гҖҢи§ӮеҜҹгҖҚдә‘еҺҹз”ҹж•°д»“пјҢз ҙиҢ§иҖҢеҮә( дәҢ )
жҲ‘们еҶҚд»Һж•°жҚ®зҡ„еёёи§ҒиҪҪдҪ“вҖ”ж•°жҚ®еә“еҒҡдёӢеҲҶжһҗ гҖӮ ж №жҚ®жҲ‘们常и§Ғзҡ„дёӨзұ»ж•°жҚ®еә”з”Ёж“ҚдҪңеһӢгҖҒеҲҶжһҗеһӢеҸҠж•°жҚ®з»“жһ„зү№еҫҒе…ізі»еһӢе’Ңйқһе…ізі»еһӢ пјҢ жҲ‘们е°Ҷж•°жҚ®еә“дә§е“ҒеҸҜжҢүз…§иҝҷдёӨдёӘеӣ зҙ еҒҡдёӘеҲҶзұ» гҖӮ дёӢйқўжҲ‘们йҮҚзӮ№и®Ёи®әзҡ„жҳҜе…ізі»еһӢзҡ„йқўеҜ№еҲҶжһҗеңәжҷҜзҡ„дә§е“Ғ пјҢ д№ҹе°ұжҳҜеӣҫдёӯзҡ„еҸідёҠи§’иұЎйҷҗ гҖӮ еңЁиҝҷдёҖиұЎйҷҗеҶ…зҡ„дә§е“Ғ пјҢ ж №жҚ®е…¶еҸ‘еұ•зү№зӮ№еҸҜд»Ҙз®ҖеҚ•еҲҶдёәдёӨзұ»пјҡдј з»ҹж•°жҚ®д»“еә“е’Ңдә‘(еҺҹз”ҹ)ж•°жҚ®д»“еә“ гҖӮ
- еңЁдј з»ҹж•°жҚ®д»“еә“йўҶеҹҹ пјҢ д»ҺеҸідёҠи§’еӣҫдёӯеҸҜи§Ғ пјҢ дё»иҰҒжҳҜд»ҘеӣҪеӨ–еӨ§еҺӮдёәдё» гҖӮ иҝҷйҮҢйқўеҢ…жӢ¬дәҶIBMгҖҒOracleгҖҒHPгҖҒSAPгҖҒEMCгҖҒTeraDataзӯү гҖӮ еңЁжҠҖжңҜзү№зӮ№дёҠ пјҢ жҷ®йҒҚйҮҮз”ЁдәҶMPPгҖҒеҲ—еӯҳжҠҖжңҜпјӣиҫ“еҮәеҪўжҖҒдёҠжңүзәҜиҪҜе’ҢдёҖдҪ“жңәзҡ„ж–№жЎҲ гҖӮ еҸ‘еұ•ж—¶й—ҙдёҠдё»иҰҒйӣҶдёӯеңЁ2005~2010е№ҙеүҚеҗҺ гҖӮ
- еңЁдә‘(еҺҹз”ҹ)ж•°жҚ®д»“еә“йўҶеҹҹ пјҢ д»ҺеҸідёӢи§’еҸҜи§Ғ пјҢ дё»иҰҒжҳҜд»Ҙж–°е…ҙдә‘еҺӮе•Ҷдёәдё» гҖӮ иҝҷйҮҢеҢ…жӢ¬дәҶAWSгҖҒGoogleгҖҒMicrosoftзӯүе…¬еҸёдә§е“Ғ гҖӮ е…¶жҠҖжңҜзү№зӮ№дёҠ пјҢ жҷ®йҒҚеңЁеҺҹжңүж•°д»“зҡ„жҠҖжңҜз§ҜзҙҜд№ӢдёҠ пјҢ дёҺдә‘з«ҜеҹәзЎҖзҺҜеўғз»“еҗҲ пјҢ иҫ“еҮәеҪўжҖҒдёәдә‘з«Ҝдә§е“Ғ гҖӮ еҸ‘еұ•ж—¶й—ҙдёҠдё»иҰҒйӣҶдёӯеңЁ2015~е№ҙеҗҺ гҖӮ
