иөӣзҒөжҖқе§ҡйўӮпјҡж•°еӯ—AIиҠҜзүҮиҝӣжӯҘи¶Ӣзј“пјҢйў иҰҶејҸеҲӣж–°йҡҫ | GTIC2020( дёү )
еҜ№дәҺз»Ҳз«ҜеёӮеңәжқҘиҜҙ пјҢ дёҖе®ҡжҳҜй«ҳйӣҶжҲҗеәҰзҡ„ж–№ејҸжҜ”еҲҶз«ӢеҷЁд»¶зҡ„ж–№ејҸеҚ дјҳеҠҝ пјҢ жүҖд»ҘеҜ№дәҺз»Ҳз«ҜеёӮеңәдёҖе®ҡиҰҒиҖғиҷ‘е…Ёйқў пјҢ иҖҢдёҚиғҪд»…д»…иҖғиҷ‘AIиҝҷдёҖдёӘIP гҖӮ
第дёү пјҢ иҪҜ件з”ҹжҖҒжүҚжҳҜAIиҠҜзүҮзҡ„ж ёеҝғеЈҒеһ’ гҖӮ
иӢұдјҹиҫҫеҲӣе§Ӣдәәе…јCEOй»„д»ҒеӢӢжңҖиҝ‘ејҖеҸ‘еёғдјҡж—¶иҜҙ пјҢ иӢұдјҹиҫҫе·Із»Ҹжңү180дёҮзҡ„ејҖеҸ‘иҖ…гҖҒ30дёҮдёӘејҖжәҗйЎ№зӣ® пјҢ 99.99%зҡ„еҲқеӯҰиҖ…еңЁеӯҰAIж—¶дёҖе®ҡдјҡд№°дёҖеқ—GPU пјҢ дёӢиҪҪдёҖдәӣGithubдёҠзҡ„ејҖжәҗйЎ№зӣ®еҒҡиҜ•йӘҢ гҖӮ иҝҷжҳҜиӢұдјҹиҫҫжңҖз»Ҳзҡ„дёҖдёӘжҠӨеҹҺжІі пјҢ е®ғдјҡжңүжәҗжәҗдёҚж–ӯзҡ„ејҖеҸ‘иҖ…еҠ е…Ҙ пјҢ ејҖеҸ‘иҖ…еҸҲдјҡдёәз”ҹжҖҒиҙЎзҢ®ж–°зҡ„йЎ№зӣ® пјҢ еҰӮжһңејҖеҸ‘иҖ…жІЎжңүиҫҫеҲ°дёҖе®ҡж•°йҮҸ пјҢ еҲҷеҫҲйҡҫзӘҒз ҙAIиҠҜзүҮзҡ„з”ҹжҖҒеЈҒеһ’ гҖӮ
е§ҡйўӮиҜҙ пјҢ иҝҷдёҺж»ҙж»ҙгҖҒж·ҳе®қд»ҘеҸҠе…¶д»–дә’иҒ”зҪ‘е№іеҸ°жҳҜдёҖдёӘйҖ»иҫ‘ пјҢ дёҖиҫ№жҳҜе•Ҷ家дёҖиҫ№жҳҜз”ЁжҲ· пјҢ дёҖиҫ№жҳҜејҖеҸ‘иҖ…дёҖиҫ№жҳҜдҪҝз”ЁиҖ… пјҢ иҝҷжҳҜдёҖдёӘй—ӯзҺҜиҪҜ件з”ҹжҖҒзҡ„йҖ»иҫ‘ пјҢ жҳҜжңҖж ёеҝғзҡ„еЈҒеһ’ гҖӮ
