йҖҡиҝҮи§Ҷйў‘зқҖиүІиҝӣиЎҢиҮӘзӣ‘зқЈи·ҹиёӘ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
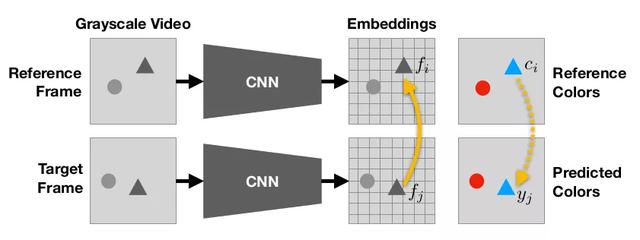
жЁЎеһӢжҺҘ收дёҖдёӘеҪ©иүІеё§е’ҢдёҖдёӘзҒ°еәҰи§Ҷйў‘дҪңдёәиҫ“е…Ҙ пјҢ 并预жөӢдёӢдёҖеё§зҡ„йўңиүІ гҖӮ жЁЎеһӢеӯҰдјҡд»ҺеҸӮиҖғзі»еӨҚеҲ¶йўңиүІ пјҢ иҝҷдҪҝеҫ—и·ҹиёӘжңәеҲ¶еҸҜд»ҘеңЁжІЎжңүдәәзұ»зӣ‘зқЈзҡ„жғ…еҶөдёӢеӯҰд№ гҖӮ [жқҘжәҗпјҡ]
жҲ‘们дёҚеӨҚеҲ¶зҪ‘з»ңдёӯзҡ„йўңиүІ пјҢ иҖҢжҳҜи®ӯз»ғжҲ‘们зҡ„CNNзҪ‘з»ңеӯҰд№ зӣ®ж Үеё§зҡ„еғҸзҙ е’ҢеҸӮиҖғеё§зҡ„еғҸзҙ д№Ӣй—ҙзҡ„зӣёдјјеәҰпјҲзӣёдјјеәҰжҳҜзҒ°еәҰеғҸзҙ д№Ӣй—ҙпјү пјҢ 然еҗҺзәҝжҖ§з»„еҗҲж—¶дҪҝз”ЁжӯӨзӣёдјјеәҰзҹ©йҳөеҸӮиҖғеё§дёӯзҡ„зңҹе®һйўңиүІдјҡз»ҷеҮәйў„жөӢзҡ„йўңиүІ гҖӮ д»Һж•°еӯҰдёҠи®І пјҢ и®ҫC?дёәеҸӮиҖғеё§дёӯжҜҸдёӘеғҸзҙ iзҡ„зңҹе®һйўңиүІ пјҢ C?дёәзӣ®ж Үеё§дёӯжҜҸдёӘеғҸзҙ jзҡ„зңҹе®һйўңиүІ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
[иө„жәҗй“ҫжҺҘпјҡ]
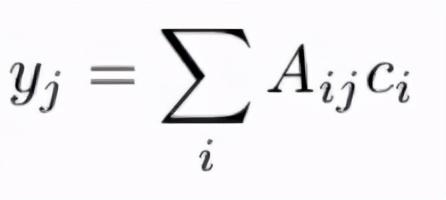 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ1пјҡйў„жөӢйўңиүІдёҺеҸӮиҖғйўңиүІзҡ„зәҝжҖ§з»„еҗҲ
еҰӮдҪ•и®Ўз®—зӣёдјјеәҰзҹ©йҳөж— и®әжҳҜеӣҫеғҸгҖҒеҸӮиҖғеё§иҝҳжҳҜзӣ®ж Үеё§йғҪз»ҸиҝҮжЁЎеһӢеӯҰд№ еҗҺеҜ№жҜҸдёӘеғҸзҙ иҝӣиЎҢдәҶдҪҺеұӮж¬Ўзҡ„еөҢе…Ҙ пјҢ иҝҷйҮҢf?жҳҜеғҸзҙ iеңЁеҸӮиҖғеё§дёӯзҡ„еөҢе…Ҙ пјҢ зұ»дјјең° пјҢ fжҳҜеғҸзҙ jеңЁзӣ®ж Үеё§дёӯзҡ„еөҢе…Ҙ гҖӮ 然еҗҺ пјҢ и®Ўз®—зӣёдјјеәҰзҹ©йҳөпјҡ
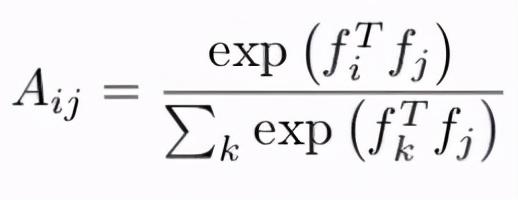 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ2пјҡз”ЁsoftmaxеҪ’дёҖеҢ–зҡ„еҶ…з§ҜзӣёдјјеәҰ
