爱可可AI论文推介(10月17日)( 二 )
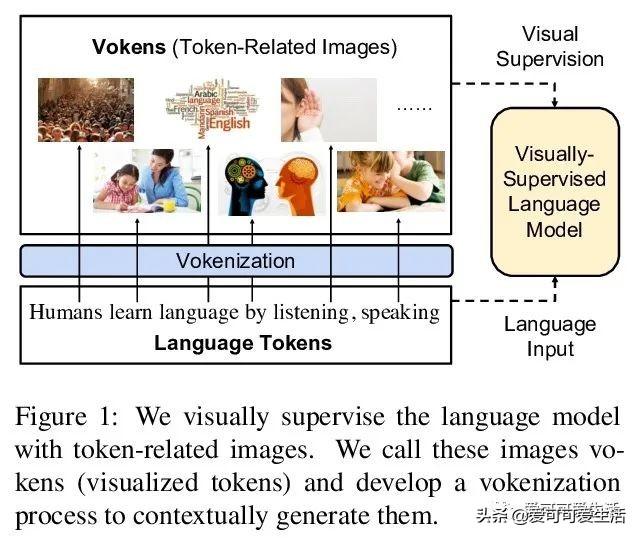 文章插图
文章插图
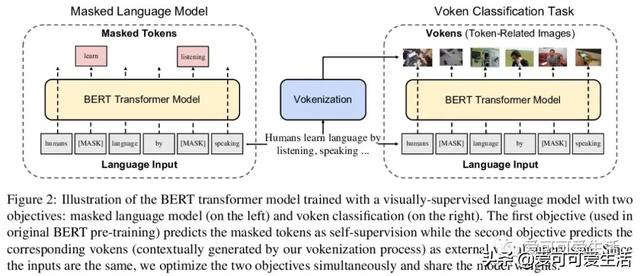 文章插图
文章插图
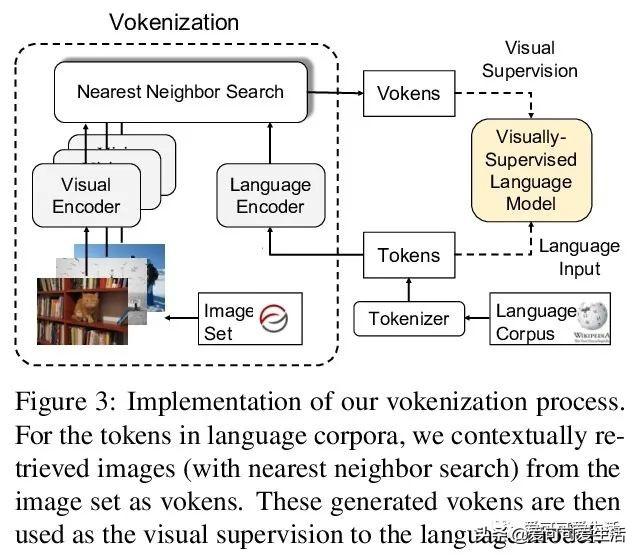 文章插图
文章插图
 文章插图
文章插图
3、[CL]*Learning Adaptive Language Interfaces through Decomposition
S Karamcheti, D Sadigh, P Liang
[Stanford University]
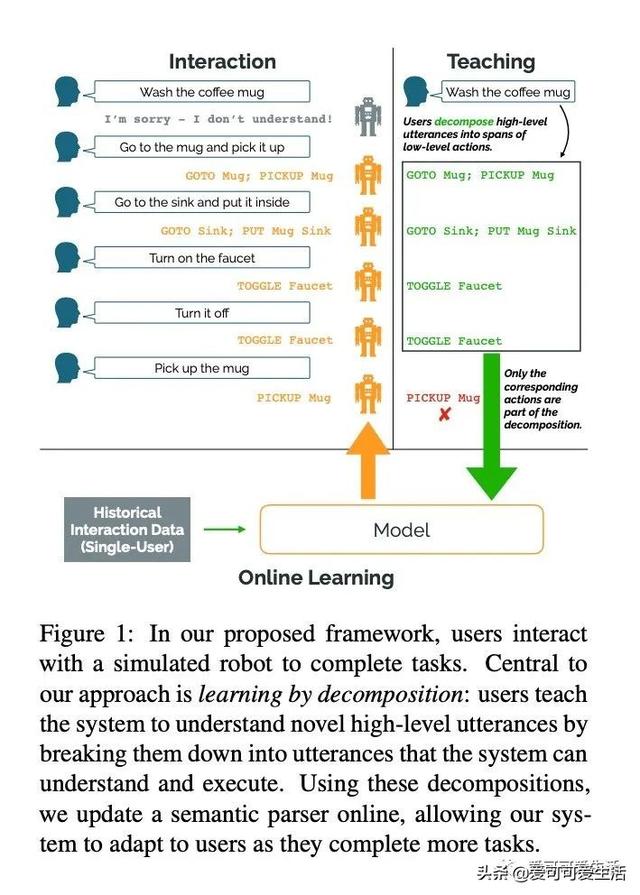
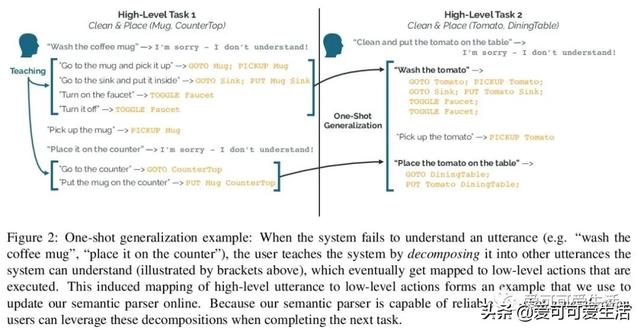
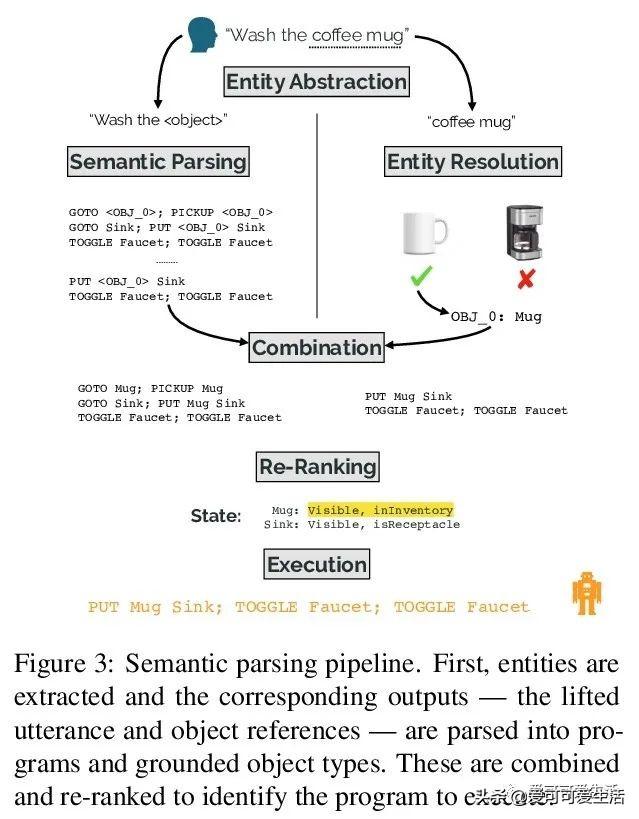
基于抽象和分解的交互式自然语言界面 , 其目标是有效且可靠地从真实的人类用户交互中学习 , 以完成模拟机器人设置中的任务 。 引入神经语义解析系统 , 可通过分解来学习新的高级抽象:用户通过交互将描述新行为的高级指令分解成系统可以理解的低级步骤来教授系统 。
Our goal is to create an interactive natural language interface that efficiently and reliably learns from users to complete tasks in simulated robotics settings. We introduce a neural semantic parsing system that learns new high-level abstractions through decomposition: users interactively teach the system by breaking down high-level utterances describing novel behavior into low-level steps that it can understand. Unfortunately, existing methods either rely on grammars which parse sentences with limited flexibility, or neural sequence-to-sequence models that do not learn efficiently or reliably from individual examples. Our approach bridges this gap, demonstrating the flexibility of modern neural systems, as well as the one-shot reliable generalization of grammar-based methods. Our crowdsourced interactive experiments suggest that over time, users complete complex tasks more efficiently while using our system by leveraging what they just taught. At the same time, getting users to trust the system enough to be incentivized to teach high-level utterances is still an ongoing challenge. We end with a discussion of some of the obstacles we need to overcome to fully realize the potential of the interactive paradigm.
