зҹҘиҜҶи’ёйҰҸж–№жі•зҡ„жј”иҝӣеҺҶеҸІз»јиҝ°
дҪңиҖ…пјҡNishant Nikhil
зј–иҜ‘пјҡronghuaiyang
еҜјиҜ»
еёҰдҪ еӣһйЎҫзҹҘиҜҶи’ёйҰҸзҡ„6зҜҮж–Үз« пјҢ дәҶи§ЈзҹҘиҜҶи’ёйҰҸзҡ„жј”иҝӣеҺҶеҸІ гҖӮ
еҺҶеҸІ2012е№ҙ пјҢ AlexNetеңЁImageNetж•°жҚ®дёҠзҡ„иЎЁзҺ°и¶…иҝҮдәҶжүҖжңүзҺ°жңүжЁЎеһӢ гҖӮ зҘһз»ҸзҪ‘з»ңеҚіе°Ҷиў«е№ҝжіӣйҮҮз”Ё гҖӮ еҲ°2015е№ҙ пјҢ и®ёеӨҡSOTAйғҪиў«жү“з ҙдәҶ гҖӮ дёҡз•Ңзҡ„и¶ӢеҠҝжҳҜеңЁдҪ иғҪжүҫеҲ°зҡ„д»»дҪ•еңәжҷҜдёҠйғҪдҪҝз”ЁзҘһз»ҸзҪ‘з»ң гҖӮ VGG Netзҡ„жҲҗеҠҹиҝӣдёҖжӯҘиӮҜе®ҡдәҶйҮҮз”ЁеҸҜд»ҘдҪҝз”Ёжӣҙж·ұеұӮж¬ЎжЁЎеһӢжҲ–жЁЎеһӢйӣҶжҲҗжқҘжҸҗй«ҳжҖ§иғҪ гҖӮ
(жЁЎеһӢйӣҶеҗҲеҸӘжҳҜдёҖдёӘиҠұе“Ёзҡ„жңҜиҜӯ гҖӮ е®ғж„Ҹе‘ізқҖеҜ№еӨҡдёӘжЁЎеһӢзҡ„иҫ“еҮәиҝӣиЎҢе№іеқҮ гҖӮ жҜ”еҰӮ пјҢ еҰӮжһңжңүдёүдёӘжЁЎеһӢ пјҢ дёӨдёӘжЁЎеһӢйў„жөӢзҡ„жҳҜвҖңAвҖқ пјҢ иҖҢдёҖдёӘжЁЎеһӢйў„жөӢзҡ„жҳҜвҖңBвҖқ пјҢ йӮЈд№Ҳе°ұжҠҠжңҖз»Ҳзҡ„йў„жөӢдҪңдёәвҖңAвҖқ(дёӨзҘЁеҜ№дёҖзҘЁ)) гҖӮ
дҪҶжҳҜиҝҷдәӣжӣҙж·ұеұӮж¬Ўзҡ„жЁЎеһӢе’ҢжЁЎеһӢзҡ„йӣҶеҗҲиҝҮдәҺжҳӮиҙө пјҢ ж— жі•еңЁжҺЁзҗҶиҝҮзЁӢдёӯиҝҗиЎҢ гҖӮ (3дёӘжЁЎеһӢзҡ„йӣҶжҲҗдҪҝз”Ёзҡ„и®Ўз®—йҮҸжҳҜеҚ•дёӘжЁЎеһӢзҡ„3еҖҚ) гҖӮ
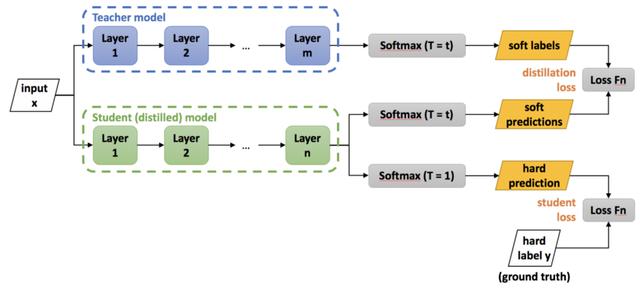