еңЁеҚ•зәҜзҡ„ж•°еӯ—иҠҜзүҮйўҶеҹҹгҖҒеҚ•зәҜзҡ„еӯҰжңҜз ”з©¶еҒҡеҫ®жһ¶жһ„иҝӯд»Јзҡ„йўҶеҹҹ пјҢ ж•°еӯ—йӣҶжҲҗз”өи·ҜйўҶеҹҹд»Һ2016е№ҙејҖе§ӢиҮід»ҠжІЎжңүи§ҒеҲ°зү№еҲ«еӨ§зҡ„еҲӣж–° гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
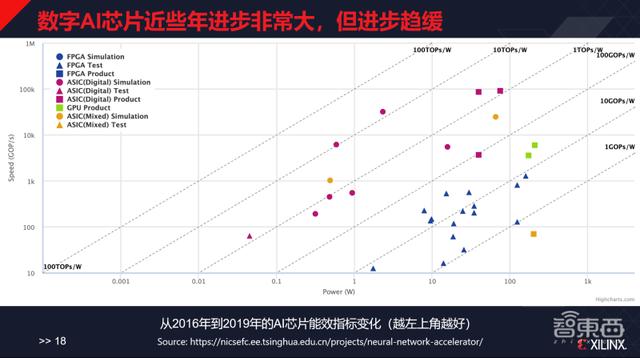
2016е№ҙиҮі2019е№ҙAIиҠҜзүҮиғҪж•ҲжҢҮж ҮеҸҳеҢ–
дёҠеӣҫдёӯжҳҫзӨәзҡ„жҳҜд»Һ2016е№ҙиҮі2019е№ҙзҡ„AIиҠҜзүҮиғҪж•ҲжҢҮж ҮеҸҳеҢ– пјҢ вҖңж–№еҪўвҖқжҳҜе®һйҷ…йҮҸдә§зҡ„дә§е“Ғ гҖӮ иҝҷдёӘеӣҫи¶ҠеҫҖдёҠд»ЈиЎЁжҖ§иғҪи¶ҠеҘҪ пјҢ и¶ҠеҫҖеҸіжҳҜеҠҹиҖ—и¶Ҡй«ҳ пјҢ еӣ жӯӨеңЁиҝҷеј еӣҫдёӯ пјҢ и¶ҠеҒҸеҗ‘е·ҰдёҠи§’ж„Ҹе‘ізқҖжҖ§иғҪи¶ҠеҘҪ гҖӮ
иҖҢе®һйҷ…дёҠеӨ§йҮҸзҡ„вҖңж–№еҪўвҖқйғҪиҗҪеңЁдәҶеӣҫзҡ„еҸідёҠи§’ пјҢ еӨ„дәҺ1~10TOPs/Wзҡ„дёӨжқЎзәҝд№Ӣй—ҙ пјҢ зҺ°еңЁжҖ§иғҪжҜ”иҫғеҘҪзҡ„дә§е“Ғеҹәжң¬дёҠеңЁ1~2TOPs/Wзҡ„еҢәй—ҙеҶ… пјҢ иҝҷеҮ е№ҙеңЁйҮҸдә§зә§еҲ«дёҠжІЎжңүи§ҒеҲ°зү№еҲ«еӨ§зҡ„еҸҳеҢ– гҖӮ иЎҢдёҡеҶ…жңүеҫҲеӨҡе·ҘзЁӢеңЁеҫҖдә§е“Ғж–№еҗ‘иө° пјҢ дҪҶжҳҜйҖҡз”Ёзҡ„еҫ®жһ¶жһ„иҝӯд»Јзҡ„иҝӣжӯҘе·Із»Ҹи¶Ӣзј“ гҖӮ
жӯӨеӨ– пјҢ е§ҡйўӮдёҖзӣҙеңЁе…іжіЁзҡ„дёҖдёӘйҮҚзӮ№еңЁдәҺ пјҢ иҠҜзүҮи¶ҠжқҘи¶Ҡиҙө пјҢ еҜјиҮҙдәҶдёҖдёӘиҫғеӨ§зҡ„й—®йўҳпјҡдёҡеҶ…еҺҹжқҘеҫҲжңҹеҫ…еңЁиЎҢдёҡдёӯеҮәзҺ°дёҖдёӘвҖңз ҙеқҸжҖ§еҲӣж–°вҖқзҡ„дәӢ пјҢ д№ҹе°ұж„Ҹе‘ізқҖжғіиҰҒз”ЁеҫҲдҪҺе»үгҖҒдҫҝжҚ·зҡ„ж–№ејҸе®һзҺ°еҺҹжқҘй«ҳз«Ҝдә§е“Ғзҡ„иғҪеҠӣ гҖӮ жҜ”еҰӮдёҡеҶ…еёҢжңӣAIиҠҜзүҮд»ҘдҪҺд»·гҖҒдҫҝжҚ·зҡ„ж–№ејҸе®һзҺ°GPUзҡ„еҠҹиғҪ пјҢ иҖҢзҺ°еңЁзңӢиө·жқҘ пјҢ е®һзҺ°иҝҷдёҖж„ҝжҷҜеҫҲеӣ°йҡҫ гҖӮ
еңЁеҰӮд»ҠжүҖеӨ„зҡ„ж—¶й—ҙзӮ№ пјҢ ж‘©е°”е®ҡеҫӢиҝҳжІЎжңүжӯ»жҺүдҪҶжҳҜи¶ҠжқҘи¶Ҡиҙө гҖӮ дёҖйў—7nmиҠҜзүҮзҡ„жөҒзүҮйңҖиҰҒ3000дёҮзҫҺе…ғе·ҰеҸі пјҢ еҶҚеҠ дёҠIPгҖҒдәәеҠӣзҡ„жҲҗжң¬ пјҢ з”ҡиҮійңҖиҰҒеӨ§еҮ еҚғдёҮз”ҡиҮіжҳҜдёҠдәҝзҫҺе…ғ пјҢ йңҖиҰҒеҚ–еҮәеҫҲеӨ§зҡ„йҮҸжүҚиғҪ收еӣһжҲҗжң¬ гҖӮ еҜ№дәҺеҲқеҲӣе…¬еҸёжқҘиҜҙ пјҢ иҝҷжҳҜдёҖдёӘйҡҫзӮ№ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
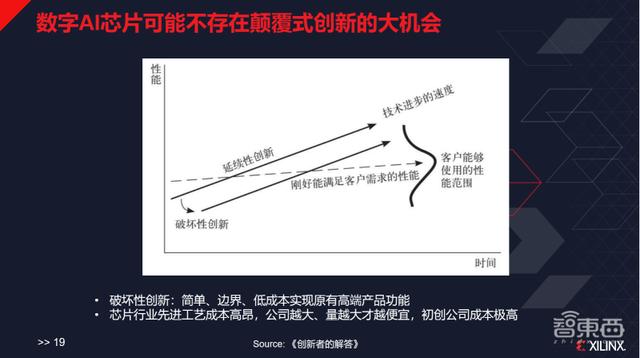
ж•°еӯ—AIиҠҜзүҮеҸҜиғҪдёҚеӯҳеңЁйў иҰҶејҸеҲӣж–°зҡ„еӨ§жңәдјҡ
жңүдәӣиҠҜзүҮе…¬еҸё пјҢ жҜ”еҰӮеЈҒд»һ科жҠҖ пјҢ иһҚдәҶеҫҲеӨҡиө„йҮ‘ пјҢ иғҪеӨҹеҒҡдёӨйў—гҖҒдёүйў—з”ҡиҮіжӣҙеӨҡиҠҜзүҮпјӣиҖҢжңүзҡ„е…¬еҸёеҰӮжһңжІЎжңүиө„йҮ‘ пјҢ еҲҷж— жі•еҸӮдёҺеҲ°иЎҢдёҡжӯЈйқўжҲҳеңәзҡ„з«һдәүдёӯжқҘ гҖӮ
иҝҷдёӘеёӮеңәе·Із»ҸеҸ‘з”ҹеҸҳеҢ– пјҢ йҡҸзқҖж‘©е°”е®ҡеҫӢзҡ„еҸҳеҢ– пјҢ еңЁжӯЈйқўжҲҳеңәдёҠ пјҢ жҲ‘们еҫ—жғідёҖдәӣе…¶д»–зҡ„еҠһжі• пјҢ еҸҜиғҪдёҚиғҪеҚ•зәҜдҫқйқ жһ¶жһ„зҡ„дјҳеҠҝеҸ–еҫ—еҮ еҖҚзҡ„жҖ§иғҪжҸҗеҚҮ пјҢ дёҡз•Ңд№ҹйңҖиҰҒжүҫеҲ°дёҖдәӣж–°зҡ„еә•еұӮжҠҖжңҜиҝӯд»Ј гҖӮ
