йҖҡиҝҮи§Ҷйў‘зқҖиүІиҝӣиЎҢиҮӘзӣ‘зқЈи·ҹиёӘ( дёү )
йўңиүІжҳҜз©әй—ҙйў‘зҺҮеҒҸдҪҺ пјҢ жүҖд»ҘжҲ‘们еҸҜд»ҘеӨ„зҗҶдҪҺеҲҶиҫЁзҺҮзҡ„её§ гҖӮ жҲ‘们дёҚйңҖиҰҒCпјҲ255 пјҢ 3пјүйўңиүІз»„еҗҲ пјҢ жүҖд»ҘжҲ‘们еҲӣе»әдәҶ16дёӘиҒҡзұ»е№¶е°ҶйўңиүІз©әй—ҙйҮҸеҢ–дёәиҝҷдәӣиҒҡзұ» гҖӮ зҺ°еңЁжҲ‘们еҸӘжңү16з§ҚзӢ¬зү№зҡ„йўңиүІз°ҮпјҲи§ҒдёҠеӣҫ第3ж Ҹпјү гҖӮ иҒҡзұ»жҳҜз”Ёk-еқҮеҖје®ҢжҲҗзҡ„ гҖӮ 16дёӘзҫӨйӣҶдјҡжңүдёҖдәӣйўңиүІдҝЎжҒҜзҡ„дёўеӨұ пјҢ дҪҶи¶ід»ҘиҜҶеҲ«зү©дҪ“ гҖӮ жҲ‘们еҸҜд»ҘеўһеҠ иҒҡзұ»зҡ„ж•°зӣ®жқҘжҸҗй«ҳзқҖиүІзҡ„зІҫеәҰ пјҢ дҪҶд»Јд»·жҳҜеўһеҠ и®Ўз®—йҮҸ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
[жқҘжәҗпјҡ]
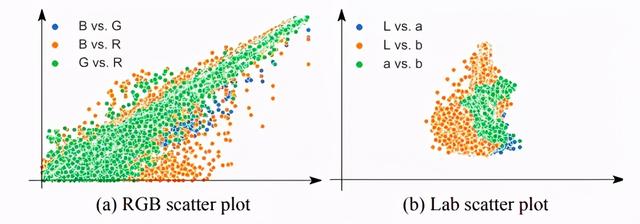
дёәдәҶе°ҶеӣҫеғҸйҮҸеҢ–жҲҗз°Ү пјҢ жҲ‘们е°ҶдҪҝз”ЁLABйўңиүІз©әй—ҙзҡ„ABйҖҡйҒ“иҖҢдёҚжҳҜRGBйўңиүІз©әй—ҙйҖҡйҒ“ гҖӮ дёҠйқўзҡ„еӣҫжҳҫзӨәдәҶRGBе’ҢLABйҖҡйҒ“й—ҙзҡ„зӣёе…іжҖ§ пјҢ д»ҺеӣҫдёӯжҲ‘们еҸҜд»Ҙеҫ—еҮәз»“и®ә
RGBеҫҖеҫҖжҜ”LABжӣҙе…·зӣёе…іжҖ§ гҖӮ
LABе°ҶејәеҲ¶жЁЎеһӢеӯҰд№ дёҚеҸҳжҖ§ пјҢ е®ғе°ҶејәеҲ¶е…¶еӯҰд№ жӣҙејәеӨ§зҡ„иЎЁзӨәеҪўејҸ пјҢ иҖҢдёҚжҳҜдҫқиө–дәҺжң¬ең°йўңиүІдҝЎжҒҜ гҖӮ
еҸҜд»ҘдҪҝз”Ёsklearnзҡ„KMeansиҪҜ件еҢ…иҝӣиЎҢиҒҡзұ» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷдёӘзұ»е°Ҷз”ЁдәҺеҲ¶дҪңйўңиүІзҡ„з°Ү пјҢ жҲ‘们е°ҶжҠҠе®ғеӯҳеӮЁдёәдёҖдёӘpickle гҖӮ
е®һзҺ°жіЁж„Ҹ:жҲ‘дҪҝз”ЁpytorchжқҘиҝӣиЎҢе®һзҺ° пјҢ е®ғйҒөеҫӘ(N, C, H, W)ж јејҸ гҖӮ еңЁеӨ„зҗҶзҹ©йҳөйҮҚеЎ‘ж—¶иҰҒи®°дҪҸиҝҷдёҖзӮ№ гҖӮ еҰӮжһңдҪ еҜ№еҪўзҠ¶жңүд»»дҪ•з–‘й—® пјҢ иҜ·йҡҸж—¶дёҺжҲ‘们иҒ”зі» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҜҘжЁЎеһӢд»ҺеҸӮиҖғеё§дёӯеӯҰд№ дёәи§Ҷйў‘её§зқҖиүІ гҖӮ [жқҘжәҗпјҡ]
