相亲|数学家的相亲模型,你或许可以用到,相亲不够有效的原因在此( 四 )
但是建议量力而行,根据自己的实际情况确定N的值。。
最后,再说下这个模型的非常明显的缺点:如果最佳人选本来就在这前36.79%的人里面,错过这 36.79% 的人之后,再也碰不上更好的了。(终身遗憾)
决策树是直观运用概率分析的树形分类器,是很常用的分类方法,属于监管学习,决策树分类过程是从根节点开始,根据特征属性值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果.
如图1-11所示的树状图展现了当代女大学生相亲的决策行为。其考虑的首要因素的是长相,其他考虑因素依次为专业、年龄差和星座,同意与否都根据相应变量的取值而定。
决策树算法模拟了上述的决策行为,按照这些要求,可以对候选相亲男性的数据进行分类预测,然后根据预测结果找出女大学生心仪的男性。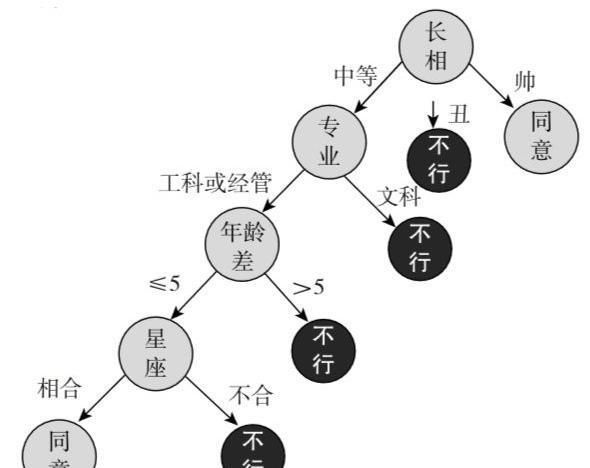
文章图片
决策树以女性相亲为例,那么对于一个在婚恋交友网站注册的男性,如何预测该男性的相亲成功率呢?这里使用KNN算法(K-NearestNeighor,最邻近算法)进行预测。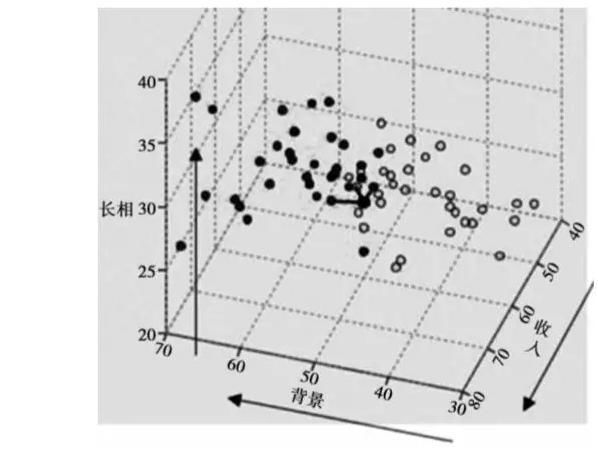
文章图片
这里采用三个变量或属性来描述一个男性,即收入、背景和长相。
在已有的数据中,深灰色点代表相亲成功的人,白点代表相亲不成功的人,中间连接线条的黑点代表一个新来的男性,KNN算法在预测这个新人相亲是否成功时,会找到他和附近的K个点,并根据这些点是否相亲成功来设定新人约会成功的概率。
比如图1-12中黑点与两个深灰色点、一个白点最近,因此该点相亲成功的可能性占2/3。
KNN算法属于惰性算法,其特点是不事先建立全局的判别公式或规则。当新数据需要分类时,根据每个样本和原有样本之间的距离,取最近K个样本点的众数(Y为分类变量)或均值(Y为连续变量)作为新样本的预测值。该预测方法体现了一句中国的老话“近朱者赤,近墨者黑”。
参考文献:张天蓉,《从掷骰子到阿尔法狗:趣谈概率》
推荐阅读















- 浙样的生活|杭州一姑娘去万松书院相亲角,回来说再也不会去了……
- 探秘组|越南有个相亲角,只有女人挑选男人的份,男人没有资格说“不”
- 将自己的脸|还记得相亲节目中的“猫脸女嘉宾”吗?卸妆后的样子,让人想不到
- 杭州姑娘去万松书院相亲后怒了:当你儿子是皇帝选妃呢?
- 美食小哥谈美食|大龄男女饭店相亲,女子狂点7000多元高端菜,最后买单时崩溃了!
- 快本|何炅搞黑幕?快本招新变相亲,创23年最低收视,4类新人高下立判
- 失败|她曾是央视主持人,辞职后创业,感情失败,在相亲节目被富豪牵走
- 相亲类型|相亲节目全是托?有对象的还上去?人设全是节目组给安排的?
- 饭店|一男一女饭店相亲,女子狂点7000元菜品,结账时女子崩溃到哭!
- 时间|轻松一刻:女孩有时间暂停功能,相亲男却不知,女孩给他一次机会