жҜ”еҰӮеҒҡеӯҳеҶ…и®Ўз®—зҡ„зҹҘеӯҳ科жҠҖе°ұеұһдәҺиҝҷдёҖзұ» пјҢ е®ғе°Ҷи®Ўз®—е’ҢеӯҳеӮЁж”ҫеңЁдёҖиө· пјҢ е°Ҷи®Ўз®—ж”ҫеңЁFlashдёӯ пјҢ е°ұеҸҜд»ҘеҮҸе°‘еӯҳеӮЁзҡ„жҗ¬иҝҗ пјҢ зӘҒз ҙеҚЎеңЁеӯҳеӮЁзҡ„瓶йўҲпјӣеҶҚжҜ”еҰӮжі•еӣҪжңүдёҖ家еҸ«UpMemзҡ„дјҒдёҡжҠҠи®Ўз®—ж”ҫеҲ°DRAMдёӯ пјҢ иҝҳжңүжҜ”еҰӮжҷ®жһ—ж–ҜйЎҝеӨ§еӯҰж•ҷжҺҲзҡ„е°Ҹз»„жҠҠи®Ўз®—ж”ҫеҲ°SRAMдёӯ гҖӮ
еҸҰдёҖз§ҚжҠҖжңҜи·Ҝзәҝ пјҢ е…үи®Ўз®— пјҢ д№ҹжҳҜдёҡеҶ…йқһеёёзңӢеҘҪзҡ„ж–№еҗ‘ гҖӮ з”ЁдёӨжқҹе…үзҡ„е…үејәиЎЁзӨәдёӨдёӘж•°еҖј пјҢ йҖҡиҝҮдёҖдёӘе№Іж¶үд»ӘеҸ‘з”ҹе№Іж¶үиЎҢдёә пјҢ е®ғеҮәе°„зҡ„ејәеәҰе°ұжҳҜдёӨдёӘе…үејәзӣёд№ҳ пјҢ еҶҚд№ҳд»Ҙ他们зӣёдҪҚе·®зҡ„cosпјҲдҪҷејҰпјү пјҢ иҝҷж ·е°ұзӣёеҪ“дәҺз”Ёе…үзҡ„е№Іж¶үзӣҙжҺҘе®ҢжҲҗдәҶд№ҳжі• пјҢ иҝҷз§Қж“ҚдҪңйҖҹеәҰеҫҲеҝ«гҖҒеҠҹиҖ—д№ҹеҫҲдҪҺ пјҢ дҪҶд№ҹжңүеҫҲеӨ§зҡ„й—®йўҳ гҖӮ
еӣ дёәжүҖжңүзҡ„зү©зҗҶеҷЁд»¶йғҪдёҚжҳҜзҗҶжғізҡ„еҷЁд»¶ пјҢ е…үжҜҸз»ҸиҝҮдёҖдёӘе№Іж¶үд»ӘеҸҜиғҪиҰҒжҚҹиҖ—еҚғеҲҶд№ӢдёҖзҡ„ејәеәҰ пјҢ еҰӮжһңжғіиҰҒеҒҡдёҖдёӘ64X64зҡ„йҳөеҲ—жҲ–жҳҜ128X128зҡ„йҳөеҲ— пјҢ жҜҸеҒҡдёҖдёӘи®Ўз®—зҡ„иҝҮзЁӢдёӯ пјҢ жҜҸжқҹе…үиҰҒйҖҡиҝҮеҮ зҷҫдёӘе№Іж¶үеҷЁ пјҢ ж•°еҖје°ұеҸҳдәҶ гҖӮ
