иөӣзҒөжҖқе§ҡйўӮпјҡж•°еӯ—AIиҠҜзүҮиҝӣжӯҘи¶Ӣзј“пјҢйў иҰҶејҸеҲӣж–°йҡҫ | GTIC2020( дәҢ )
дәҢгҖҒ AIиҠҜзүҮжңҖйңҖи§ЈеҶізҡ„жҳҜе®ҪеёҰй—®йўҳзҙ§жҺҘзқҖ пјҢ е§ҡйўӮи°ҲеҸҠеҜ№иЎҢдёҡзҺ°зҠ¶зҡ„зңӢжі• гҖӮ д»–иҜҙ пјҢ AIиҠҜзүҮиҝҷдёӘиҜҚз”Ёеҫ—зү№еҲ«жіӣ пјҢ AIйўҶеҹҹжң¬иә«е°ұзү№еҲ«е®Ҫжіӣ пјҢ жңүдёҖе°ҸйғЁеҲҶжүҚжҳҜжңәеҷЁеӯҰд№ пјҢ жңәеҷЁеӯҰд№ дёӯзҡ„дёҖе°ҸйғЁеҲҶжүҚжҳҜж·ұеәҰеӯҰд№ пјҢ ж·ұеәҰеӯҰд№ еӨ©з„¶еҲҮеҲҶдёәи®ӯз»ғе’ҢжҺЁзҗҶдёӨдёӘйҳ¶ж®ө пјҢ е…¶дёӯжңүж•°дёҚиҝҮжқҘзҡ„еҗ„з§ҚзҘһз»ҸзҪ‘з»ң гҖӮ
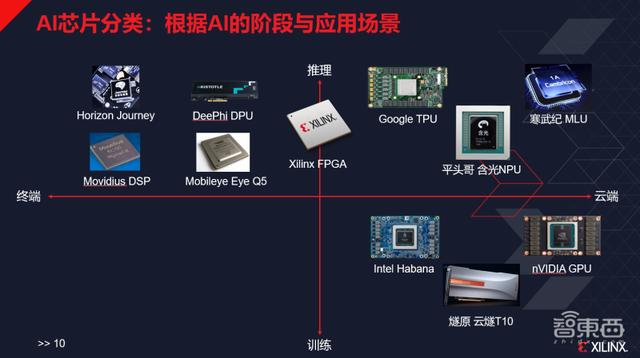
дёҖдёӘAIиҠҜзүҮеҸҜд»ҘжҢҮд»Јзҡ„дёңиҘҝжңүеҫҲеӨҡ пјҢ еӣ жӯӨиҝҷжҳҜдёҖдёӘеҫҲе®Ҫжіӣзҡ„жҰӮеҝө пјҢ жҢүзЁҚдёҘж јзҡ„еҲҶзұ» пјҢ е®ғеҸҜд»ҘеҲҶжҲҗи®ӯз»ғгҖҒжҺЁзҗҶдёӨдёӘйҳ¶ж®ө пјҢ д»ҘеҸҠдә‘з«ҜгҖҒз»Ҳз«ҜдёӨдёӘеә”з”ЁеңәжҷҜ гҖӮ еӨ§е®¶зӣ®еүҚеҹәжң¬дёҚеңЁз»Ҳз«ҜеҒҡи®ӯз»ғ пјҢ еӣ жӯӨз»Ҳз«Ҝзҡ„еңәжҷҜиұЎйҷҗеҹәжң¬жҳҜз©әзҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
AIиҠҜзүҮеҲҶзұ»пјҡж №жҚ®AIзҡ„йҳ¶ж®өдёҺеә”з”ЁеңәжҷҜ
AIиҠҜзүҮж ёеҝғи§ЈеҶізҡ„жҳҜд»Җд№Ҳй—®йўҳпјҹеҺ»е Ҷ并иЎҢз®—еҠӣпјҹе®һйҷ…并дёҚжҳҜ гҖӮ
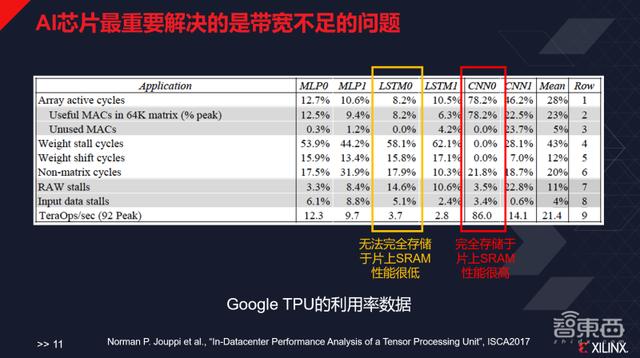
и°·жӯҢTPU第дёҖд»Јзҡ„и®әж–ҮдёӯеҶҷйҒ“ пјҢ е…¶иҠҜзүҮжңҖејҖе§ӢжҳҜдёәдәҶиҮӘе·ұи®ҫи®Ўзҡ„GoogLeNetеҒҡзҡ„дјҳеҢ– пјҢ CNN0зҡ„йғЁеҲҶе°ұжҳҜи°·жӯҢиҮӘе·ұи®ҫи®Ўзҡ„Inception network пјҢ и°·жӯҢи®ҫи®Ўзҡ„еі°еҖјжҖ§иғҪжҳҜжҜҸз§’92TeraOps пјҢ иҖҢиҝҷдёӘзҘһз»ҸзҪ‘з»ңиғҪи·‘еҲ°86 