зӣёдјјзҹ©йҳөдёӯзҡ„жҜҸдёҖиЎҢиЎЁзӨәеҸӮиҖғеё§зҡ„жүҖжңүеғҸзҙ iе’Ңзӣ®ж Үеё§зҡ„еғҸзҙ jд№Ӣй—ҙзҡ„зӣёдјјжҖ§ пјҢ еӣ жӯӨдёәдәҶдҪҝжҖ»жқғйҮҚдёә1 пјҢ жҲ‘们еҜ№жҜҸдёҖиЎҢеә”з”Ёsoftmax гҖӮ
Lets look an example with dimension to make it clear,we try to find a similarity matrix of 1 pixel from target frame.An illustration of this example is shown below.Consider reference image and target image, size (5, 5) => (25,1)for each pixel, cnn gives embedding of size (64, 1), embedding for reference frame, size (64, 25), embedding for target frame, size (64, 25),embedding for 3rd pixel in target frame, size (64, 1)Similarity Matrix, between reference frame and target pixel, j=2=softmax, size (25, 64)(64, 1) => (25,1) =>(5, 5)we get a similarity between all the ref pixels and a target pixel at j=2.Colorization, To copy the color (here, colours are not RGB but quantized colour of with 1 channel) from reference frame,, Colors of reference frame size (5, 5) => (25, 1), Similarity matrix, size (5, 5) => (1, 25)Predicted color at j=2, , size (1, 25) (25, 1) => (1, 1)From the similarity matrix in below figure, we can see reference color at i=1 is dominant(0.46), thus we have a color copied for target, j=2 from reference, i=1PS:1. ? denotes transpose2. matrix indices starts from 0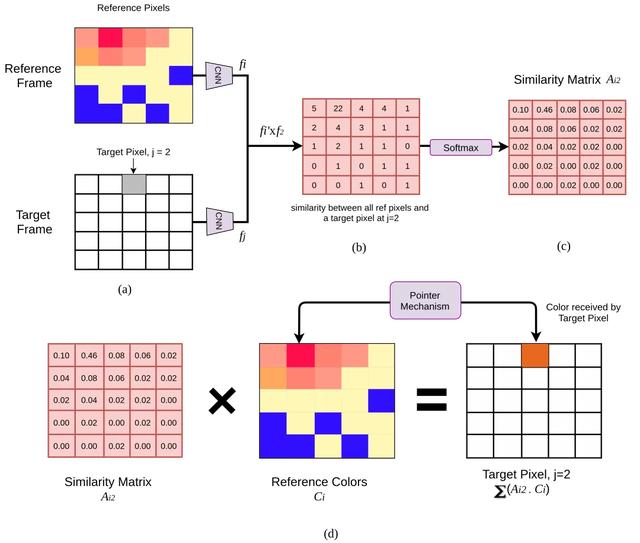 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