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
4、[CV] MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking
P Dendorfer, A O?ep, A Milan, K Schindler, D Cremers, I Reid, S Roth, L Leal-Taixé
[Technical University Munich & Amazon Research & ETH Zurich & The University of Adelaide]
单摄像头多目标跟踪基准MOTChallenge , 包含约35,000帧的连续镜头和近700,000个已进行标注的行人 , 相比之前版本 , 不仅显著增加了标记框数量 , 还为行人以外的多种对象类提供了标签 , 以及每个兴趣对象的可见度级别 。 文中还提供了最先进跟踪器的分类和广泛的错误分析 。
Standardized benchmarks have been crucial in pushing the performance of computer vision algorithms, especially since the advent of deep learning. Although leaderboards should not be over-claimed, they often provide the most objective measure of performance and are therefore important guides for research. We present MOTChallenge, a benchmark for single-camera Multiple Object Tracking (MOT) launched in late 2014, to collect existing and new data, and create a framework for the standardized evaluation of multiple object tracking methods. The benchmark is focused on multiple people tracking, since pedestrians are by far the most studied object in the tracking community, with applications ranging from robot navigation to self-driving cars. This paper collects the first three releases of the benchmark: (i) MOT15, along with numerous state-of-the-art results that were submitted in the last years, (ii) MOT16, which contains new challenging videos, and (iii) MOT17, that extends MOT16 sequences with more precise labels and evaluates tracking performance on three different object detectors. The second and third release not only offers a significant increase in the number of labeled boxes but also provide labels for multiple object classes beside pedestrians, as well as the level of visibility for every single object of interest. We finally provide a categorization of state-of-the-art trackers and a broad error analysis. This will help newcomers understand the related work and research trends in the MOT community, and hopefully shred some light into potential future research directions.
推荐阅读












![[青鸣体育]是目前NBA里中距离最准的球星,卡哇伊莱昂纳德的中投到底有多准?](https://imgcdn.toutiaoyule.com/20200323/20200323072039113605a_t.jpeg)


![[耶叔看世界]大部分没有屋顶,被巨石压了数百年,世界上最有压力村子](https://imgcdn.toutiaoyule.com/20200412/20200412074149393124a_t.jpeg)
![[陶哲轩]8岁男孩智商超过爱因斯坦,高考成绩高达760分,如今发展怎样了?](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/upload/2020/2ea4cc39af39805900dffbbe8a562466.jpg)
- 谷歌:想发AI论文?请保证写的是正能量
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 2019年度中国高质量国际科技论文数排名世界第二
- 谷歌通过启动敏感话题审查来加强对旗下科学家论文的控制
- Arxiv网络科学论文摘要11篇(2020-10-12)
- 聚焦城市治理新方向,5G+智慧城市推介会在长举行
- 中国移动5G新型智慧城市全国推介会在长沙举行
- 年年都考的数字鸿沟有了新进展?彭波老师的论文给出了解答!
- 打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
- 爱可可AI论文推介(10月9日)