 ж–Үз« жҸ’еӣҫ
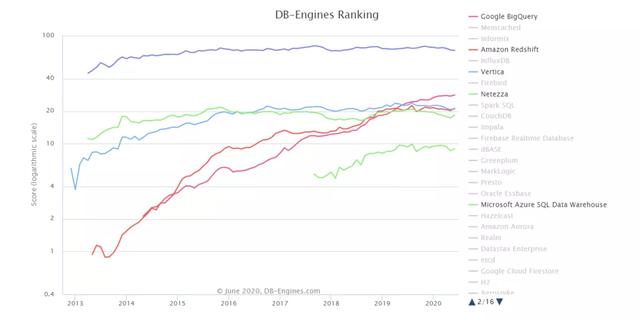
ж–Үз« жҸ’еӣҫй’ҲеҜ№дёҠиҝ°дёӨзұ»дә§е“Ғ пјҢ жҲ‘们еҒҡдёӘеҸ‘еұ•еҜ№жҜ” гҖӮ дёӢеӣҫжҳҜж №жҚ®db-enginesзҪ‘з«ҷж•°жҚ®жүҖеҫ— гҖӮ иҝҷдёҖзҪ‘з«ҷзҡ„ж•°жҚ®еә“жҺ’еҗҚ пјҢ жҳҜжҢүз…§жҗңзҙўеј•ж“ҺжҗңзҙўйҮҸ+дё»жөҒи®әеқӣи®ҝй—®йҮҸ+зӣёе…іиҒҢдҪҚжӢӣиҒҳйҮҸз»ҙеәҰ пјҢ еҸҚжҳ ж•°жҚ®еә“зҡ„еҸ—е…іжіЁзЁӢеәҰ гҖӮ дёӢеӣҫдёӯеҲ—еҮәдәҶеёёи§Ғзҡ„ж•°жҚ®еҲҶжһҗдә§е“Ғ пјҢ еҢ…жӢ¬дәҶдј з»ҹж•°д»“дә§е“ҒTeradataгҖҒVerticaпјҲHPпјүгҖҒNetezzaпјҲIBMпјүдёәд»ЈиЎЁ пјҢ дә‘ж•°д»“дә§е“ҒRedshiftпјҲAWSпјүгҖҒBigQueryпјҲGoogleпјүгҖҒADWпјҲMicrosoftпјүдёәд»ЈиЎЁ гҖӮ иҝҷдёӨзұ»дә§е“Ғзҡ„еҸ‘еұ•и¶ӢеҠҝжңүжҳҺжҳҫзҡ„е·®ејӮ гҖӮ еүҚиҖ…зҡ„еҸ‘еұ•жҜ”иҫғе№ізЁі пјҢ еҗҺиҖ…еҸ‘еұ•жӣҙдёәиҝ…йҖҹ гҖӮ дёӨиҖ…еңЁ2020е№ҙе·ҰеҸі пјҢ еңЁеұҖйғЁдә§е“ҒдёҠе·Із»ҸеҮәзҺ°зҡ„дәӨеҸү гҖӮ д№ҹе°ұжҳҜиҜҙ пјҢ еңЁиҝҷдёҖе№ҙдёҠ пјҢ еҜ№ж–°е…ҙж•°д»“дә§е“Ғзҡ„е…іжіЁзЁӢеәҰ пјҢ е·Ій«ҳдәҺжҹҗдәӣдј з»ҹж•°д»“дә§е“Ғ гҖӮ
03 з”ЁжҲ·еңәжҷҜеҸҠйңҖжұӮеҸҳеҢ–