(a)дёә2её§еӨ§е°Ҹ(5,5) пјҢ (b)дёәеҸӮиҖғеё§еөҢе…ҘдёҺзӣ®ж ҮеғҸзҙ еңЁj =2еӨ„еөҢе…Ҙзҡ„еҶ…з§Ҝ пјҢ (c) softmaxеҗҺзҡ„зӣёдјјеәҰзҹ©йҳө пјҢ (d)зӣёдјјеәҰзҹ©йҳөдёҺеҸӮиҖғеё§зңҹйўңиүІзҡ„зәҝжҖ§з»„еҗҲ[жқҘжәҗпјҡ]
еҗҢж ·,еҜ№дәҺзӣ®ж Үеё§дёӯзҡ„жҜҸдёӘзӣ®ж ҮеғҸзҙ пјҲпјҲ5 пјҢ 5пјү=> 25дёӘеғҸзҙ пјү пјҢ жҲ‘们е°ҶдјҡжңүдёҖдёӘзӣёдјјзҹ©йҳөзҡ„еӨ§е°Ҹ(5,5),еҚіеӨ§е°ҸдёәпјҲ5 пјҢ 5 пјҢ 25пјүзҡ„е®Ңж•ҙзӣёдјјеәҰзҹ©йҳөA?? =пјҲ25 пјҢ 25пјү гҖӮ
еңЁе®һзҺ°дёӯ пјҢ жҲ‘们е°ҶдҪҝз”ЁпјҲ256 x 256пјүеӣҫеғҸжү©еұ•зӣёеҗҢзҡ„жҰӮеҝө гҖӮ
еӣҫеғҸйҮҸеҢ–
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дёҖиЎҢжҳҫзӨәеҺҹе§Ӣеё§ пјҢ 第дәҢиЎҢжҳҫзӨәжқҘиҮӘе®һйӘҢе®Өз©әй—ҙзҡ„abйўңиүІйҖҡйҒ“ гҖӮ 第дёүиЎҢе°ҶйўңиүІз©әй—ҙйҮҸеҢ–еҲ°зҰ»ж•Јзҡ„е®№еҷЁдёӯ пјҢ 并жү“д№ұйўңиүІ пјҢ дҪҝж•ҲжһңжӣҙеҠ жҳҺжҳҫ гҖӮ [жқҘжәҗпјҡ]
жҺЁиҚҗйҳ…иҜ»
















- ж–°дё“еҲ©жҳҫзӨәиӢ№жһңеңЁжңӘжқҘеҸҜиғҪи®©Apple WatchйҖҡиҝҮдј ж„ҹеҷЁжөӢйҮҸиЎҖеҺӢ
- и§Ҷйў‘е°ҸзҷҪ们зҡ„еӨ–жҢӮиЈ…еӨҮпјҡзҷҫи§ҶжӮҰR5зӣ‘и§ҶеҷЁ+T2жҸҗиҜҚеҷЁеҘ—иЈ…дёҠжүӢ
- iPhoneжҠҳеҸ еұҸиҰҒжқҘпјҹдёӨз§Қи®ҫи®ЎйҖҡиҝҮеҲқжӯҘжөӢиҜ•
- LGеұ•зӨәе…ЁзҗғйҰ–ж¬ҫйҖҡиҝҮEyesafeи®ӨиҜҒзҡ„з”өи§ҶжҳҫзӨәеұҸ
- жҸҗжЎҲйҖҡиҝҮпјҡFedora 34й»ҳи®ӨеҗҜз”Ёsystemd-oomd
- еӨ–еӘ’пјҡиӢ№жһңдёӨж¬ҫеҸҜжҠҳеҸ iPhoneж ·е“ҒйҖҡиҝҮеҜҢеЈ«еә·з¬¬дёҖйЎ№иҙЁйҮҸжЈҖжөӢ
- е……еҖј|APPдјҡе‘ҳе……еҖјйңҖжіЁж„ҸиҝҷдёүзӮ№
- еҺҹжқҘеҚҺдёәжүӢжңәжӢҚи§Ҷйў‘иҝҳиғҪж·»еҠ еӯ—幕пјҢж–№жі•еҫҲз®ҖеҚ•пјҢдёҖеӯҰе°ұдјҡ
- дёүжҳҹGalaxy A52 5GйҖҡиҝҮ3Cи®ӨиҜҒ ж”ҜжҢҒжңҖй«ҳ15Wеҝ«йҖҹе……з”ө
- и°·жӯҢеҸҜиғҪдјҡйҖҡиҝҮдёҚжӣҙж–°iOSеә”з”ЁжқҘ规йҒҝиӢ№жһңзҡ„йҡҗз§ҒжҠ«йңІ