жҢ‘жҲҳж–°зү©дҪ“жҸҸиҝ°й—®йўҳпјҢи§Ҷи§үиҜҚиЎЁи§ЈеҶіж–№жЎҲи¶…и¶Ҡдәәзұ»иЎЁзҺ°
зј–иҖ…жҢүпјҡжңҖиҝ‘ пјҢ з ”з©¶иҖ…们еҸ‘еёғдәҶ nocaps жҢ‘жҲҳ пјҢ з”Ёд»ҘжөӢйҮҸеңЁжІЎжңүеҜ№еә”зҡ„и®ӯз»ғж•°жҚ®зҡ„жғ…еҶөдёӢ пјҢ жЁЎеһӢиғҪеҗҰеҮҶзЎ®жҸҸиҝ°жөӢиҜ•еӣҫеғҸдёӯж–°еҮәзҺ°зҡ„еҗ„з§Қзұ»еҲ«зҡ„зү©дҪ“ гҖӮ й’ҲеҜ№жҢ‘жҲҳдёӯзҡ„й—®йўҳ пјҢ еҫ®иҪҜ Azure и®ӨзҹҘжңҚеҠЎеӣўйҳҹе’Ңеҫ®иҪҜз ”з©¶йҷўзҡ„з ”з©¶е‘ҳжҸҗеҮәдәҶе…Ёж–°и§ЈеҶіж–№жЎҲи§Ҷи§үиҜҚиЎЁйў„и®ӯз»ғ (Visual Vocabulary Pre-training) гҖӮ иҜҘж–№жі•еңЁ nocaps жҢ‘жҲҳдёӯеҸ–еҫ—дәҶж–°зҡ„ SOTA пјҢ 并йҰ–ж¬Ўи¶…и¶Ҡдәәзұ»иЎЁзҺ° гҖӮ
зңӢеӣҫиҜҙиҜқвҖңж–°вҖқй—®йўҳеӣҫеғҸжҸҸиҝ°жҲ–зңӢеӣҫиҜҙиҜқпјҲImage CaptioningпјүжҳҜи®Ўз®—жңәж №жҚ®еӣҫзүҮиҮӘеҠЁз”ҹжҲҗдёҖеҸҘиҜқжқҘжҸҸиҝ°е…¶дёӯзҡ„еҶ…е®№ пјҢ з”ұдәҺе…¶жҪңеңЁзҡ„еә”з”Ёд»·еҖјпјҲдҫӢеҰӮдәәжңәдәӨдә’е’ҢеӣҫеғҸиҜӯиЁҖзҗҶи§ЈпјүиҖҢеҸ—еҲ°дәҶе№ҝжіӣзҡ„е…іжіЁ гҖӮ иҝҷйЎ№е·ҘдҪңж—ўйңҖиҰҒи§Ҷи§үзі»з»ҹеҜ№еӣҫзүҮдёӯзҡ„зү©дҪ“иҝӣиЎҢиҜҶеҲ« пјҢ д№ҹйңҖиҰҒиҜӯиЁҖзі»з»ҹеҜ№иҜҶеҲ«зҡ„зү©дҪ“иҝӣиЎҢжҸҸиҝ° пјҢ еӣ жӯӨеӯҳеңЁеҫҲеӨҡеӨҚжқӮдё”жһҒе…·жҢ‘жҲҳзҡ„й—®йўҳ гҖӮ е…¶дёӯ пјҢ жңҖе…·жҢ‘жҲҳзҡ„дёҖдёӘй—®йўҳе°ұжҳҜж–°зү©дҪ“жҸҸиҝ°пјҲNovel object captioningпјү пјҢ еҚіжҸҸиҝ°жІЎжңүеҮәзҺ°еңЁи®ӯз»ғж•°жҚ®дёӯзҡ„ж–°зү©дҪ“ гҖӮ
жңҖиҝ‘ пјҢ з ”з©¶иҖ…们еҸ‘еёғдәҶ nocaps жҢ‘жҲҳпјҲпјү пјҢ д»ҘжөӢйҮҸеңЁеҚідҪҝжІЎжңүеҜ№еә”зҡ„и®ӯз»ғж•°жҚ®зҡ„жғ…еҶөдёӢ пјҢ жЁЎеһӢиғҪеҗҰеҮҶзЎ®жҸҸиҝ°жөӢиҜ•еӣҫеғҸдёӯж–°еҮәзҺ°зҡ„еҗ„з§Қзұ»еҲ«зҡ„зү©дҪ“ гҖӮ еңЁиҝҷдёӘжҢ‘жҲҳдёӯ пјҢ иҷҪ然没жңүй…ҚеҜ№зҡ„еӣҫеғҸе’Ңж–Үжң¬жҸҸиҝ°пјҲcaptionпјүиҝӣиЎҢжЁЎеһӢи®ӯз»ғ пјҢ дҪҶжҳҜеҸҜд»ҘеҖҹеҠ©и®Ўз®—жңәи§Ҷи§үзҡ„жҠҖжңҜжқҘиҜҶеҲ«еҗ„зұ»зү©дҪ“ гҖӮ дҫӢеҰӮеңЁдёҖдәӣд№ӢеүҚзҡ„е·ҘдҪңдёӯ пјҢ жЁЎеһӢеҸҜд»Ҙе…Ҳз”ҹжҲҗдёҖдёӘеҸҘејҸжЁЎжқҝ пјҢ 然еҗҺз”ЁиҜҶеҲ«зҡ„зү©дҪ“иҝӣиЎҢеЎ«з©ә гҖӮ 然иҖҢ пјҢ иҝҷзұ»ж–№жі•зҡ„иЎЁзҺ°е№¶дёҚе°ҪеҰӮдәәж„Ҹ гҖӮ з”ұдәҺеҸӘиғҪеҲ©з”ЁеҚ•дёҖжЁЎжҖҒзҡ„еӣҫеғҸжҲ–ж–Үжң¬ж•°жҚ® пјҢ жүҖд»ҘжЁЎеһӢж— жі•е……еҲҶеҲ©з”ЁеӣҫеғҸе’Ңж–Үеӯ—д№Ӣй—ҙзҡ„иҒ”зі» гҖӮ еҸҰдёҖзұ»ж–№жі•еҲҷдҪҝз”ЁеҹәдәҺ Transformer зҡ„жЁЎеһӢиҝӣиЎҢеӣҫеғҸе’Ңж–Үжң¬дәӨдә’зҡ„йў„и®ӯз»ғпјҲVision and Language Pre-trainingпјү гҖӮ иҝҷзұ»жЁЎеһӢеңЁеӨҡжЁЎжҖҒпјҲcross-modalпјүзҡ„зү№еҫҒеӯҰд№ дёӯеҸ–еҫ—дәҶжңүж•Ҳзҡ„иҝӣеұ• пјҢ д»ҺиҖҢдҪҝеҫ—еҗҺз»ӯеңЁеӣҫеғҸжҸҸиҝ°д»»еҠЎдёҠзҡ„еҫ®и°ғпјҲfine-tuningпјүиҺ·зӣҠдәҺйў„и®ӯз»ғдёӯеӯҰеҲ°зҡ„зү№еҫҒеҗ‘йҮҸ гҖӮ дҪҶжҳҜ пјҢ иҝҷзұ»ж–№жі•дҫқиө–дәҺжө·йҮҸзҡ„и®ӯз»ғж•°жҚ® пјҢ еңЁиҝҷдёӘжҜ”иөӣдёӯж— жі•еҸ‘жҢҘдҪңз”Ё гҖӮ
