老大问:建表为啥还设置个自增 id ?用流水号当主键不正好么( 二 )
索引这里仅介绍 InnoDB 引擎 , 具体可以参考官方文档 , 并且介绍的相对比较简单 。
索引分类
- 聚簇索引:表存储是根据主键列的值组织的 , 以加快涉及主键列的查询和排序 。 在介绍主键时也对聚簇索引进行了介绍 。
- 二级索引:也可以叫辅助索引 , 在辅助索引中会记录对应的主键列以及辅助索引列 。 根据辅助索引进行搜索的时候 , 会先根据辅助索引获取到对应的主键列 , 然后再根据主键去聚簇索引里面搜索 。 一般不建议主键很长 , 因为主键很长辅助索引就会使用更多的空间 。
回表:先在二级索引查询到对应的主键值 , 然后根据主键再去聚簇索引里面去查询 。索引覆盖:二级索引记录了主键列和二级索引列 , 如果我只查询主键列的值和二级索引列的值 , 那就不需要回表了 。
索引的物理结构InnoDB 使用的 B+ 数数据结构 , 根据聚簇索引值(主键/UNQIUE/或者自己生成)构建一颗 B+ 树 , 叶子节点中存放行记录数据 , 所以每个叶子节点也可以叫数据页 。 每个数据页大小默认为 16k , 支持自定义 。
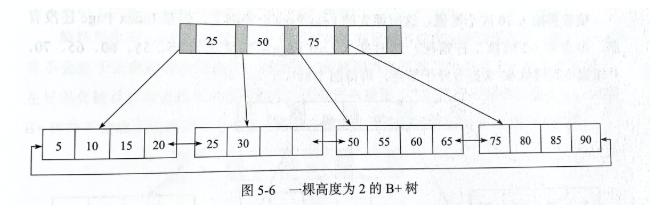 文章插图
文章插图数据的插入当数据插入时 , InnoDB 会使页面 1/16 空闲 , 以备将来插入和更新索引记录 。
- 顺序插入(升序或降序):会将索引页剩余的大约 15/16 装满
- 随机插入:只会使用容量的 1/2 到 15/16
总结Q&AQ: 什么是回表和索引覆盖?
A:
- 回表:先在二级索引查询到对应的主键值 , 然后根据主键再去聚簇索引里面去查询 。
- 索引覆盖:二级索引记录了主键列和二级索引列 , 如果我只查询主键列的值和二级索引列的值 , 那就不需要回表了 。
A:
- 可以唯一标识一行数据 , 在 InnoDB 构建索引树的时候会使用主键 。
- 自增 id 是顺序的 , 可以保证索引树上的数据比较紧凑 , 有更高的空间利用率以及减少数据页的分裂合并等操作 , 提高效率 。
- 一般使用手机号、身份证号作为主键等并不能保证顺序性 。
- 流水号一般相对较长 , 比如 28 位 , 32 位等 , 过长的话会二级索引占用空间较多 。 同时为了业务需求 , 流水号具有一定的随机性 。
同时在建表时除了要设置一个自增 id 用来当做主键 , 小伙伴们在业务开发过程中是否也会遇到一种情况:用户的注销 , 数据的删除等都是进行的逻辑删除 , 而不是物理删除 。
本篇文章介绍比较简陋 , 不足之处 , 希望大家多多指正 。
【老大问:建表为啥还设置个自增 id ?用流水号当主键不正好么】作者:liuzhihang链接:来源:掘金著作权归作者所有 。 商业转载请联系作者获得授权 , 非商业转载请注明出处 。
推荐阅读

















- 小姐姐们的心头好,这些手机为啥这么受欢迎
- “女性机器人”为啥火?外表颜值高、功能强,内部结构也一清二楚
- 涨姿势!手机电量为啥到20%就会提醒充电?
- 为啥宽带每月可以“不限流量”上网,手机套餐却不行?答案已确认
- 明明美国都造出了“人皮面具”,为啥马云却不怕刷脸支付被盗刷?
- 奇怪,手机配置不差,但用了2年后就会出现卡顿,这是为啥呢?
- 曾经被网友喊“马爸爸”,为啥马云如今却不受待见了?答案确认了
- 为啥手机使用一年后,就不提示“系统更新”了?网友:太坑人了
- 涨姿势!手机电量为啥到20%就会提醒充电?真相竟是……
- 为啥手机偷看“不良网站”危害大?答案确认后,网友:改用电脑?