惠普Z8 G4工作站评测:中小型AI模型训练“神器”( 二 )
由于强大的处理器性能 , 因此对整机的散热功能提出了挑战 。 HP Z8 G4工作站为每颗处理器都配备了高压风扇散热排 , 其整机前部和顶部也有多个出风口 , 后部则有一个大风扇和小风扇用于吸风 , 可以在保障高性能工作的基础上依然保持一个较低的温度 。 相比于以前用的电脑主机 , 没有烫手的温度 , 也没有“蒸桑拿”式的感受 。 在出风口处只有淡淡的暖风 , 并且没有风扇高速旋转的噪音 , 完全满足了室内工作环境安静的需求 。
二、在深度学习模型训练上的表现介绍完HP Z8 G4工作站的一些关键参数和散热表现后 , 下面给大家上“主菜” 。
目前AI领域最成熟的技术可能就是计算机视觉了 , 因此也有着很多人开始转入计算机视觉相关的研发工作 。 而计算机视觉领域中 , 图像分类和目标检测是两个最基本任务 , 也是每一个计算机视觉研发人员必须要掌握的技能 。 下面就这两个任务 , 我将进行深度学习模型的训练 , 来实际看看HP Z8 G4工作站的性能到底如何 。
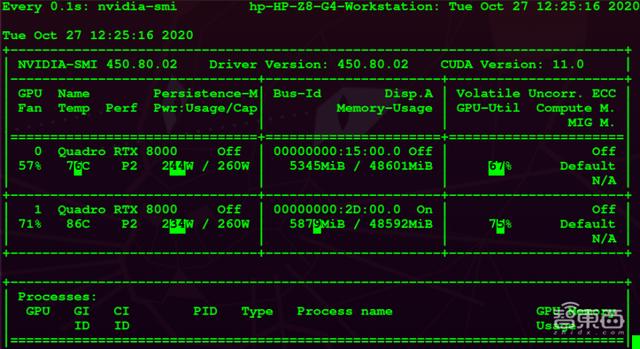
1、基本的环境配置和参数根据NVIDIA官网的推荐 , 针对NVIDIA Quadro RTX 8000我选取了450版本的驱动进行了安装 , 并安装了相应版本的CUDA 11.0 , 实现对GPU计算调用加速 。 在Linux下可以通过命令NVIDIA-SMI看GPU驱动以及CUDA版本信息 。 如下图所示 。
 文章插图
文章插图
通过CUDA自带的案例程序 , 也可以测试并查看一些基本的计算参数 , 如:
- – CUDA核心数目
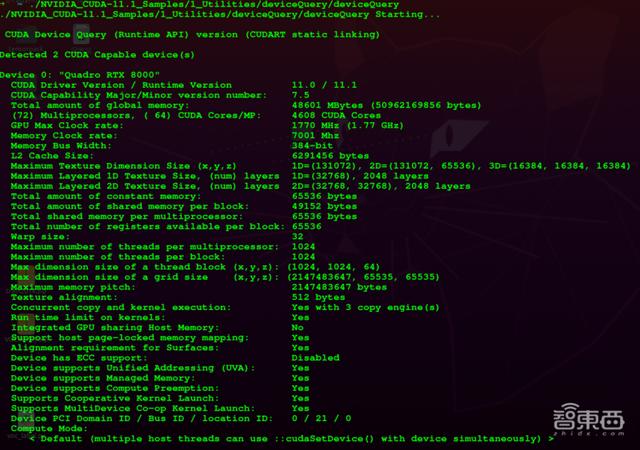 文章插图
文章插图从图中的输出的信息来看 , CUDA核心数目为4608个 , 同时提供48601MB的存储器 , 1.77GHZ的最大频率和7001MHZ的显卡频率 。
- – 浮点计算能力
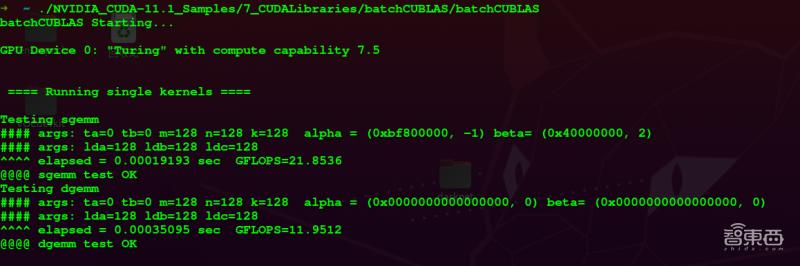 文章插图
文章插图- – 单精度浮点运算
文章插图2、图像分类与目标检测模型的训练(1)基于CIFAR-10和ImageNet数据集的分类模型训练在本次的分类模型训练中 , 我分别使用了简单的CNN网络和经典的ResNet50网络 , 分别对CIFAR-10数据集和ImageNet数据集进行了分类训练 。
- – 模型介绍与数据集介绍
CIFAR-10数据集是一个比较小、也比较常见的图像分类数据集 , 其共有60000张32×32的彩色图片 , 图片分为10类 , 每类6000张图 。 其中有50000张用于训练 , 10000张用于测试 。
ImageNet数据集则是一个用于视觉对象识别软件研究的大型可视化数据库 , 其中包含了20000多物体类别 , 共计约1400万张图像 , 是计算机视觉领域最具权威的数据集之一 。
- – 模型训练与结果
推荐阅读















- “横屏旗舰”iQOO 7评测:在极致体验的赛道上一路狂奔
- 红米k40pro和iqooneo3哪个好性价比高 参数对比区别评测
- 惠普发布Elite Dragonfly G2与Elite Dragonfly Max等笔记本新品
- 恩杰KRAKEN X73 RGB评测:颜值升级无穷尽
- 可靠实用的最佳拍档 法翼T1执法记录仪体验评测
- 释放耳机无线潜能 飞傲UTWS3真无线耳放评测
- 20分钟电池回血大半!realme真我V15评测:1399元中端王炸全面升级
- 内存大厂跨界之作!芝奇Enki 360一体式水冷评测:高密度冷排稳压18核心
- 首款7GB/s SSD!三星980PRO 1TB评测:永恒的1.8GB/s缓外写入速度
- 华为畅享20se和红米note9哪个好区别在哪 参数对比评测