зҹҘиҜҶи’ёйҰҸж–№жі•зҡ„жј”иҝӣеҺҶеҸІз»јиҝ°( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
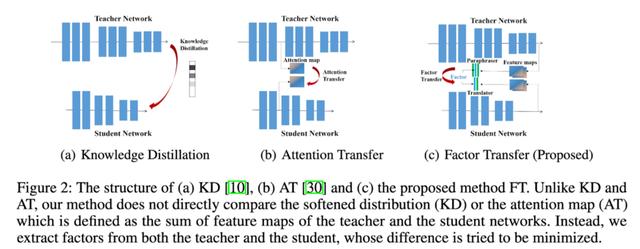
他们еңЁжЁЎеһӢдёӯеўһеҠ дәҶеҸҰдёҖдёӘжЁЎеқ— пјҢ 他们称д№Ӣдёәparaphraser гҖӮ е®ғеҹәжң¬дёҠжҳҜдёҖдёӘдёҚеҮҸе°‘е°әеҜёзҡ„иҮӘзј–з ҒеҷЁ гҖӮ д»ҺжңҖеҗҺдёҖеұӮејҖе§Ӣ пјҢ 他们еҸҲеҲҶеҮәеҸҰеӨ–дёҖеұӮз”ЁдәҺreconstruction loss гҖӮ
еӯҰз”ҹжЁЎеһӢдёӯиҝҳжңүеҸҰдёҖдёӘеҗҚдёәtranslatorзҡ„жЁЎеқ— гҖӮ е®ғжҠҠеӯҰз”ҹжЁЎеһӢзҡ„жңҖеҗҺдёҖеұӮзҡ„иҫ“еҮәеөҢе…ҘеҲ°иҖҒеёҲзҡ„paraphraserз»ҙеәҰдёӯ гҖӮ 他们用иҖҒеёҲжҪңеңЁзҡ„paraphrased иЎЁзӨәдҪңдёәhints гҖӮ
еӯҰз”ҹжЁЎеһӢеә”иҜҘиғҪеӨҹдёәжқҘиҮӘж•ҷеёҲзҪ‘з»ңзҡ„иҫ“е…Ҙжһ„йҖ дёҖдёӘиҮӘзј–з ҒеҷЁзҡ„иЎЁзӨә гҖӮ
AComprehensive Overhaul of Feature DistillationеңЁ2019е№ҙ пјҢ A Comprehensive Overhaul of Feature DistillationеҸ‘еёғдәҺICCV 2019 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
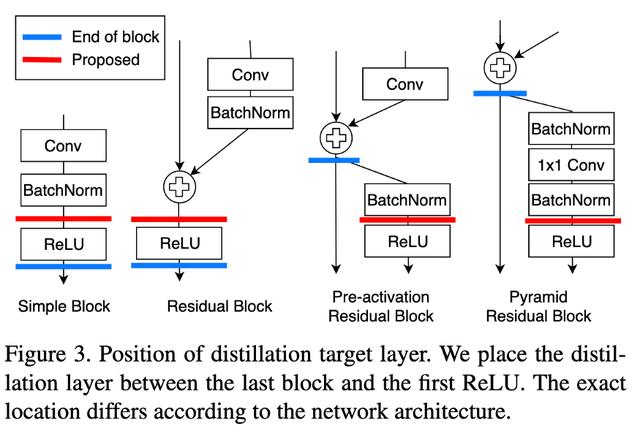
他们и®ӨдёәжҲ‘们иҺ·еҸ–hintsзҡ„дҪҚзҪ®дёҚжҳҜжңҖдҪізҡ„ гҖӮ йҖҡиҝҮReLUеҜ№иҫ“еҮәиҝӣиЎҢз»ҶеҢ– пјҢ еңЁиҪ¬жҚўиҝҮзЁӢдёӯдјҡдёўеӨұдёҖдәӣдҝЎжҒҜ гҖӮ 他们жҸҗеҮәдәҶmarginReLUжҝҖжҙ»еҮҪж•°(移дҪҚзҡ„ReLU) гҖӮ вҖңеңЁжҲ‘们зҡ„margin ReLU пјҢ з§ҜжһҒзҡ„(жңүзӣҠзҡ„)дҝЎжҒҜиў«дҪҝз”ЁиҖҢжІЎжңүд»»дҪ•ж”№еҸҳ пјҢ иҖҢж¶ҲжһҒзҡ„(дёҚеҲ©зҡ„)дҝЎжҒҜиў«еҺӢеҲ¶ гҖӮ з»“жһңиЎЁжҳҺ пјҢ иҜҘж–№жі•еҸҜд»ҘеңЁдёҚйҒ—жјҸжңүзӣҠдҝЎжҒҜзҡ„жғ…еҶөдёӢиҝӣиЎҢи’ёйҰҸ гҖӮ вҖң
他们йҮҮз”ЁдәҶpartial L2 distanceеҮҪж•° пјҢ зӣ®зҡ„жҳҜи·іиҝҮеҜ№иҙҹеҢәеҹҹдҝЎжҒҜзҡ„и’ёйҰҸ гҖӮ (еҰӮжһңиҜҘдҪҚзҪ®зҡ„еӯҰз”ҹе’ҢиҖҒеёҲзҡ„зү№еҫҒеҗ‘йҮҸйғҪжҳҜиҙҹзҡ„ пјҢ еҲҷжІЎжңүжҚҹеӨұ)
Contrastive Representation DistillationеҸ‘иЎЁдәҺICLR 2020 гҖӮ еңЁиҝҷйҮҢ пјҢ еӯҰз”ҹд№ҹд»Һж•ҷеёҲзҡ„дёӯй—ҙиЎЁзӨәиҝӣиЎҢеӯҰд№ пјҢ дҪҶдёҚжҳҜйҖҡиҝҮMSEжҚҹеӨұ пјҢ 他们дҪҝз”ЁдәҶеҜ№жҜ”жҚҹеӨұ гҖӮ