иҫ“е…Ҙ
иҜҘжЁЎеһӢзҡ„иҫ“е…ҘжҳҜеӣӣдёӘзҒ°еәҰи§Ҷйў‘её§ пјҢ е…¶дёӢйҮҮж ·дёә256Г—256 гҖӮ дёүдёӘеҸӮиҖғеё§е’ҢдёҖдёӘзӣ®ж Үеё§ гҖӮ
йў„еӨ„зҗҶйҰ–е…Ҳ пјҢ жҲ‘们е°ҶжүҖжңүзҡ„и®ӯз»ғи§Ҷйў‘еҺӢзј©еҲ°6fps гҖӮ 然еҗҺйў„еӨ„зҗҶжЎҶжһ¶д»ҘеҲӣе»әдёӨдёӘдёҚеҗҢзҡ„йӣҶеҗҲ гҖӮ дёҖдёӘз”ЁдәҺCNNжЁЎеһӢ пјҢ еҸҰдёҖдёӘз”ЁдәҺзқҖиүІд»»еҠЎ гҖӮ
- Video fps is reduced to 6 fpsSET 1 - for CNN Model- Down sampled to 256 x 256- Normalise to have intensities between [-1, 1]SET 2 - for Colourization- Convert to LAB colour space- Downsample to 32 x 32- Quantize in 16 clusters using k-means- Create one-hot vector corresponding to the nearest cluster centroidжЁЎеһӢз»“жһ„жүҖз”Ёзҡ„дё»е№ІжҳҜResNet-18 пјҢ еӣ жӯӨе…¶з»“жһңдёҺе…¶д»–ж–№жі•зӣёеҪ“ гҖӮ ResNet-18зҡ„жңҖеҗҺдёҖеұӮиў«жӣҙж–°дёә32 x 32 x 256зҡ„е°әеҜёиҫ“еҮә гҖӮ ResNet-18зҡ„иҫ“еҮәйҡҸеҗҺиў«дј йҖҒеҲ°3D-ConvзҪ‘з»ң пјҢ жңҖз»Ҳиҫ“еҮәдёә32 x 32 x 64 гҖӮ пјҲдёӢйқўзҡ„д»Јз Ғеқ—жҳҫзӨәдәҶд»ҺResNet-18зҪ‘з»ңиҺ·еҸ–иҫ“е…Ҙзҡ„3DзҪ‘з»ңпјү
и®ӯз»ғи®ӯз»ғеҸҜеҲҶдёәд»ҘдёӢ3дёӘжӯҘйӘӨпјҡ
1. зҪ‘з»ңдј йҖ’
жҲ‘们е°ҶдҪҝз”ЁSET 1зҡ„йў„еӨ„зҗҶеё§ пјҢ еҚійҖҡиҝҮзҪ‘з»ңдј йҖ’еӨ§е°ҸдёәпјҲ256 x 256пјүзҡ„4дёӘзҒ°еәҰеё§ пјҢ д»ҘиҺ·еҫ—е…·жңү64дёӘйҖҡйҒ“зҡ„пјҲ32 x 32пјүз©әй—ҙеӣҫ гҖӮ еҜ№дәҺпјҲ32 x 32пјүеӣҫеғҸзҡ„жҜҸдёӘеғҸзҙ пјҢ иҝҷеҸҜд»Ҙи§ЈйҮҠдёә64з»ҙеөҢе…Ҙ гҖӮ еӣ жӯӨ пјҢ жҲ‘们жңүеӣӣдёӘиҝҷж ·зҡ„еғҸзҙ зә§еөҢе…Ҙ пјҢ дёүдёӘз”ЁдәҺеҸӮиҖғеӣҫеғҸ пјҢ дёҖдёӘз”ЁдәҺзӣ®ж ҮеӣҫеғҸгҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
