不需要负样本对的SOTA的自监督学习方法:BYOL( 二 )
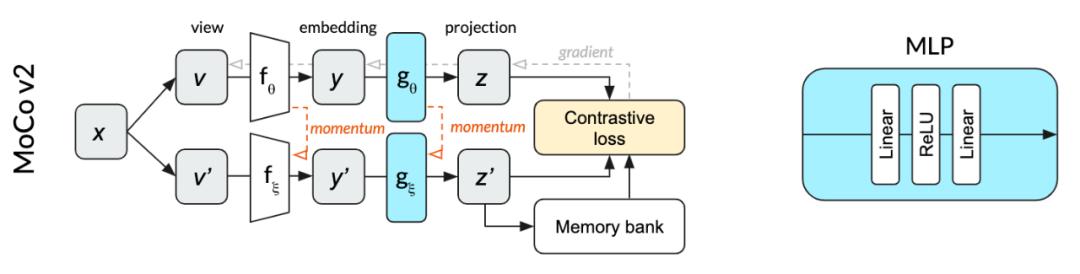
online network参数为θ , 和momentum network参数ξ 。 online network采用随机梯度下降法进行更新 , momentum network采用online network的指数移动平均法进行更新 。 online network允许MoCo将之前的投影放入memory bank中以进行高效的利用 , 并作为对比损失的负样本 。 这个memory bank支持更小的batch size 。 在我们的狗图像的示意图中 , 正样本是同一副狗的图像的不同的crops , 负样本是在过去的mini-batch中使用过的完全不同的图像 , 这些图像存储在memory bank中 。
在MoCo v2中用于投影的MLP不使用batch normalization 。
 文章插图
文章插图
MoCo v2 结构 , 上面是online编码器 , 下面是momentum编码器
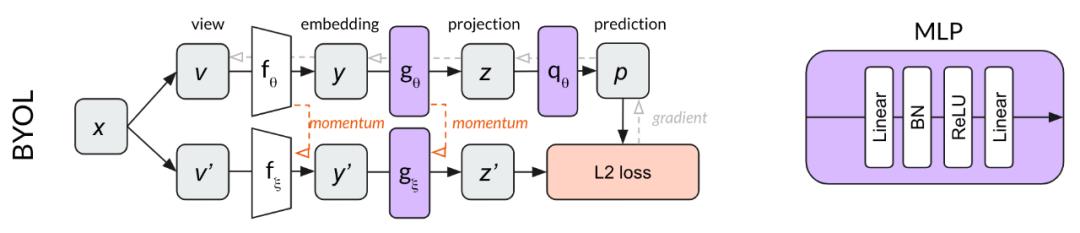
BYOLBYOL建立在MoCo的momentum network概念上 , 增加了一个MLP(qθ) , 用来从z中预测z ' , 而不是使用对比损失 , BYOL使用了L2来计算归一化预测p和目标z '之的误差 。 以我们的狗图像为例 , BYOL尝试将狗图像的两种crop转换为相同的表示向量(使p和z '相等) 。 因为这个损失函数不需要负样本 , 所以BYOL中不需要使用memory bank 。
BYOL中的两个MLPs只在第一个线性层之后使用batch normalization 。
 文章插图
文章插图
BYOL结构
根据上面的描述 , BYOL似乎可以在不明确地对比多个不同图像的情况下学习 。 然而 , 令人惊讶的是 , 我们发现BYOL不仅在做对比学习 , 而且对比学习对它的成功是必不可少的 。
我们的结果我们最初使用为MoCo编写的代码在PyTorch中实现了BYOL 。 当我们开始训练我们的网络时 , 我们发现我们的网络的表现并不比random好 。 将我们的代码与[另一个实现:进行了比较 , 我们发现MLP中缺少了batch normalization 。 我们很惊讶batch normalization化对于BYOL的训练是至关重要的 , 而MoCo v2根本不需要它 。
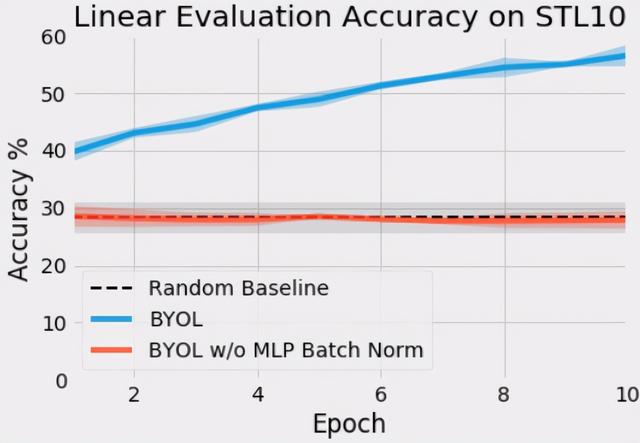
对于我们的初始测试 , 我们使用带有动量的SGD , batchsize为256的STL-10无监督数据集训练了一个使用BYOL的ResNet-18 。 下面是在MLPs中使用和不使用batch normalization的同一个BYOL算法的前10个epochs的训练 。
 文章插图
文章插图
在STL10上ResNet-18的早期训练中验证集的精度基本是线性的 。 在MLP中不进行批处理归一化的BYOL训练时 , 其性能并不比随机基线好 。
为什么会这样?为了调查性能发生这种戏剧性变化的原因 , 我们执行了一些额外的实验 。
 文章插图
文章插图
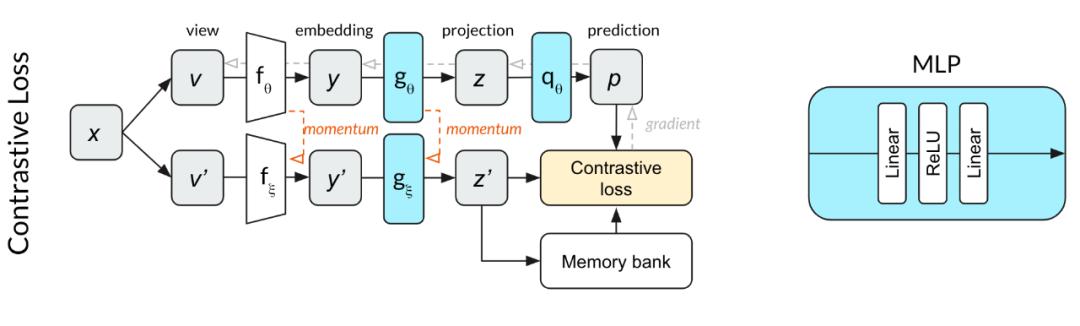
使用对比损失的实验配置 , 更好的和BYOL结果进行比较
因为与MoCo相比预测的MLP q改变了网络深度 , 我们想知道是否需要batch normalization来规范这个网络 。 也就是说 , 虽然MoCo不需要batch normalization , 但是当与额外的预测MLP q配对时 , MoCo可能需要batch normalization 。 为了测试这一点 , 我们开始用一个对比损失函数来训练上面的网络 。 我们发现 , 在10个epoch内 , 该网络的性能明显优于随机网络 。 这个结果让我们怀疑没有使用对比损失函数会导致训练依赖于batch normalization 。
然后 , 我们想知道另一种类型的规范化是否会有同样的效果 。 我们对MLPs应用了Layer Normalization而不是batch normalization , 并使用BYOL对网络进行了训练 。 在MLPs未进行归一化的实验中 , 其性能并不比随机的好 。 这个结果告诉我们 , 在同一个小batch中激活其他输入对于帮助BYOL找到有用的表示是至关重要的 。
推荐阅读


















- 雷军签名版小米11曝光:绝对的理财产品
- 扫码枪将钱扫走,却不需要密码,安全吗?
- 松山湖科学城打造美好生活样本
- 下沉市场不需要巨头,但很需要社区团购
- 为何谷歌、脸书都热衷黑客马拉松?百度的选择或许是对的
- “朋友圈”寻人只需8小时,互联网需要正能量,不需要巨头卖菜
- leetcode哈希表之好数对的数目
- 毕亚兹Type-C拓展坞评测:不买贵的只买对的,四口足矣
- 实战经验:电商平台遭遇CC攻击,我们是如何应对的?
- 中科院强势介入,ASML妥协:DUV光刻机出口不需要美国授权