жҖ»зҡ„жқҘиҜҙ пјҢ иҝҷдәӣдёҚеҗҢзҡ„жЁЎеһӢйҮҮз”ЁдәҶдёҚеҗҢзҡ„ж–№жі•
- еўһеҠ и’ёйҰҸдёӯдј йҖ’дҝЎжҒҜзҡ„йҮҸ гҖӮ (зү№еҫҒиЎЁзӨәгҖҒGramзҹ©йҳөгҖҒжіЁж„ҸеҠӣеӣҫгҖҒParaphrasedиЎЁзӨәгҖҒpre-ReLUзү№еҫҒ)
- йҖҡиҝҮи°ғж•ҙжҚҹеӨұеҮҪж•° пјҢ дҪҝи’ёйҰҸиҝҮзЁӢжӣҙжңүж•Ҳ(еҜ№жҜ”жҚҹеӨұ пјҢ partial L2 distance)
- KDзҡ„Gramзҹ©йҳө = Neural Style Transfer + KD
- KDзҡ„жіЁж„ҸеҠӣеӣҫ = Attention is all you need + KD
- ParaphrasedиЎЁзӨә KD = Autoencoder + KD
- ContrastiveиЎЁзӨәи’ёйҰҸ = InfoNCE + KD
- GANs for KD(еҚіж”№еҸҳзү№еҫҒиЎЁзӨәд№Ӣй—ҙзҡ„GANжҚҹеӨұзҡ„еҜ№жҜ”жҚҹеӨұ)
- ејұзӣ‘зқЈKD(Self-Training with Noisy Student Improves ImageNet classification)
жӣҙеӨҡеҶ…е®№ пјҢ иҜ·е…іжіЁеҫ®дҝЎе…¬дј—еҸ·вҖңAIе…¬еӣӯвҖқ гҖӮ
жҺЁиҚҗйҳ…иҜ»












- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- еҚҺдёәдә‘зҹҘиҜҶи®Ўз®—и§ЈеҶіж–№жЎҲиҺ·йҰ–жү№вҖңзҹҘиҜҶеӣҫи°ұдә§е“Ғи®ӨиҜҒиҜҒд№ҰвҖқ
- дјҒдёҡ|жҠҖжңҜеҝ«йҖҹиҝӯд»ЈеҖ’йҖјзҹҘиҜҶдә§жқғвҖңиҙҙиә«вҖқжңҚеҠЎпјҢдёҠжө·йҰ–家AIе•Ҷж Үе“ҒзүҢжҢҮеҜјз«ҷе…Ҙй©»еҫҗжұҮиҘҝеІё
- е°Ҹзұі11еұҸ幕зҝ»иҪҰеҸ‘з»ҝжҖҺд№ҲеӣһдәӢ еұҸ幕问йўҳжЈҖжөӢж–№жі•д»Ӣз»Қ
- иҷҫзұійҹід№җжӯҢеҚ•еҸҜеҜје…ҘQQйҹід№җгҖҒзҪ‘жҳ“дә‘йҹід№җ ж–№жі•иҝҷ
- 1дёӘжүӢжңәжҖҺд№Ҳзҷ»еҪ•2дёӘеҫ®дҝЎпјҹж–№жі•еҫҲз®ҖеҚ•пјҢзңӢе®ҢжҲ‘еӯҰдјҡдәҶ
- еҺҹжқҘеҚҺдёәжүӢжңәжӢҚи§Ҷйў‘иҝҳиғҪж·»еҠ еӯ—幕пјҢж–№жі•еҫҲз®ҖеҚ•пјҢдёҖеӯҰе°ұдјҡ
- еҺҹжқҘеҚҺдёәжүӢжңәйҡҗи—Ҹжү«жҸҸд»ӘпјҢ3з§Қж–№жі•пјҢзәёиҙЁжЎЈеҮ з§’з”өеӯҗеҢ–пјҢдёҖеӯҰе°ұдјҡ
- жүӢжңәз…§зүҮгҖҒи§Ҷйў‘жҖҺж ·ж·»еҠ ж–Үеӯ—пјҹеҺҹжқҘеҫҲз®ҖеҚ•пјҢ4з§Қж–№жі•дёҖеҲҶй’ҹжҗһе®ҡ
- жүӢжңәеҚЎйЎҝж—¶пјҢ究з«ҹжҳҜе…іжңәиҝҳжҳҜйҮҚеҗҜпјҢиҝҷеӣӣзӮ№е·®ејӮжҳҺжҳҫпјҢзңӢе®Ңж¶ЁзҹҘиҜҶдәҶ