图解|什么是高并发利器NoSQL( 三 )
 文章插图
文章插图
LevelDB具有很高的随机写 , 顺序读/写性能 , 因此LevelDB很适合应用在写多读少的场景 , 真让人好奇高性能的随机写怎么做到的 。
5.1.1 LSM树
很多数据在逻辑上相近 , 但是在物理存储上却可能相隔很远 , 这样就会造成大量的随机读写问题 , 从而降低性能 。
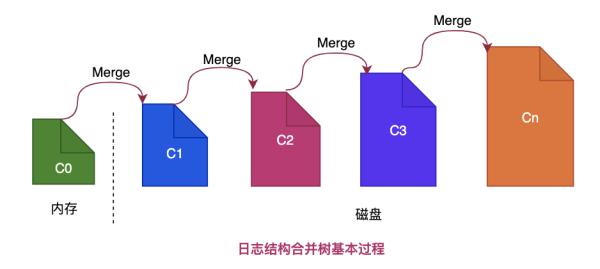
LevelDB实现高性能随机写的秘密武器在于使用LSM树存储结构 , LSM树又称为日志结构合并树(Log-Structured Merge-Tree) , 它并不是具体的数据结构 , 而是一种设计思想 。
LSM树对于每次写入操作 , 并不是直接将最新的数据驻留在磁盘中 , 而是将数据先放在内存 。
当内存数据达到一定的阈值 , 再将这部分数据真正刷新到磁盘文件中 , 从而将磁盘随机写转换为内存顺序写 , 因而获得了极高的写性能 , 但是这种机制会降低读的性能 , 总体来说降低部分读性能来大幅提升写性能是值得的 。
 文章插图
文章插图
5.1.2 LevelDB整体架构
 文章插图
文章插图
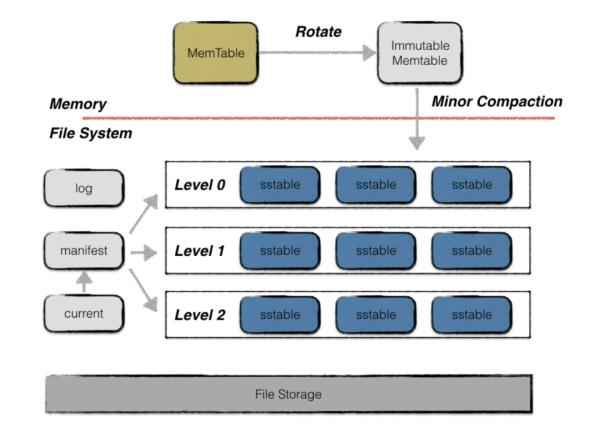
LevelDB 存储结构主要由六个部分组成:
- MemTable:内存数据结构 , 使用SkipList实现 , 新的数据修改会首先在这里写入 , 并且有容量限制 。
- Immutable MemTable:待落盘的数据库内存结构 , 当 MemTable的大小达到设定的阈值时 , 会变成 Immutable MemTable , 只接受读操作 , 不再接受写操作 , 后续会Flush到磁盘上 。
- SST Files:Sorted String Table Files , 磁盘数据存储文件 , 分为 Level0 到 LevelN 多层 , 每一层包含多个 SST 文件 , 文件内数据有序 。
- Manifest Files:leveldb元信息清单文件 。 Manifest记录 SST 文件在不同 Level 的分布 , 相当于SST文件的索引 。
- Current File:当前正在使用的文件清单文件 。
5.2 脸书出品RocksDB
青出于蓝而胜于蓝 。
RocksDB在LevelDB的基础上进行了改进和优化 , 也成为后续很多NoSQL所选择的存储引擎 。
RocksDB仍然是采用C++开发的 , 并且完全向后兼容了LevelDB的接口 , 可以说是个平滑升级 。
5.2.1 RocksDB提升点
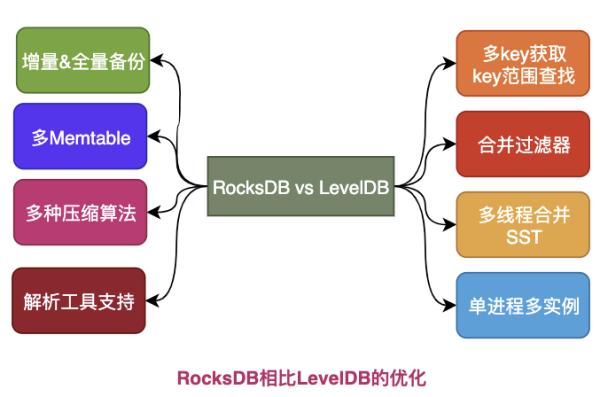
来看看RocksDB做了哪些优化和提升:
- RocksDB支持一次获取多个Key , 还支持Key范围查找 , LevelDB只能获取单个Key 。
- RocksDB支持多线程合并 , 而LevelDB是单线程合并的 , 多核时代前者效率更高 。
- RocksDB增加了合并时过滤器 , 对不符合条件的Key进行丢弃 。
- RocksDB可采用多种压缩算法 , 除了LevelDB用的snappy , 还有zlib、bzip2 。
- RocksDB支持增量备份和全量备份 。
 文章插图
文章插图5.2.2 RocksDB整体架构
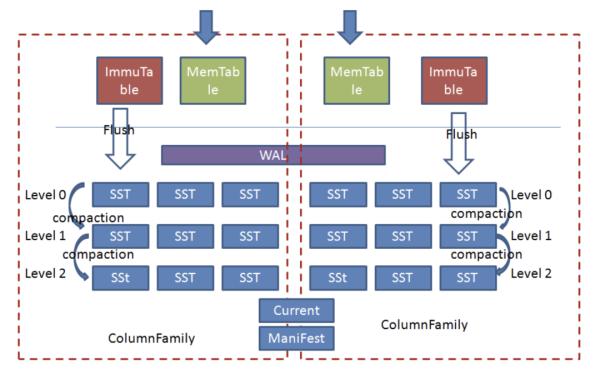
Rocksdb中引入了Column Family(列族的概念 , 所谓列族也就是一系列kv组成的数据集 , 所有的读写操作都需要先指定列族 。
每个ColumnFamily有自己的Memtable ,SST文件 , 所有ColumnFamily共享WAL、Current、Manifest文件 。
 文章插图
文章插图如果说LevelDB是个平民版的NoSQL存储引擎 , 那么RocksDB绝对是尊享版 , 所以很多优秀的NoSQL成品都是基于RocksDB来封装上层协议和代理支持完成的 。
推荐阅读














![[火星]火星有座奥林匹斯山,如果搬到地球,估计没人能爬到峰顶](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/588e44cac7127eef7b786c7914d9347f.jpg)

- 黑鲨4pro什么时候出多少钱,黑鲨4pro价格参数介绍
- 为什么有"iphone是穷人手机"的言论?用万元机的人真穷吗
- 极速鲨课堂89:主板名字带WIFI和不带有什么区别
- 比起007,996真的是福报!互联网大厂为什么加班都这么狠?
- vivo追求的本原设计是什么?X60 Pro给出了答案
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 近期浙江引来这么多重磅级“帮手”传递什么信号?
- 都是为自己手机代言,为什么董明珠不行,雷军太行了?
- 有没有必要给老年人买台智能手机?
- 玩转光追大作最低需要什么配置?快来看小狮子的推荐