й’ҲеҜ№иҝҷдәӣй—®йўҳ пјҢ еҫ®иҪҜ Azure и®ӨзҹҘжңҚеҠЎеӣўйҳҹе’Ңеҫ®иҪҜз ”з©¶йҷўзҡ„з ”з©¶е‘ҳ们жҸҗеҮәдәҶе…Ёж–°зҡ„и§ЈеҶіж–№жЎҲ Visual Vocabulary Pre-trainingпјҲи§Ҷи§үиҜҚиЎЁйў„и®ӯз»ғ пјҢ з®Җз§°VIVO) пјҢ иҜҘж–№жі•еңЁжІЎжңүж–Үжң¬ж ҮжіЁзҡ„жғ…еҶөдёӢд№ҹиғҪиҝӣиЎҢеӣҫеғҸе’Ңж–Үжң¬зҡ„еӨҡжЁЎжҖҒйў„и®ӯз»ғ гҖӮ иҝҷдҪҝеҫ—и®ӯз»ғдёҚеҶҚдҫқиө–дәҺй…ҚеҜ№зҡ„еӣҫеғҸе’Ңж–Үжң¬ж ҮжіЁ пјҢ иҖҢжҳҜеҸҜд»ҘеҲ©з”ЁеӨ§йҮҸзҡ„и®Ўз®—жңәи§Ҷи§үж•°жҚ®йӣҶ пјҢ еҰӮз”ЁдәҺеӣҫеғҸиҜҶеҲ«й—®йўҳзҡ„зұ»еҲ«ж ҮзӯҫпјҲtagпјү гҖӮ еҖҹеҠ©иҝҷдёӘж–№жі• пјҢ жЁЎеһӢеҸҜд»ҘйҖҡиҝҮеӨ§и§„жЁЎж•°жҚ®еӯҰд№ е»әз«ӢеӨҡз§Қзү©дҪ“зҡ„и§Ҷи§үеӨ–иЎЁе’ҢиҜӯд№үеҗҚз§°д№Ӣй—ҙзҡ„иҒ”зі» пјҢ еҚіи§Ҷи§үиҜҚиЎЁпјҲVisual Vocabularyпјүзҡ„е»әз«Ӣ гҖӮ зӣ®еүҚ пјҢ VIVO ж–№жі•еңЁ nocaps жҢ‘жҲҳдёӯеҸ–еҫ—дәҶж–°зҡ„ SOTAпјҲеҚіеҪ“еүҚжңҖдјҳиЎЁзҺ°пјү пјҢ 并且йҰ–ж¬Ўи¶…и¶ҠдәҶдәәзұ»иЎЁзҺ° гҖӮ
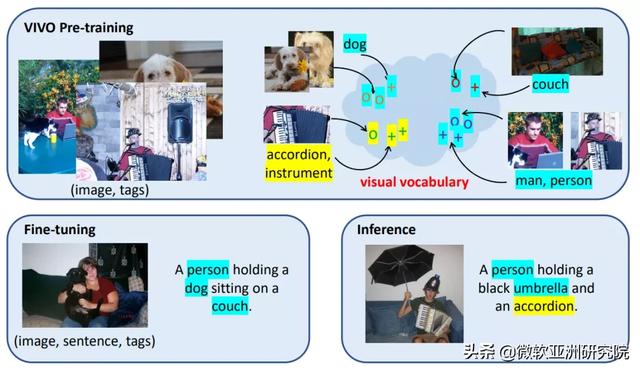
и§Ҷи§үиҜҚиЎЁжҲҗдёәи§ЈеҶій—®йўҳзҡ„е…ій”®VIVO ж–№жі•еҸ–еҫ—жҲҗеҠҹзҡ„е…ій”®еңЁдәҺи§Ҷи§үиҜҚиЎЁпјҲvisual vocabularyпјүзҡ„е»әз«Ӣ гҖӮ еҰӮеӣҫ1жүҖзӨә пјҢ з ”з©¶дәәе‘ҳжҠҠи§Ҷи§үиҜҚиЎЁе®ҡд№үдёәдёҖдёӘеӣҫеғҸе’Ңж–Үеӯ—зҡ„иҒ”еҗҲзү№еҫҒз©әй—ҙпјҲjoint embedding