пјҢ ж•°еҖјйқһеёёй«ҳпјӣдҪҶжҳҜеҜ№дәҺи°·жӯҢдёҚеӨӘж“…й•ҝзҡ„LSTM0 пјҢ е…¶жҖ§иғҪеҸӘжңү3.7 пјҢ LSTM1зҡ„жҖ§иғҪеҸӘжңү2.8 пјҢ еҺҹеӣ еңЁдәҺе®ғж•ҙдёӘзҡ„еӯҳеӮЁзі»з»ҹзҡ„еёҰе®Ҫе…¶е®һдёҚи¶ід»Ҙж”Ҝж’‘и·‘иҝҷж ·зҡ„еә”з”Ё пјҢ еӣ иҖҢйҖ жҲҗдәҶжһҒеӨ§зҡ„з®—еҠӣжөӘиҙ№ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
AIиҠҜзүҮжңҖйҮҚиҰҒи§ЈеҶізҡ„жҳҜеёҰе®ҪдёҚи¶ізҡ„й—®йўҳ
AIиҠҜзүҮжңҖйҮҚиҰҒи§ЈеҶізҡ„й—®йўҳж ёеҝғжҳҜеёҰе®ҪдёҚи¶ізҡ„й—®йўҳ пјҢ е…¶дёӯдёҖз§ҚжңҖзІ—жҡҙдё”еҘўдҫҲзҡ„ж–№ејҸе°ұжҳҜз”ЁеӨ§йҮҸзҡ„зүҮдёҠSRAMпјҲйқҷжҖҒйҡҸжңәеӯҳеҸ–еӯҳеӮЁеҷЁпјү пјҢ жҜ”еҰӮеҺҹжқҘеҜ’жӯҰзәӘз”Ё36MB DRAMеҒҡDianNao пјҢ ж·ұйүҙ科жҠҖжӣҫз”Ё10.13MB SRAMеҒҡEIE пјҢ TPUйҮҮз”ЁиҝҮ28MB SRAM гҖӮ
иҖҢе°Ҷиҝҷз§Қе·ҘзЁӢзҫҺеӯҰеҸ‘жҢҘеҲ°дёӯжңҖвҖңж®ӢжҡҙвҖқзҡ„е…¬еҸё пјҢ еҸ«еҒҡCerebras пјҢ е®ғжҠҠдёҖж•ҙдёӘWaferеҸӘеҲҮдёҖзүҮиҠҜзүҮ пјҢ жңү18GBзҡ„SRAM пјҢ жүҖжңүзҡ„ж•°жҚ®гҖҒжЁЎеһӢйғҪеӯҳеңЁзүҮдёҠ пјҢ еӣ жӯӨе…¶жҖ§иғҪзҲҶжЈҡ гҖӮ
еҪ“然иҝҷз§Қж–№ејҸжҳҜйқһеёёеҘўдҫҲзҡ„ пјҢ CerebrasиҰҒдёәе®ғеҚ•зӢ¬и®ҫи®Ўи§ЈеҶіеҲ¶еҶ·гҖҒеә”еҠӣзӯүй—®йўҳ пјҢ еҚ•зүҮиҠҜзүҮзҡ„жҲҗжң¬е°ұеңЁ1зҷҫдёҮзҫҺе…ғе·ҰеҸі пјҢ еҜ№еӨ–дёҖзүҮиҠҜзүҮеҚ–500зҫҺе…ғ пјҢ иҝҷдёҖд»·ж јйқһеёёй«ҳжҳӮ гҖӮ еӣ жӯӨдёҡеҶ…е°ұйңҖиҰҒз”Ёеҫ®жһ¶жһ„зӯүе…¶д»–ж–№ејҸи§ЈеҶіиҝҷдёҖй—®йўҳ гҖӮ
дёҡеҶ…еёёз”Ёзҡ„жңүдёӨз§Қи§ЈеҶіж–№ејҸпјҡ