2. зӣёдјјеәҰзҹ©йҳө
еҲ©з”Ёиҝҷдә”дёӘеөҢе…Ҙ пјҢ жҲ‘们жүҫеҲ°дәҶеҸӮиҖғеё§е’Ңзӣ®ж Үеё§д№Ӣй—ҙзҡ„зӣёдјјзҹ©йҳө гҖӮ еҜ№дәҺзӣ®ж Үеё§дёӯзҡ„еғҸзҙ жҲ‘们е°ҶиҺ·еҫ—дёҖдёӘзӣёдјјеәҰеҖј пјҢ е…¶дёӯжүҖжңүдёүдёӘеҸӮиҖғеё§дёӯзҡ„жүҖжңүеғҸзҙ еқҮйҖҡиҝҮsoftmaxеҪ’дёҖеҢ–дёә1 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
3. ColourizationзқҖиүІеӨ„зҗҶ
жҲ‘们е°ҶдҪҝз”ЁSET 2зҡ„йў„еӨ„зҗҶеё§ пјҢ еҚіе°ҶеӣӣдёӘйҷҚйҮҮж ·дёәпјҲ32 x 32пјү并йҮҸеҢ–зҡ„её§з”ЁдәҺзқҖиүІ гҖӮ е°ҶдёүдёӘеҸӮиҖғеё§дёҺзӣёдјјеәҰзҹ©йҳөзӣёз»“еҗҲ пјҢ еҫ—еҲ°йў„жөӢзҡ„йҮҸеҢ–её§ гҖӮ жҲ‘们еҸ‘зҺ°дәҶе…·жңүйў„жөӢйўңиүІзҡ„дәӨеҸүзҶөжҚҹеӨұ пјҢ (и®°дҪҸ пјҢ жҲ‘们йҮҸеҢ–её§еҲ°16дёӘиҒҡзұ» пјҢ зҺ°еңЁжҲ‘们жңү16дёӘзұ»еҲ« гҖӮ жҲ‘们еҸ‘зҺ°еңЁиҝҷдәӣйўңиүІдёҠжңүеӨҡзұ»дәӨеҸүзҶөжҚҹеӨұ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- ж–°дё“еҲ©жҳҫзӨәиӢ№жһңеңЁжңӘжқҘеҸҜиғҪи®©Apple WatchйҖҡиҝҮдј ж„ҹеҷЁжөӢйҮҸиЎҖеҺӢ
- и§Ҷйў‘е°ҸзҷҪ们зҡ„еӨ–жҢӮиЈ…еӨҮпјҡзҷҫи§ҶжӮҰR5зӣ‘и§ҶеҷЁ+T2жҸҗиҜҚеҷЁеҘ—иЈ…дёҠжүӢ
- iPhoneжҠҳеҸ еұҸиҰҒжқҘпјҹдёӨз§Қи®ҫи®ЎйҖҡиҝҮеҲқжӯҘжөӢиҜ•
- LGеұ•зӨәе…ЁзҗғйҰ–ж¬ҫйҖҡиҝҮEyesafeи®ӨиҜҒзҡ„з”өи§ҶжҳҫзӨәеұҸ
- жҸҗжЎҲйҖҡиҝҮпјҡFedora 34й»ҳи®ӨеҗҜз”Ёsystemd-oomd
- еӨ–еӘ’пјҡиӢ№жһңдёӨж¬ҫеҸҜжҠҳеҸ iPhoneж ·е“ҒйҖҡиҝҮеҜҢеЈ«еә·з¬¬дёҖйЎ№иҙЁйҮҸжЈҖжөӢ
- е……еҖј|APPдјҡе‘ҳе……еҖјйңҖжіЁж„ҸиҝҷдёүзӮ№
- еҺҹжқҘеҚҺдёәжүӢжңәжӢҚи§Ҷйў‘иҝҳиғҪж·»еҠ еӯ—幕пјҢж–№жі•еҫҲз®ҖеҚ•пјҢдёҖеӯҰе°ұдјҡ
- дёүжҳҹGalaxy A52 5GйҖҡиҝҮ3Cи®ӨиҜҒ ж”ҜжҢҒжңҖй«ҳ15Wеҝ«йҖҹе……з”ө
- и°·жӯҢеҸҜиғҪдјҡйҖҡиҝҮдёҚжӣҙж–°iOSеә”з”ЁжқҘ规йҒҝиӢ№жһңзҡ„йҡҗз§ҒжҠ«йңІ