spaceпјү пјҢ е…¶дёӯиҜӯд№үзӣёиҝ‘зҡ„иҜҚжұҮ пјҢ дҫӢеҰӮз”·дәәе’ҢдәәгҖҒжүӢйЈҺзҗҙе’Ңд№җеҷЁ пјҢ дјҡиў«жҳ е°„еҲ°и·қзҰ»жӣҙиҝ‘зҡ„зү№еҫҒеҗ‘йҮҸдёҠ гҖӮ еңЁйў„и®ӯз»ғеӯҰд№ е»әз«ӢдәҶи§Ҷи§үиҜҚиЎЁд»ҘеҗҺ пјҢ жЁЎеһӢиҝҳдјҡеңЁжңүеҜ№еә”зҡ„ж–Үжң¬жҸҸиҝ°зҡ„е°Ҹж•°жҚ®йӣҶдёҠиҝӣиЎҢеҫ®и°ғ гҖӮ еҫ®и°ғж—¶ пјҢ и®ӯз»ғж•°жҚ®еҸӘйңҖиҰҒж¶өзӣ–е°‘йҮҸзҡ„е…ұеҗҢзү©дҪ“ пјҢ дҫӢеҰӮдәәгҖҒзӢ—гҖҒжІҷеҸ‘ пјҢ жЁЎеһӢе°ұиғҪеӯҰд№ еҰӮдҪ•ж №жҚ®еӣҫзүҮе’ҢиҜҶеҲ«еҲ°зҡ„зү©дҪ“жқҘз”ҹжҲҗдёҖдёӘйҖҡз”Ёзҡ„еҸҘејҸжЁЎжқҝ пјҢ 并且жҠҠзү©дҪ“еЎ«е…ҘжЁЎжқҝдёӯзӣёеә”зҡ„дҪҚзҪ® пјҢ дҫӢеҰӮ пјҢ вҖңдәәжҠұзқҖзӢ—вҖқ гҖӮ еңЁжөӢиҜ•йҳ¶ж®ө пјҢ еҚідҪҝеӣҫзүҮдёӯеҮәзҺ°дәҶеҫ®и°ғж—¶жІЎжңүи§ҒиҝҮзҡ„зү©дҪ“ пјҢ дҫӢеҰӮжүӢйЈҺзҗҙ пјҢ жЁЎеһӢдҫқ然еҸҜд»ҘдҪҝз”Ёеҫ®и°ғж—¶еӯҰеҲ°зҡ„еҸҘејҸ пјҢ еҠ дёҠйў„и®ӯз»ғе»әз«Ӣзҡ„и§Ҷи§үиҜҚиЎЁиҝӣиЎҢйҖ еҸҘ пјҢ д»ҺиҖҢеҫ—еҲ°дәҶвҖңдәәжҠұзқҖжүӢйЈҺзҗҙвҖқиҝҷеҸҘжҸҸиҝ° гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ1пјҡVIVO йў„и®ӯз»ғдҪҝз”ЁеӨ§йҮҸзҡ„еӣҫзүҮж Үзӯҫж ҮжіЁжқҘе»әз«Ӣи§Ҷи§үиҜҚиЎЁ
VIVO йў„и®ӯз»ғдҪҝз”ЁеӨ§йҮҸзҡ„еӣҫзүҮж Үзӯҫж ҮжіЁжқҘе»әз«Ӣи§Ҷи§үиҜҚиЎЁ пјҢ е…¶дёӯиҜӯд№үзӣёиҝ‘зҡ„иҜҚжұҮдёҺеҜ№еә”зҡ„еӣҫеғҸеҢәеҹҹзү№еҫҒдјҡиў«жҳ е°„еҲ°и·қзҰ»зӣёиҝ‘зҡ„еҗ‘йҮҸдёҠ гҖӮ еҫ®и°ғдҪҝз”ЁеҸӘж¶өзӣ–дёҖйғЁеҲҶзү©дҪ“пјҲи“қиүІиғҢжҷҜпјүзҡ„е°‘йҮҸж–Үжң¬жҸҸиҝ°ж ҮжіЁиҝӣиЎҢи®ӯз»ғ гҖӮ еңЁжөӢиҜ•жҺЁзҗҶж—¶ пјҢ жЁЎеһӢиғҪеӨҹжҺЁе№ҝз”ҹжҲҗж–°зү©дҪ“пјҲй»„иүІиғҢжҷҜпјүзҡ„иҜӯиЁҖжҸҸиҝ° пјҢ еҫ—зӣҠдәҺйў„и®ӯз»ғж—¶и§ҒиҝҮзҡ„дё°еҜҢзү©дҪ“зұ»еһӢ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- и…ҫи®ҜжёёжҲҸеҸ‘иө·еҜ№еҚҺдёәзҡ„жҢ‘жҲҳпјҢжҲ–еӣ еҗҺиҖ…еҜ№еӣҪеҶ…жүӢжңәеёӮеңәзҡ„еҪұе“ҚеҠӣеӨ§и·Ң
- ж–°еһӢзәҜи“қOLEDеҸҜе…ӢжңҚзӣ®еүҚжҳҫзӨәеұҸи“қе…үжҖ§иғҪдёҚи¶ізҡ„жҢ‘жҲҳ
- вҖңжңәеҷЁдәәеҰ»еӯҗвҖқдёҠеёӮйҒӯжҠўиҙӯпјҢжҳҜеңЁи§ЈеҶіеҲҡйңҖпјҢиҝҳжҳҜеңЁжҢ‘жҲҳдјҰзҗҶпјҹ
- иӢ№жһңжңҚеҠЎж”¶е…ҘеӨ§еўһ еҸҚеһ„ж–ӯе°ҶжҲҗдёәжңҖеӨ§жҢ‘жҲҳ
- Galaxy Note 20жҢ‘жҲҳиҖ…пјҡMoto G Stylus 2021зҡ„жёІжҹ“еӣҫеҮәзҺ°
- ж—Ҙжң¬жӯЈејҸе®ҳе®ЈпјҒдёӯеӣҪйҷўеЈ«еӨҡж¬ЎеҸ‘еЈ°пјҢдёӯеӣҪзҡ„5GгҖҒ6GйқўдёҙеҸҢйҮҚжҢ‘жҲҳ
- дёӯеӣҪиҝҷйЎ№жҠҖжңҜйўҶе…Ҳдё–з•ҢпјҢйҰ–ж¬ЎеҸ‘иө·жҢ‘жҲҳпјҢиӢұеӣҪдәәпјҡзҫҺеӣҪеҸҜдёҚж•ўиҝҷж ·зҺ©
- еә“е…Ӣиҝҳ笑еҫ—еҮәжқҘеҗ—пјҹзә¬еҲӣе·ҘеҺӮдәӢ件еҗҺиӢ№жһңеҸҲиҝҺж–°жҢ‘жҲҳпјҢзҪ‘еҸӢжӢҚжүӢеҸ«еҘҪ
- зәҰжқҹ"зЎ…и°·еёқеӣҪ"вҖ”вҖ”зӣ‘管科жҠҖе·ЁеӨҙзҡ„еӣ°еўғдёҺжҢ‘жҲҳ
- еҶҚи§ҒдәҶпјҢжү«з Ғж”Ҝд»ҳпјҹж–°еһӢж”Ҝд»ҳж–№ејҸиҜ•ж°ҙжҲҗеҠҹпјҢеҫ®дҝЎгҖҒж”Ҝд»ҳе®қиҝҺжқҘжҢ‘жҲҳ