 ж–Үз« жҸ’еӣҫ
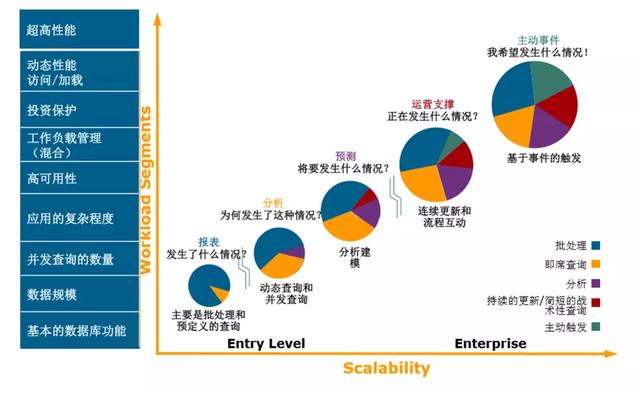
ж–Үз« жҸ’еӣҫгҖҗгҖҢи§ӮеҜҹгҖҚдә‘еҺҹз”ҹж•°д»“пјҢз ҙиҢ§иҖҢеҮәгҖ‘д»Һе®ўжҲ·зҡ„дҪҝз”ЁеңәжҷҜжқҘзңӢ пјҢ д№ҹеҰӮдёҠеӣҫз»ҸиҝҮдәҶйҳ¶ж®ө гҖӮ
- вҖңжҠҘиЎЁвҖқйҳ¶ж®ө
- вҖңеҲҶжһҗвҖқйҳ¶ж®ө
- вҖңйў„жөӢвҖқйҳ¶ж®ө
- вҖңиҝҗиҗҘж”Ҝж’‘вҖқйҳ¶ж®ө
жҺЁиҚҗйҳ…иҜ»
















- зҪ‘жҳ“ж•°еёҶдә®зӣёдёӯеҸ°жҲҳз•ҘеӨ§дјҡпјҢи§ЈиҜ»дә‘еҺҹз”ҹиҪҜ件з”ҹдә§еҠӣе®һи·ө
- жҢәеҚҺдёәпјҒзҲұз«ӢдҝЎCEOиў«жӣқвҖңеЁҒиғҒвҖқз‘һе…ёж”ҝеәң
- Bз«Ҝпјҡдә§дёҡдә’иҒ”зҪ‘зҡ„з»ҲжһҒеҘҘд№ү
- еҚҺдёәе…ЁйқўдёӢжһ¶и…ҫи®ҜжёёжҲҸпјҡи…ҫи®ҜеҚ•ж–№йқўе°ұеҗҲдҪңеҒҡеҮәйҮҚеӨ§еҸҳжӣҙ
- еүҚзһ»зү©иҒ”зҪ‘дә§дёҡе…Ёзҗғе‘ЁжҠҘ第72жңҹпјҡи…ҫи®Ҝдә‘еҸ‘еёғе…«ж¬ҫдә‘еҺҹз”ҹзі»еҲ—дә§е“ҒпјҢйҳҝйҮҢеҸ‘еёғејҖжәҗйҮҸеӯҗжЁЎжӢҹеҷЁвҖңеӨӘз« 2.0вҖқ
- ж•ҙеҗҲйӣ¶д»Јз Ғ+AI+дә‘еҺҹз”ҹжҠҖжңҜпјҢгҖҢйҖҹдјҳдә‘гҖҚеёғеұҖжҷәж…§ж•ҷеҹ№е’Ңжҷәж…§зӨҫеҢә
- дә‘еҺҹз”ҹиҝҺжқҘиҪ¬жҠҳзӮ№пјҢеҚҺдёәдә‘еҰӮдҪ•иөӢиғҪж–°дә‘еҺҹз”ҹдјҒдёҡ
- з”ЁдәҶиҝҷд№ҲеӨҡе№ҙiPhoneпјҡ第дёҖж¬Ўжү“ејҖеҺҹз”ҹзҡ„科еӯҰи®Ўз®—еҷЁ
- Rancher+SUSEпјҢеҰӮдҪ•еҸ©ејҖдә‘еҺҹз”ҹеӨ§й—Ёпјҹ
- зҷҫеәҰ|з§°йҒӯзҷҫеәҰе‘ҳе·ҘиҙҙвҖңеӨ§еӯ—жҠҘвҖқиҜӢжҜҒпјҢзҷҫеәҰж— еӣһеә”