жҖқжғіGeoffrey Hinton, Oriol Vinyalsе’ҢJeff DeanжғіеҮәдәҶдёҖдёӘзӯ–з•Ҙ пјҢ еңЁиҝҷдәӣйў„е…Ҳи®ӯз»ғзҡ„йӣҶжҲҗжЁЎеһӢзҡ„жҢҮеҜјдёӢи®ӯз»ғжө…еұӮжЁЎеһӢ гҖӮ 他们称其дёәзҹҘиҜҶи’ёйҰҸ пјҢ еӣ дёәдҪ е°ҶзҹҘиҜҶд»ҺдёҖдёӘйў„е…Ҳи®ӯз»ғеҘҪзҡ„жЁЎеһӢдёӯжҸҗеҸ–еҲ°дёҖдёӘж–°зҡ„жЁЎеһӢдёӯ гҖӮ иҝҷе°ұеғҸжҳҜиҖҒеёҲеңЁжҢҮеҜјеӯҰз”ҹ пјҢ жүҖд»Ҙд№ҹиў«з§°дёәеёҲз”ҹеӯҰд№ пјҡ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁзҹҘиҜҶи’ёйҰҸдёӯ пјҢ 他们дҪҝз”Ёйў„и®ӯз»ғжЁЎеһӢзҡ„иҫ“еҮәжҰӮзҺҮдҪңдёәж–°зҡ„жө…еұӮжЁЎеһӢзҡ„ж Үзӯҫ гҖӮ йҖҡиҝҮиҝҷзҜҮж–Үз« пјҢ дҪ еҸҜд»ҘдәҶи§ЈеҲ°иҝҷйЎ№жҠҖжңҜзҡ„жј”иҝӣ гҖӮ
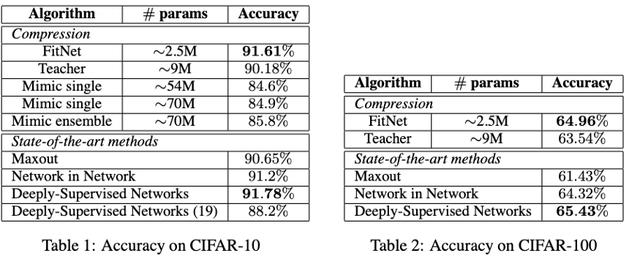
Fitnets2015е№ҙеҮәзҺ°дәҶFitNets: hint for Thin Deep Nets(еҸ‘еёғдәҺICLR'15)йҷӨдәҶKDзҡ„жҚҹеӨұ пјҢ FitNetsиҝҳеўһеҠ дәҶдёҖдёӘйҷ„еҠ йЎ№ гҖӮ е®ғ们д»ҺдёӨдёӘзҪ‘з»ңзҡ„дёӯзӮ№иҺ·еҸ–иЎЁзӨә пјҢ 并еңЁиҝҷдәӣзӮ№зҡ„зү№еҫҒиЎЁзӨәд№Ӣй—ҙеўһеҠ еқҮж–№жҚҹеӨұ гҖӮ
з»ҸиҝҮи®ӯз»ғзҡ„зҪ‘з»ңжҸҗдҫӣдәҶдёҖз§Қж–°зҡ„еӯҰд№ -дёӯй—ҙ-иЎЁзӨәи®©ж–°зҡ„зҪ‘з»ңеҺ»жЁЎд»ҝ гҖӮ иҝҷдәӣиЎЁзӨәжңүеҠ©дәҺеӯҰз”ҹжңүж•Ҳең°еӯҰд№ пјҢ иў«з§°дёәhints гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
FitNetиғҪеӨҹеҺӢзј©жЁЎеһӢ пјҢ еҗҢж—¶дҝқжҢҒеҮ д№ҺзӣёеҗҢзҡ„жҖ§иғҪ
еӣһиҝҮеӨҙзңӢзңӢ пјҢ дҪҝз”ЁеҚ•зӮ№з»ҷеҮәhintsзҡ„йҖүжӢ©дёҚжҳҜжңҖдјҳзҡ„ гҖӮ йҡҸеҗҺзҡ„и®ёеӨҡи®әж–ҮйғҪиҜ•еӣҫж”№иҝӣиҝҷдәӣhints гҖӮ
Paying more attention to attentionPaying more attention to attention: Improving the performance of convolutional neural networks via Attention TransferеҸ‘еёғдәҺICLR 2017 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
