮәиҝӣиЎҢжҜ”иҫғ
- и®Ўз®—дәҶжҜҸдёӘеҸӮж•°еҜ№иҜҜе·®йЎ№зҡ„иҙЎзҢ®
- иҜҘз®—жі•ж №жҚ®еӯҰд№ йҖҹзҺҮ(еҸҚеҗ‘дј ж’ӯ)жү§иЎҢжўҜеәҰдёӢйҷҚжқҘи°ғж•ҙжқғйҮҚе’ҢеҸӮж•° пјҢ 并且иҜҘиҝҮзЁӢдјҡйҮҚеӨҚиҝӣиЎҢ
дҫӢеҰӮ пјҢ еҰӮжһңе°ҶжүҖжңүжқғйҮҚе’ҢеҒҸ移еҲқе§ӢеҢ–дёәйӣ¶ пјҢ еҲҷз»ҷе®ҡеұӮдёӯзҡ„жүҖжңүзҘһз»Ҹе…ғе°Ҷе®Ңе…ЁзӣёеҗҢ пјҢ еӣ жӯӨеҸҚеҗ‘дј ж’ӯе°Ҷд»Ҙе®Ңе…ЁзӣёеҗҢзҡ„ж–№ејҸеҪұе“Қе®ғ们 пјҢ еӣ жӯӨе®ғ们е°ҶдҝқжҢҒзӣёеҗҢ гҖӮ жҚўеҸҘиҜқиҜҙ пјҢ е°Ҫз®ЎжҜҸеұӮжңүж•°зҷҫдёӘзҘһз»Ҹе…ғ пјҢ дҪҶдҪ зҡ„жЁЎеһӢе°ҶиЎЁзҺ°еҫ—еҘҪеғҸжҜҸеұӮеҸӘжңүдёҖдёӘзҘһз»Ҹе…ғпјҡе®ғдёҚдјҡеӨӘиҒӘжҳҺ гҖӮ зӣёеҸҚ пјҢ еҰӮжһңдҪ йҡҸжңәеҲқе§ӢеҢ–жқғйҮҚ пјҢ дҪ е°ұжү“з ҙдәҶеҜ№з§°жҖ§ пјҢ е…Ғи®ёеҸҚеҗ‘дј ж’ӯжқҘи®ӯз»ғдёҚеҗҢзҡ„зҘһз»Ҹе…ғ
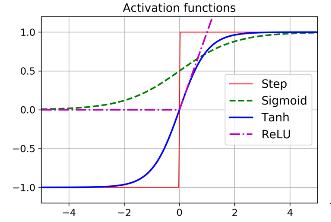
жҝҖжҙ»еҮҪж•°жҝҖжҙ»еҮҪж•°жҳҜжўҜеәҰдёӢйҷҚзҡ„е…ій”® гҖӮ жўҜеәҰдёӢйҷҚдёҚиғҪеңЁе№ійқўдёҠ移еҠЁ пјҢ еӣ жӯӨжңүдёҖдёӘе®ҡд№үиүҜеҘҪзҡ„йқһйӣ¶еҜјж•°жҳҜеҫҲйҮҚиҰҒзҡ„ пјҢ д»ҘдҪҝжўҜеәҰдёӢйҷҚеңЁжҜҸдёҖжӯҘйғҪеҸ–еҫ—иҝӣеұ• гҖӮ SigmoidйҖҡеёёз”ЁдәҺlogisticеӣһеҪ’й—®йўҳ пјҢ дҪҶжҳҜ пјҢ д№ҹжңүе…¶д»–жөҒиЎҢзҡ„йҖүжӢ© гҖӮ
еҸҢжӣІжӯЈеҲҮеҮҪж•°иҝҷдёӘеҮҪж•°жҳҜSеҪўзҡ„ пјҢ иҝһз»ӯзҡ„ пјҢ иҫ“еҮәиҢғеӣҙеңЁ-1еҲ°+1д№Ӣй—ҙ гҖӮ еңЁи®ӯз»ғејҖе§Ӣж—¶ пјҢ жҜҸдёҖеұӮзҡ„иҫ“еҮәжҲ–еӨҡжҲ–е°‘йғҪд»Ҙ0дёәдёӯеҝғ пјҢ еӣ жӯӨжңүеҠ©дәҺжӣҙеҝ«ең°ж”¶ж•ӣ гҖӮ
ж•ҙжөҒзәҝжҖ§еҚ•е…ғеҜ№дәҺе°ҸдәҺ0зҡ„иҫ“е…Ҙ пјҢ е®ғжҳҜдёҚеҸҜеҫ®зҡ„ гҖӮ еҜ№дәҺе…¶д»–жғ…еҶө пјҢ е®ғдә§з”ҹиүҜеҘҪзҡ„иҫ“еҮә пјҢ жӣҙйҮҚиҰҒзҡ„жҳҜе…·жңүжӣҙеҝ«зҡ„и®Ўз®—йҖҹеәҰ гҖӮ еҮҪж•°жІЎжңүжңҖеӨ§иҫ“еҮә пјҢ еӣ жӯӨеңЁжўҜеәҰдёӢйҷҚиҝҮзЁӢдёӯеҸҜиғҪеҮәзҺ°зҡ„дёҖдәӣй—®йўҳеҫ—еҲ°дәҶеҫҲеҘҪзҡ„еӨ„зҗҶ гҖӮ