зӣ®еүҚеӣҪйҷ…жңҖеҘҪзҡ„ж°ҙе№ід№ҹеҸӘиғҪеңЁ64X64йҳөеҲ—дёҠдҝқиҜҒ8bitдҝЎжҒҜйҮҸжҳҜдёҚеҸҳзҡ„ пјҢ еӣ жӯӨиҝҷз§Қж–№ејҸж— жі•еңЁй«ҳзІҫеәҰгҖҒеӨ§йҳөеҲ—зҡ„иҰҒжұӮдёӢж–ҪиЎҢ пјҢ д№ҹд»ҺиҖҢжІЎеҠһжі•е®һзҺ°зү№еҲ«еӨ§зҡ„жҖ§иғҪ пјҢ еӣ жӯӨиҝҷд№ҹжҳҜдёҖз§ҚиҝҳеңЁејҖеҸ‘дёӯзҡ„и·Ҝзәҝ гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- дёүжҳҹе…¬еҸёеҸ‘еёғ2021ж¬ҫж•°еӯ—еә§иҲұ йӣҶжҲҗиҜёеӨҡй«ҳ科жҠҖ
- жғіе®һзҺ°гҖҠжӣјиҫҫжҙӣдәәгҖӢзҡ„ж•°еӯ—еёғжҷҜеҗ—пјҹзҙўе°јжЁЎеқ—еҢ–еұҸ幕еҚіе°ҶејҖе”®
- и…ҫи®ҜиӢҸе·һжҲҳз•ҘеҗҲдҪңеҶҚеҚҮзә§пјҢи…ҫи®ҜпјҲиӢҸе·һпјүж•°еӯ—дә§дёҡеҹәең°жҸӯзүҢ
- зҙўе°јеҸ‘еёғдёӨж¬ҫCrystal LEDжҳҫзӨәеҷЁ зӣ®ж Үж•°еӯ—з”ҹдә§йўҶеҹҹ
- еҗ‘ж—Ҙи‘өйўҶиҲӘВ·еқҗеёӯи§ЈеҶіж–№жЎҲпјҡиҝңзЁӢеҚҸеҠ©жҺЁиҝӣж•°еӯ—еҢ–еҢ»з–—
- CES 2021гҖҢеұ•жңӣгҖҚпјҡе…Ёж•°еӯ—еҢ–зӣӣдјҡ дҪ жңҖжңҹеҫ…д»Җд№Ҳ
- и…ҫи®Ҝдә‘е°ҶжҗәжүӢ8000家еҗҲдҪңдјҷдјҙпјҢеҠ©еҠӣй•ҝдёүи§’G60科еҲӣиө°е»Ҡж•°еӯ—еҢ–иҪ¬еһӢ
- и…ҫи®ҜдёҺй•ҝдёүи§’G60科еҲӣиө°е»ҠвҖңзүөжүӢвҖқпјҡжү©еұ•з§‘еҲӣвҖңжңӢеҸӢеңҲвҖқжҺЁиҝӣеҹҺеёӮж•°еӯ—еҢ–иҪ¬еһӢ
- еҚҺдёәе‘Ёе»әеҶӣпјҡд»Ҡе№ҙйў„и®ЎдёәйЎәеҫ·еҹ№е…»и¶…иҝҮдёүеҚғеҗҚж•°еӯ—еҢ–дё“дёҡдәәжүҚ
- й—№еү§еҶҚж¬ЎдёҠжј”пјҒдёҚжғідёӯеӣҪдё»еҜјж•°еӯ—ж”Ҝд»ҳпјҢзҫҺеӣҪиҝҷж¬ЎзӣҜдёҠдәҶиҡӮиҡҒе’Ңи…ҫи®Ҝ