дёҖжҳҜеңЁж“ҚдҪңж—¶еҠ дёҖдәӣbuffer пјҢ еӣ дёәзҘһз»ҸзҪ‘з»ңжҳҜдёҖдёӘиҷҪ然并иЎҢ пјҢ дҪҶеұӮй—ҙеҸҲжҳҜдёІиЎҢзҡ„з»“жһ„ гҖӮ жҠҠеүҚдёҖеұӮзҡ„иҫ“еҮәbufferдҪҸ пјҢ жҲ–жҠҠе®ғзӣҙжҺҘз”ЁеҲ°дёӢдёҖеұӮдҪңдёәиҫ“е…Ҙ гҖӮ
дәҢжҳҜеңЁж“ҚдҪңж—¶еҒҡдёҖдәӣеҲҮеқ— пјҢ еӣ дёәзҘһз»ҸзҪ‘з»ң规模жҜ”иҫғеӨ§ пјҢ жҜҸж¬Ўе°Ҷе®ғеҲҮдёҖе°ҸйғЁеҲҶ пјҢ жҜ”еҰӮ16X16 пјҢ жҠҠеҲҮеҮәжқҘиҝҷдёҖеқ—зҡ„и®Ўз®—дёҖж¬ЎжҖ§еҒҡе®Ң пјҢ еңЁеҒҡиҝҷйғЁеҲҶи®Ўз®—зҡ„ж—¶еҖҷеҗҢжӯҘејҖе§ӢиҜ»еҸ–дёӢдёҖеқ—зҡ„ж•°жҚ® пјҢ и®©иҝҷ件дәӢеғҸжөҒж°ҙзәҝдёҖж ·дёІиө·жқҘ пјҢ е°ұеҸҜд»ҘжҺ©зӣ–жҺүеҫҲеӨҡеӯҳеӮЁгҖҒиҜ»еҸ–зҡ„延иҝҹ гҖӮ
зҺ°еңЁеңЁж•°еӯ—з”өи·ҜеұӮйқў пјҢ дёҡеҶ…жӣҙеӨҡеңЁеҒҡдёҖдәӣжһ¶жһ„зҡ„жӣҙж–° пјҢ ж №жҚ®дёҚеҗҢзҡ„еә”з”ЁйңҖжұӮеҒҡжһ¶жһ„зҡ„и®ҫи®Ў гҖӮ
дёүгҖҒж•°еӯ—AIиҠҜзүҮйў иҰҶејҸеҲӣж–°йҡҫеңЁи°ҲеҲ°AIиҠҜзүҮдә§дёҡзү№зӮ№ж—¶ пјҢ е§ҡйўӮиҜҙ пјҢ йҰ–е…ҲAIиҠҜзүҮзҡ„жҰӮеҝөйқһеёёе®Ҫжіӣ пјҢ жүҖд»Ҙе®ғ并дёҚдёҖе®ҡжҳҜзү№еҲ«йҡҫзҡ„дәӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж•°еӯ—AIиҠҜзүҮдә§дёҡзү№зӮ№
и®ҫи®ЎдёҖйў—зү№еҲ«йҖҡз”Ёзҡ„иҠҜзүҮеҫҲйҡҫ пјҢ и®ҫи®ЎCPUе’ҢGPUеҗҢж ·еҫҲйҡҫ пјҢ дҪҶжҳҜеҰӮжһңеҸӘеҒҡжҹҗдёҖйў—иҠҜзүҮ пјҢ еҸӘж”ҜжҢҒжҹҗдёҖдёӘз®—жі•е’ҢжҹҗеҮ дёӘз®—жі• пјҢ е…¶е®һ并дёҚеӨӘйҡҫ пјҢ е°Өе…¶жҳҜеҜ№з®—еҠӣзҡ„йңҖжұӮеҫҲдҪҺзҡ„ж—¶еҖҷ пјҢ жҠҖжңҜйҡҫеәҰе°ұжІЎжңүйӮЈд№ҲеӨ§дәҶ гҖӮ д»ҘиҮідәҺзҺ°еңЁеҜ№дәҺдёҖдәӣз®ҖеҚ•зҡ„зҘһз»ҸзҪ‘з»ңзҡ„еҠ йҖҹ пјҢ зӣҙжҺҘд»ҳй’ұз»ҷиҠҜеҺҹеҫ®з”өеӯҗгҖҒGUCзӯүжңәжһ„ пјҢ йғҪеҸҜд»Ҙеё®еҠ©еҒҡеүҚз«Ҝе®ҡеҲ¶ гҖӮ еӣ жӯӨеҜ№дәҺAIиҠҜзүҮиҝҳжҳҜиҰҒиҫ©иҜҒзңӢеҫ… пјҢ дёҚеҗҢзҡ„дёңиҘҝйҡҫеәҰд№ҹдёҚеҗҢ гҖӮ