дёәд»Җд№ҲжҲ‘们йңҖиҰҒжҝҖжҙ»еҮҪж•°пјҹеҒҮи®ҫf(x)=2x+5е’Ңg(x)=3x-1 гҖӮ дёӨдёӘиҫ“е…ҘйЎ№зҡ„жқғйҮҚжҳҜдёҚеҗҢзҡ„ гҖӮ еңЁй“ҫжҺҘиҝҷдәӣеҮҪж•°ж—¶ пјҢ жҲ‘们еҫ—еҲ°зҡ„жҳҜ пјҢ f(g(x))=2(3x-1)+5=6x+3 пјҢ иҝҷеҸҲжҳҜдёҖдёӘзәҝжҖ§ж–№зЁӢ гҖӮ йқһзәҝжҖ§зҡ„зјәеӨұиЎЁзҺ°дёәж·ұеұӮзҘһз»ҸзҪ‘з»ңдёӯзӯүд»·дәҺдёҖдёӘзәҝжҖ§ж–№зЁӢ гҖӮ иҝҷз§Қжғ…еҶөдёӢзҡ„еӨҚжқӮй—®йўҳз©әй—ҙж— жі•еӨ„зҗҶ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҚҹеӨұеҮҪж•°еңЁеӨ„зҗҶеӣһеҪ’й—®йўҳж—¶ пјҢ жҲ‘们дёҚйңҖиҰҒдёәиҫ“еҮәеұӮдҪҝз”Ёд»»дҪ•жҝҖжҙ»еҮҪж•° гҖӮ еңЁи®ӯз»ғеӣһеҪ’й—®йўҳж—¶дҪҝз”Ёзҡ„жҚҹеӨұеҮҪж•°жҳҜеқҮж–№иҜҜе·® гҖӮ 然иҖҢ пјҢ и®ӯз»ғйӣҶдёӯзҡ„ејӮеёёеҖјеҸҜд»Ҙз”Ёе№іеқҮз»қеҜ№иҜҜе·®жқҘеӨ„зҗҶ гҖӮ HuberжҚҹеӨұд№ҹжҳҜеҹәдәҺеӣһеҪ’зҡ„д»»еҠЎдёӯе№ҝжіӣдҪҝз”Ёзҡ„иҜҜе·®еҮҪж•° гҖӮ
еҪ“иҜҜе·®е°ҸдәҺйҳҲеҖјt(еӨ§еӨҡдёә1)ж—¶ пјҢ HuberжҚҹеӨұжҳҜдәҢж¬Ўзҡ„ пјҢ дҪҶеҪ“иҜҜе·®еӨ§дәҺtж—¶ пјҢ HuberжҚҹеӨұжҳҜзәҝжҖ§зҡ„ гҖӮ дёҺеқҮж–№иҜҜе·®зӣёжҜ” пјҢ зәҝжҖ§йғЁеҲҶдҪҝе…¶еҜ№ејӮеёёеҖјдёҚеӨӘж•Ҹж„ҹ пјҢ 并且дәҢж¬ЎйғЁеҲҶжҜ”е№іеқҮз»қеҜ№иҜҜе·®жӣҙеҝ«ең°ж”¶ж•ӣе’ҢжӣҙзІҫзЎ®зҡ„ж•°еӯ— гҖӮ
жҺЁиҚҗйҳ…иҜ»














- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- иӢ№жһңжңүжңӣеңЁ2021е№ҙеҲқеҸ‘еёғйҰ–ж¬ҫдҪҝз”Ёmini LEDжҳҫзӨәеұҸзҡ„ iPad Pro
- 笔记жң¬дҝқе…»жңүеҰҷжӢӣпјҒеӯҰдјҡиҝҷеҮ жӢӣ笔记жң¬еҶҚжҲҳдёүе№ҙ
- ж•°жҚ®еҸҜи§ҶеҢ–дёүиҠӮиҜҫд№ӢдәҢпјҡеҸҜи§ҶеҢ–зҡ„дҪҝз”Ё
- зҙўе°јsw77дёҺsw55зҡ„дҪҝз”Ёе·®еҲ«ж„ҹеҸ—
- зҲҶж–ҷз§°дёҖеҠ 9зі»еҲ—дёҺжҪңжңӣејҸй•ңеӨҙж— зјҳ 继з»ӯдҪҝз”Ёжҷ®йҖҡй•ҝз„Ұ