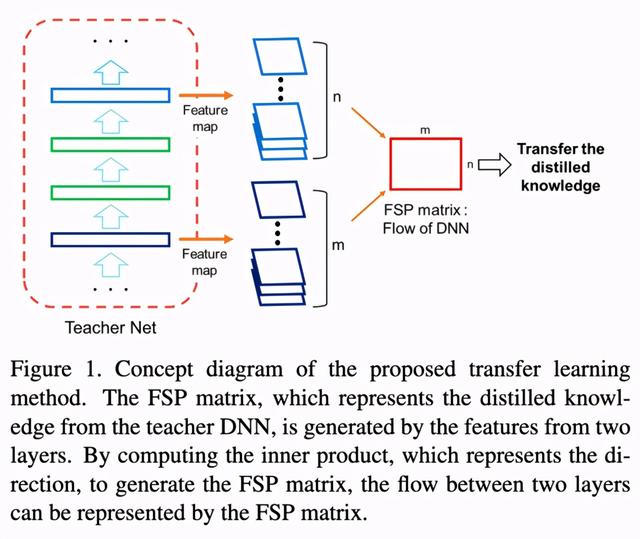
гҖҗзҹҘиҜҶи’ёйҰҸж–№жі•зҡ„жј”иҝӣеҺҶеҸІз»јиҝ°гҖ‘е®ғ们зҡ„еҠЁжңәдёҺFitNetsзұ»дјј пјҢ дҪҶе®ғ们дёҚжҳҜдҪҝз”ЁзҪ‘з»ңдёӯжҹҗдёӘзӮ№зҡ„иЎЁзӨә пјҢ иҖҢжҳҜдҪҝз”ЁжіЁж„ҸеҠӣеӣҫдҪңдёәhints гҖӮ (иҖҒеёҲе’ҢеӯҰз”ҹзҡ„жіЁж„ҸеҠӣеӣҫ) гҖӮ е®ғ们иҝҳдҪҝз”ЁзҪ‘з»ңдёӯзҡ„еӨҡдёӘзӮ№жқҘжҸҗдҫӣhints пјҢ иҖҢдёҚжҳҜFitNetsдёӯзҡ„еҚ•зӮ№hints гҖӮ
A Gift from Knowledge DistillationеҗҢе№ҙ пјҢ A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer LearningеҸ‘еёғдәҺCVPR 2017 гҖӮ
иҝҷе’ҢFitNetsе’ҢжіЁж„ҸеҠӣиҪ¬з§»зҡ„и®әж–Үд№ҹеҫҲзұ»дјј гҖӮ дҪҶжҳҜ пјҢ дёҺиЎЁзӨәе’ҢжіЁж„ҸеҠӣеӣҫдёҚеҗҢзҡ„жҳҜ пјҢ е®ғ们дҪҝз”ЁGramзҹ©йҳөз»ҷеҮәдәҶhints гҖӮ
他们еңЁи®әж–ҮдёӯеҜ№жӯӨиҝӣиЎҢдәҶзұ»жҜ”пјҡ
вҖңеҰӮжһңжҳҜдәәзұ»зҡ„иҜқ пјҢ иҖҒеёҲи§ЈйҮҠдёҖдёӘй—®йўҳзҡ„и§ЈеҶіиҝҮзЁӢ пјҢ еӯҰз”ҹеӯҰд№ и§ЈеҶій—®йўҳзҡ„иҝҮзЁӢ гҖӮ еӯҰз”ҹDNNдёҚдёҖе®ҡиҰҒеӯҰд№ е…·дҪ“й—®йўҳиҫ“е…Ҙж—¶зҡ„дёӯй—ҙиҫ“еҮә пјҢ дҪҶеҸҜд»ҘеӯҰд№ йҒҮеҲ°е…·дҪ“зұ»еһӢзҡ„й—®йўҳж—¶зҡ„жұӮи§Јж–№жі• гҖӮ йҖҡиҝҮиҝҷз§Қж–№ејҸ пјҢ жҲ‘们зӣёдҝЎжј”зӨәй—®йўҳзҡ„и§ЈеҶіиҝҮзЁӢжҜ”и®ІжҺҲдёӯй—ҙз»“жһңжҸҗдҫӣдәҶжӣҙеҘҪзҡ„жіӣеҢ– гҖӮ вҖқ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёәдәҶеәҰйҮҸиҝҷдёӘвҖңи§ЈеҶіжөҒзЁӢвҖқ пјҢ 他们еңЁдёӨдёӘеұӮзҡ„зү№еҫҒеӣҫд№Ӣй—ҙдҪҝз”ЁдәҶGramзҹ©йҳө гҖӮ еӣ жӯӨ пјҢ е®ғжІЎжңүдҪҝз”ЁFitNetsдёӯзҡ„дёӯй—ҙзү№еҫҒиЎЁзӨәдҪңдёәhints пјҢ иҖҢжҳҜдҪҝз”Ёзү№еҫҒиЎЁзӨәд№Ӣй—ҙзҡ„Gramзҹ©йҳөдҪңдёәhints гҖӮ
Paraphrasing Complex Network然еҗҺеҲ°дәҶ2018е№ҙ пјҢ Paraphrasing Complex Network: Network Compression via Factor TransferеҸ‘еёғдәҺNeurIPS 2018 гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- еҚҺдёәдә‘зҹҘиҜҶи®Ўз®—и§ЈеҶіж–№жЎҲиҺ·йҰ–жү№вҖңзҹҘиҜҶеӣҫи°ұдә§е“Ғи®ӨиҜҒиҜҒд№ҰвҖқ
- дјҒдёҡ|жҠҖжңҜеҝ«йҖҹиҝӯд»ЈеҖ’йҖјзҹҘиҜҶдә§жқғвҖңиҙҙиә«вҖқжңҚеҠЎпјҢдёҠжө·йҰ–家AIе•Ҷж Үе“ҒзүҢжҢҮеҜјз«ҷе…Ҙй©»еҫҗжұҮиҘҝеІё
- е°Ҹзұі11еұҸ幕зҝ»иҪҰеҸ‘з»ҝжҖҺд№ҲеӣһдәӢ еұҸ幕问йўҳжЈҖжөӢж–№жі•д»Ӣз»Қ
- иҷҫзұійҹід№җжӯҢеҚ•еҸҜеҜје…ҘQQйҹід№җгҖҒзҪ‘жҳ“дә‘йҹід№җ ж–№жі•иҝҷ
- 1дёӘжүӢжңәжҖҺд№Ҳзҷ»еҪ•2дёӘеҫ®дҝЎпјҹж–№жі•еҫҲз®ҖеҚ•пјҢзңӢе®ҢжҲ‘еӯҰдјҡдәҶ
- еҺҹжқҘеҚҺдёәжүӢжңәжӢҚи§Ҷйў‘иҝҳиғҪж·»еҠ еӯ—幕пјҢж–№жі•еҫҲз®ҖеҚ•пјҢдёҖеӯҰе°ұдјҡ
- еҺҹжқҘеҚҺдёәжүӢжңәйҡҗи—Ҹжү«жҸҸд»ӘпјҢ3з§Қж–№жі•пјҢзәёиҙЁжЎЈеҮ з§’з”өеӯҗеҢ–пјҢдёҖеӯҰе°ұдјҡ
- жүӢжңәз…§зүҮгҖҒи§Ҷйў‘жҖҺж ·ж·»еҠ ж–Үеӯ—пјҹеҺҹжқҘеҫҲз®ҖеҚ•пјҢ4з§Қж–№жі•дёҖеҲҶй’ҹжҗһе®ҡ
- жүӢжңәеҚЎйЎҝж—¶пјҢ究з«ҹжҳҜе…іжңәиҝҳжҳҜйҮҚеҗҜпјҢиҝҷеӣӣзӮ№е·®ејӮжҳҺжҳҫпјҢзңӢе®Ңж¶ЁзҹҘиҜҶдәҶ