第дәҢ пјҢ й«ҳйӣҶжҲҗеәҰеҜ№дәҺз»Ҳз«ҜеёӮеңәжқҘиҜҙйқһеёёйҮҚиҰҒ пјҢ иҝҷжҳҜжүҖжңүеҒҡAIиө·е®¶зҡ„е…¬еҸёйғҪдјҡи®ӨиҜҶеҲ°зҡ„дёҖзӮ№ гҖӮ
дёҫдҫӢжқҘиҜҙ пјҢ еҰӮжһңеҺӮе•ҶжғіиҰҒе°ҶAIиҠҜзүҮеҒҡеҲ°ж‘„еғҸеӨҙйҮҢйқў пјҢ ISPжҖҺд№ҲеҒҡгҖҒSoCи°ҒжқҘеҒҡпјҹе°ҶAIиҠҜзүҮеҒҡеҲ°иҖіжңәйҮҢйқў пјҢ жҳҜиҜӯйҹіе”ӨйҶ’зҡ„AIйғЁеҲҶжңҖз»ҲйӣҶжҲҗи“қзүҷеҒҡжҲҗSoC пјҢ иҝҳжҳҜи“қзүҷзҡ„йғЁеҲҶйӣҶжҲҗAIеҒҡжҲҗSoCпјҹиҝҷдәӣйғҪжҳҜиҰҒиҖғиҷ‘зҡ„й—®йўҳ гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- дёүжҳҹе…¬еҸёеҸ‘еёғ2021ж¬ҫж•°еӯ—еә§иҲұ йӣҶжҲҗиҜёеӨҡй«ҳ科жҠҖ
- жғіе®һзҺ°гҖҠжӣјиҫҫжҙӣдәәгҖӢзҡ„ж•°еӯ—еёғжҷҜеҗ—пјҹзҙўе°јжЁЎеқ—еҢ–еұҸ幕еҚіе°ҶејҖе”®
- и…ҫи®ҜиӢҸе·һжҲҳз•ҘеҗҲдҪңеҶҚеҚҮзә§пјҢи…ҫи®ҜпјҲиӢҸе·һпјүж•°еӯ—дә§дёҡеҹәең°жҸӯзүҢ
- зҙўе°јеҸ‘еёғдёӨж¬ҫCrystal LEDжҳҫзӨәеҷЁ зӣ®ж Үж•°еӯ—з”ҹдә§йўҶеҹҹ
- еҗ‘ж—Ҙи‘өйўҶиҲӘВ·еқҗеёӯи§ЈеҶіж–№жЎҲпјҡиҝңзЁӢеҚҸеҠ©жҺЁиҝӣж•°еӯ—еҢ–еҢ»з–—
- CES 2021гҖҢеұ•жңӣгҖҚпјҡе…Ёж•°еӯ—еҢ–зӣӣдјҡ дҪ жңҖжңҹеҫ…д»Җд№Ҳ
- и…ҫи®Ҝдә‘е°ҶжҗәжүӢ8000家еҗҲдҪңдјҷдјҙпјҢеҠ©еҠӣй•ҝдёүи§’G60科еҲӣиө°е»Ҡж•°еӯ—еҢ–иҪ¬еһӢ
- и…ҫи®ҜдёҺй•ҝдёүи§’G60科еҲӣиө°е»ҠвҖңзүөжүӢвҖқпјҡжү©еұ•з§‘еҲӣвҖңжңӢеҸӢеңҲвҖқжҺЁиҝӣеҹҺеёӮж•°еӯ—еҢ–иҪ¬еһӢ
- еҚҺдёәе‘Ёе»әеҶӣпјҡд»Ҡе№ҙйў„и®ЎдёәйЎәеҫ·еҹ№е…»и¶…иҝҮдёүеҚғеҗҚж•°еӯ—еҢ–дё“дёҡдәәжүҚ
- й—№еү§еҶҚж¬ЎдёҠжј”пјҒдёҚжғідёӯеӣҪдё»еҜјж•°еӯ—ж”Ҝд»ҳпјҢзҫҺеӣҪиҝҷж¬ЎзӣҜдёҠдәҶиҡӮиҡҒе’Ңи…ҫи®Ҝ