дёҖз§ҚеҹәдәҺеҲ¶йҖ еӨ§ж•°жҚ®зҡ„дә§е“Ғе·ҘиүәиҮӘйҖӮеә”и®ҫи®Ўж–№жі•( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
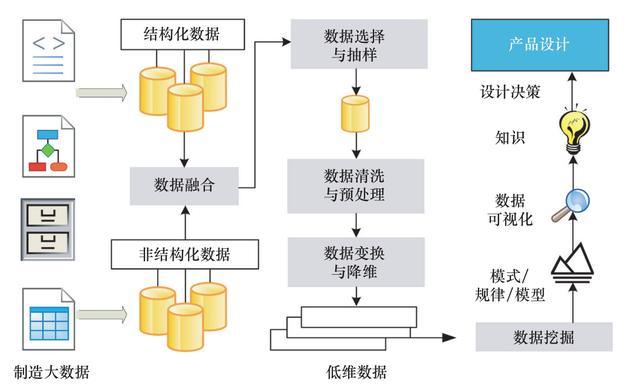
еӣҫ 2 дә§е“Ғе·ҘиүәиҮӘйҖӮеә”и®ҫи®ЎжЁЎејҸзҡ„ж•°жҚ®жҢ–жҺҳиҝҮзЁӢ
пјҲдёҖпјүеӨҡжәҗејӮжһ„ж•°жҚ®иһҚеҗҲ
еңЁе…ҲиҝӣеҲ¶йҖ зі»з»ҹдёӯ пјҢ йҡҸзқҖдј ж„ҹеҷЁз§Қзұ»зҡ„еўһеӨҡ пјҢ дә§з”ҹзҡ„дҝЎжҒҜйҮҸдёҚж–ӯеўһеӨ§ пјҢ ж•°жҚ®зҡ„иЎЁзҺ°еҪўејҸд№ҹжӣҙеҠ еӨҚжқӮ пјҢ еҰӮеҠӣеӯҰдј ж„ҹеҷЁдёҺйҖҹеәҰдј ж„ҹеҷЁе·ҘдҪңж—¶дә§з”ҹж—¶еәҸж•°жҚ®гҖҒи§Ҷи§үдј ж„ҹеҷЁжҚ•жҚүеӣҫеғҸдә§з”ҹеӣҫеғҸж•°жҚ®гҖҒдә§е“Ғж•°жҚ®з®ЎзҗҶзі»з»ҹпјҲPDMпјүиҝҗиЎҢдёӯдә§з”ҹж•°жҚ®зӯү гҖӮ еҲ¶йҖ еӨ§ж•°жҚ®зҡ„жҳҫи‘—зү№еҫҒжҳҜеӨҡж ·жҖ§гҖҒеӨҚжқӮжҖ§е’ҢдёҚзЎ®е®ҡжҖ§ пјҢ еҜ№еҲ¶йҖ еӨ§ж•°жҚ®зҡ„з»ҹдёҖиЎЁиҫҫжҳҜи§ЈеҶіж•°жҚ®иһҚеҗҲй—®йўҳзҡ„е…ій”®е’ҢйҡҫзӮ№ [19] гҖӮ
пјҲ1пјүж—¶еәҸж•°жҚ®зҡ„иһҚеҗҲ гҖӮ еҲ¶йҖ иҝҮзЁӢйҖҡеёёйңҖиҰҒеҜ№жңәеәҠе’Ңе·Ҙ件зҡ„зҠ¶жҖҒиҝӣиЎҢзӣ‘жҺ§ пјҢ йҮҮйӣҶйҖҹеәҰгҖҒеә”еҠӣгҖҒжё©еәҰзӯүж—¶еәҸж•°жҚ® пјҢ иҖҢиҝҷзұ»ж•°жҚ®зҡ„йҮҮйӣҶеё§зҺҮиҫғй«ҳпјҲ40~80 fpsпјү гҖӮ дёәе®һзҺ°ж—¶еәҸж•°жҚ®дёҺе…¶д»–зұ»еһӢж•°жҚ®зҡ„еҢ№й…Қе’ҢиһҚеҗҲ пјҢ йңҖеҜ№ж—¶еәҸж•°жҚ®иҝӣиЎҢдёӢйҮҮж · пјҢ иҝҗз”Ёе№іеқҮеҖјгҖҒж–№е·®зӯүж–№жі•еҸҚжҳ жҹҗдёҖйҳ¶ж®өзҡ„еҠ е·ҘзҠ¶жҖҒ гҖӮ
