「爬虫四步走」手把手教你使用Python抓取并存储网页数据( 二 )
在上面的代码中 , 我们先使用soup.select('li.rank-item') , 此时返回一个list包含每一个视频信息 , 接着遍历每一个视频信息 , 依旧使用CSS选择器来提取我们要的字段信息 , 并以字典的形式存储在开头定义好的空列表中 。
可以注意到我用了多种选择方法提取去元素 , 这也是select方法的灵活之处 , 感兴趣的读者可以进一步自行研究 。
第四步:存储数据
【「爬虫四步走」手把手教你使用Python抓取并存储网页数据】通过前面三步 , 我们成功的使用requests+bs4从网站中提取出需要的数据 , 最后只需要将数据写入Excel中保存即可 。
如果你对pandas不熟悉的话 , 可以使用csv模块写入 , 需要注意的是设置好编码encoding='utf-8-sig' , 否则会出现中文乱码的问题
import csvkeys = all_products[0].keyswith open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)如果你熟悉pandas的话 , 更是可以轻松将字典转换为DataFrame , 一行代码即可完成
import pandas as pdkeys = all_products[0].keyspd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')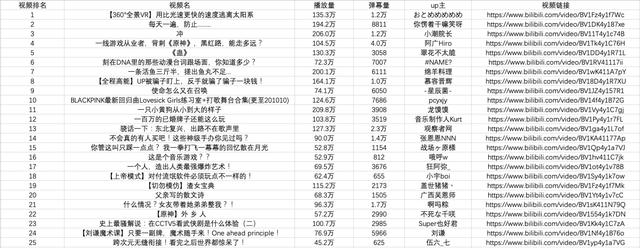 文章插图
文章插图
小结
至此我们就成功使用Python将b站热门视频榜单数据存储至本地 , 大多数基于requests的爬虫基本都按照上面四步进行 。
不过虽然看上去简单 , 但是在真实场景中每一步都没有那么轻松 , 从请求数据开始目标网站就有多种形式的反爬、加密 , 到后面解析、提取甚至存储数据都有很多需要进一步探索、学习 。
本文选择B站视频热榜也正是因为它足够简单 , 希望通过这个案例让大家明白爬虫的基本流程 , 最后附上完整代码
import requestsfrom bs4 import BeautifulSoupimport csvimport pandas as pdurl = ''page = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')all_products = products = soup.select('li.rank-item')for product in products:rank = product.select('div.num')[0].textname = product.select('div.info > a')[0].text.stripplay = product.select('span.data-box')[0].textcomment = product.select('span.data-box')[1].textup = product.select('span.data-box')[2].texturl = product.select('div.info > a')[0].attrs['href']all_products.append({"视频排名":rank,"视频名": name,"播放量": play,"弹幕量": comment,"up主": up,"视频链接": url})keys = all_products[0].keyswith open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:dict_writer = csv.DictWriter(output_file, keys)dict_writer.writeheaderdict_writer.writerows(all_products)### 使用pandas写入数据pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')end
这么长你都读完了 , 你真是个爱学习的好孩子!为了奖励你 , 我决定把Python书以最便宜的价格卖给你!比京东淘宝都便宜 , 而且还能累加使用优惠券!尽量不让经济问题 , 耽误你的学习 。 来 , 领券学习吧 , 少年!
 文章插图
文章插图
推荐阅读














- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 手把手配置HLS流媒体服务器
- 手把手教学的腕上私教!华为WATCH FIT评测:功能无憾的旗舰方表
- 微信发视频还能添加文字?原来方法这么简单,手把手教你学会
- 史上最全Python反爬虫方案汇总
- 华为手机内存不够用?手把手教你2个方法,立马多出几十个G
- Python爬虫实战案例:采集爱奇艺VIP视频
- 手把手教你进行Go语言环境安装及相关VSCode配置
- 爱了!Guide哥手把手教你搭建一个文档类型的网站!免费且高速
- 手把手教你用 KODI tMM 打造家庭观影系统