пјҲ2пјүеӣҫеғҸж•°жҚ®зҡ„иһҚеҗҲ гҖӮ еҜ№дәҺеҲ¶йҖ зі»з»ҹдёӯзҡ„еӣҫеғҸж•°жҚ® пјҢ йңҖиҰҒжҸҗеҸ–еӣҫеғҸдёӯзҡ„дҝЎжҒҜд»ҘиҝӣиЎҢз»“жһ„еҢ–иЎЁиҫҫ гҖӮ дј з»ҹеӣҫеғҸдҝЎжҒҜзҡ„жҸҗеҸ–жҳҜз”ұдәәжүӢеҠЁе®ҢжҲҗзҡ„ пјҢ ж•ҲзҺҮиҫғдҪҺ гҖӮ йҡҸзқҖеҚ·з§ҜзҘһз»ҸзҪ‘з»ңжЁЎеһӢеңЁи®Ўз®—жңәи§Ҷи§үйўҶеҹҹзҡ„еә”з”Ё пјҢ жңәеҷЁзҡ„еӣҫеғҸж„ҹзҹҘиғҪеҠӣжңүдәҶи·Ёи¶ҠејҸеҸ‘еұ• пјҢ еҸҜиҝҗз”ЁжңәеҷЁиҝӣиЎҢеӣҫеғҸж•°жҚ®зҡ„дҝЎжҒҜжҸҗеҸ– пјҢ е°Ҷйқһз»“жһ„еҢ–зҡ„еӣҫеғҸж•°жҚ®иҪ¬жҚўдёәз»“жһ„еҢ–зҡ„ж•°жҚ®дҝЎжҒҜ гҖӮ
пјҲдәҢпјүж•°жҚ®жё…жҙ—дёҺйў„еӨ„зҗҶ
еңЁж•°жҚ®й©ұеҠЁзҡ„дә§е“Ғе·ҘиүәиҮӘйҖӮеә”и®ҫи®ЎжЁЎејҸдёӯ пјҢ ж•°жҚ®зҡ„дҪ“йҮҸе’ҢиҙЁйҮҸйғҪеҸ‘жҢҘзқҖиҮіе…ійҮҚиҰҒзҡ„дҪңз”Ё гҖӮ ж•°жҚ®иҙЁйҮҸеҢ…жӢ¬ж•°жҚ®зҡ„еҮҶзЎ®жҖ§гҖҒе®Ңж•ҙжҖ§гҖҒдёҖиҮҙжҖ§е’Ңжңүж•ҲжҖ§ гҖӮ е…¶дёӯ пјҢ еҮҶзЎ®жҖ§жҢҮж•°жҚ®дёҺзү©зҗҶдё–з•Ңзӣёз¬ҰеҗҲзҡ„зЁӢеәҰ пјҢ е®Ңж•ҙжҖ§жҢҮж•°жҚ®дёӯжңүж•ҲеҖјжүҖеҚ зҡ„жҜ”дҫӢ пјҢ дёҖиҮҙжҖ§жҢҮж•°жҚ®еҜ№жҢҮе®ҡзәҰжқҹзҡ„ж»Ўи¶ізЁӢеәҰ пјҢ жңүж•ҲжҖ§еҲҷиЎЁеҫҒж•°жҚ®зҡ„д»·еҖјеҜҶеәҰ гҖӮ
ж•°жҚ®жё…жҙ—жҢҮе°ҶвҖңи„Ҹж•°жҚ®вҖқжё…йҷӨд»ҘжҸҗй«ҳж•°жҚ®иҙЁйҮҸ пјҢ еҢ…жӢ¬ж•°жҚ®ејӮеёёеҖјдёҺзјәеӨұеҖјзҡ„еӨ„зҗҶгҖҒеҺ»еҷӘзӯү гҖӮ еҜ№дәҺж•°жҚ®ејӮеёёеҖј пјҢ еҸҜд»ҘйҮҮз”Ёи·қзҰ»еәҰйҮҸжҲ–иҒҡзұ»зҡ„ж–№жі•жЈҖжөӢж•°жҚ®йӣҶдёӯзҡ„зҰ»зҫӨзӮ№ пјҢ еҲ йҷӨдёҺж•°жҚ®йӣҶдёӯеҝғи·қзҰ»иҝҮеӨ§зҡ„ж•°жҚ®зӮ№ гҖӮ еҜ№дәҺж•°жҚ®йӣҶдёӯзҡ„зјәеӨұеҖј пјҢ жҸ’еҖјжҳҜж•°жҚ®еӨ„зҗҶзҡ„жңүж•ҲжүӢж®ө пјҢ йҖҡиҝҮж•°жҚ®еЎ«е……дҪҝж•°жҚ®йӣҶи¶ӢдәҺе®Ңж•ҙ гҖӮ й’ҲеҜ№ж•°жҚ®дёӯзҡ„еҷӘеЈ° пјҢ еҸҜд»ҘдҪҝз”Ёе№іж»‘ж»Өжіўзӯүз®—жі•иҝӣиЎҢеҺ»еҷӘ гҖӮ еҲ¶йҖ еӨ§ж•°жҚ®дёӯйҖҡеёёеҢ…еҗ«еӨ§йҮҸйҮҚеӨҚзҡ„ж•°жҚ®зӮ№ пјҢ еҜ№дәҺиҝҷз§Қж•°жҚ®йӣҶиҰҒиҝӣиЎҢж•°жҚ®йҷҚйҮҚ пјҢ еҮҸе°‘ж•°жҚ®еҶ—дҪҷ гҖӮ
пјҲдёүпјүж•°жҚ®еҸҳжҚўдёҺйҷҚз»ҙ
еҲ¶йҖ еӨ§ж•°жҚ®жҳҜеҲ¶йҖ зі»з»ҹдёҺеҲ¶йҖ иҝҮзЁӢзҡ„ж•°еӯ—еҢ–иЎЁиҫҫ пјҢ еҲ¶йҖ зі»з»ҹдёӯ收йӣҶеҲ°зҡ„ж•°жҚ®и¶ҠеӨҡ пјҢ еҜ№еҲ¶йҖ зі»з»ҹзҡ„е®Ңж•ҙжҸҸиҝ°е°ұи¶Ҡжңүеё®еҠ© пјҢ иҖҢиҝҷдёәж•°жҚ®жҢ–жҺҳе·ҘдҪңеёҰжқҘз»ҙж•°зҒҫйҡҫй—®йўҳ гҖӮ з»ҙж•°зҒҫйҡҫжҳҜеӨ„зҗҶй«ҳз»ҙж•°жҚ®ж—¶йҒҮеҲ°зҡ„жңҖеӨ§й—®йўҳд№ӢдёҖ пјҢ дёҚд»…еҪұе“Қж•°жҚ®еҲҶжһҗз®—жі•зҡ„ж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰ пјҢ иҝҳдјҡеҜјиҮҙж•°жҚ®еҲҶжһҗз®—жі•зҡ„дёҚ收ж•ӣй—®йўҳ гҖӮ
еҲ¶йҖ иҝҮзЁӢдёӯйҮҮйӣҶзҡ„еҗ„з§Қж•°жҚ®йҖҡеёёе…·жңүдёҖе®ҡзҡ„зӣёе…іжҖ§ пјҢ еҰӮз„ҠжҺҘиҝҮзЁӢдёӯзҡ„з”өеҺӢдёҺз”өжөҒгҖҒжңәеәҠдё»иҪҙзҡ„иҪ¬йҖҹдёҺеҲҮеүҠйҖҹеәҰзӯү гҖӮ иҝҷз§Қзӣёе…іжҖ§дјҡйҖ жҲҗз»ҙеәҰзҡ„еҶ—дҪҷ пјҢ еўһеҠ дёҚеҝ…иҰҒзҡ„и®Ўз®— пјҢ еӣ иҖҢж•°жҚ®йҷҚз»ҙе°ұжҳҫеҫ—е°ӨдёәйҮҚиҰҒ гҖӮ ж•°жҚ®йҷҚз»ҙжҢҮд»Һй«ҳз»ҙзҡ„ж•°жҚ®з©әй—ҙдёӯдҝқз•ҷеҗҲйҖӮзҡ„зү№еҫҒж•°жҚ®е№¶еү”йҷӨеҶ—дҪҷж•°жҚ® пјҢ йҷҚдҪҺж•°жҚ®з»ҙеәҰ гҖӮ йҷҚз»ҙеҗҺзҡ„ж•°жҚ®ж—ўиғҪдҝқз•ҷеҺҹжңүдҝЎжҒҜйҮҸ пјҢ еҸҲиғҪйҒҝе…Қз»ҙж•°зҒҫйҡҫ гҖӮ
пјҲеӣӣпјүж•°жҚ®жҢ–жҺҳ
еҲ¶йҖ еӨ§ж•°жҚ®жҢ–жҺҳзҡ„дё»иҰҒзӣ®зҡ„жҳҜиҝӣиЎҢйў„жөӢдёҺ规еҲҷжҸҗеҸ– гҖӮ ж•°жҚ®йў„жөӢжҳҜз”Ёе·ІзҹҘеҸҳйҮҸйў„жөӢе…¶д»–еҸҳйҮҸзҡ„жңӘжқҘеҖј пјҢ ж•°жҚ®и§„еҲҷжҸҗеҸ–еҲҷжҳҜжүҫеҲ°ж•°жҚ®дёӯеҸҜиў«зҗҶ解并еҸҜз”ЁдәҺжҢҮеҜјдә§е“Ғи®ҫи®Ўзҡ„йҡҗи—Ҹ规еҲҷ гҖӮ еёёз”Ёзҡ„ж•°жҚ®жҢ–жҺҳж–№жі•жңүеҲҶзұ»гҖҒеӣһеҪ’гҖҒиҒҡзұ»дёҺе…іиҒ”жҖ§еҲҶжһҗ [20] гҖӮ
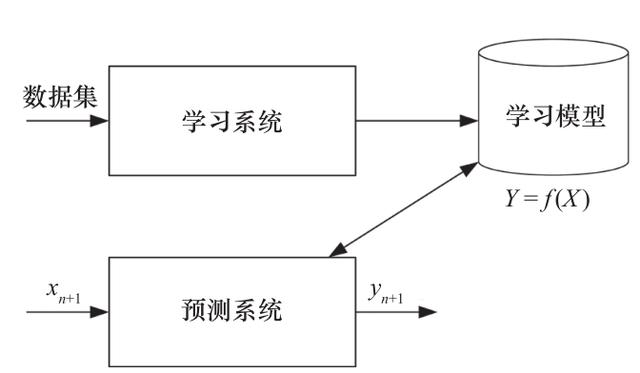
пјҲ1пјүеҲҶзұ»еҲҶжһҗдёҺеӣһеҪ’еҲҶжһҗж–№жі•жҳҜиҝӣиЎҢж•°жҚ®йў„жөӢзҡ„дё»иҰҒж–№жі• пјҢ йғҪжҳҜеҜ№зү№еҫҒз©әй—ҙиҝӣиЎҢжҳ е°„ гҖӮ еҲҶзұ»еҲҶжһҗж–№жі•е°Ҷзү№еҫҒз©әй—ҙжҳ е°„еҲ°зҰ»ж•Јзҡ„еҸҳйҮҸ пјҢ еӣһеҪ’еҲҶжһҗж–№жі•е°Ҷзү№еҫҒз©әй—ҙжҳ е°„еҲ°иҝһз»ӯзҡ„еҸҳйҮҸ гҖӮ еҲҶзұ»еҲҶжһҗе’ҢеӣһеҪ’еҲҶжһҗж–№жі•зҡ„йў„жөӢиҝҮзЁӢеҰӮеӣҫ 3 жүҖзӨә гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ 3 еҲҶзұ»еҲҶжһҗдёҺеӣһеҪ’еҲҶжһҗж–№жі•зҡ„йў„жөӢиҝҮзЁӢ
йҰ–е…Ҳз»ҷе®ҡдёҖдёӘи®ӯз»ғж•°жҚ®йӣҶ
жҺЁиҚҗйҳ…иҜ»















- еҚҺзЎ•еҹәдәҺWRX80зҡ„дё»жқҝзҺ°иә« дёәAMD Ryzen Threadripper Proжү“йҖ
- дёҖжұҪи§Јж”ҫйқ’еІӣе…¬еҸёпјҡжҜҸ216з§’еҲ¶йҖ дёҖиҫҶеҚЎиҪҰпјҢйҰ–еҸ°ж–°иғҪжәҗиҪ»еҚЎд»Ҡе№ҙ10жңҲдёӢзәҝ
- зӮ№иҸңдёҚеә”иҜҘеҸӘжңүжү«з ҒдёҖз§ҚйҖүжӢ©
- еҫ®иҪҜж–°зүҲз”өеӯҗйӮ®д»¶е®ўжҲ·з«ҜжҲӘеӣҫжӣқе…үпјҡеҹәдәҺзҪ‘йЎөз«ҜOutlook
- и®ҫи®Ў|еҝ«и®ҜпјҒеҚҺдёәжҠҖжңҜжңүйҷҗе…¬еҸёе…¬ејҖдёҖз§Қж–°еһӢжүӢжңәеӨ–и§Ӯи®ҫи®Ўдё“еҲ©
- иғҢйқ жҷәиғҪеҲ¶йҖ зҡ„е°Ҹзұійӣ·еҶӣ иғҪжҺҘиҝҮ马дә‘ејәдёңзҡ„еӨ§ж——еҗ—
- жӣқе…ү | е°Ҹй№ҸжҲ–жҳҘиҠӮеүҚжҺЁйҖҒNGPжӣҙж–°пјҢеҹәдәҺй«ҳзІҫең°еӣҫеҸҜиҮӘеҠЁеҸҳйҒ“
- еҹәдәҺSpring+Angular9+MySQLејҖеҸ‘е№іеҸ°
- дёҠи·ҜдәҶпјҹзү№ж–ҜжӢүеңЁе·ҘеҺӮеҲ¶йҖ жөӢиҜ•з”Ёз”өеҠЁеҚЎиҪҰ
- й»‘дәәеҘіжҖ§/йҒӯи§ЈйӣҮзҡ„и°·жӯҢеүҚе‘ҳе·Ҙпјҡз»ҸзҗҶз§°еҘ№зҡ„е·ҙе°”зҡ„ж‘©еҸЈйҹіжҳҜдёҖз§ҚвҖңж®Ӣз–ҫвҖқ