「Hadoop」大数据大牛,终于用37部分讲完了Hadoop体系之离线计算,共17.97G
文章图片
文章图片

前言Hadoop是一个由Apache基金会所开发的分布式系统基础架构 。
用户可以在不了解分布式底层细节的情况下 , 开发分布式程序 。 充分利用集群的威力进行高速运算和存储 。
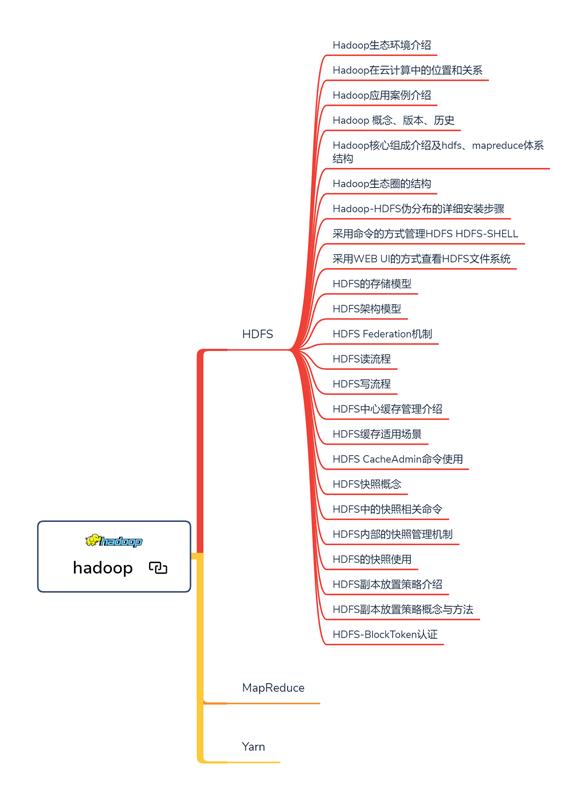
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System) , 简称HDFS 。
HDFS有高容错性的特点 , 并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据 , 适合那些有着超大数据集(large data set)的应用程序 。
Hadoop的框架最核心的设计就是:HDFS和MapReduce 。 HDFS为海量的数据提供了存储 , 而MapReduce则为海量的数据提供了计算 。
Hadoop体系之离线计算的学习路线1.Hadoop
01hadoop历史、hadoop存储模型、架构模型、读写流程、伪分布式安装
02全分布式安装、hadoop 高可用
03hdfs api使用MAPREDUCE框架
04单词统计项目 , 源码解释
05mapreduce案例一 , 二 , 三
06mapreduce案例四 , 五 , 六
2.Hive数据仓库
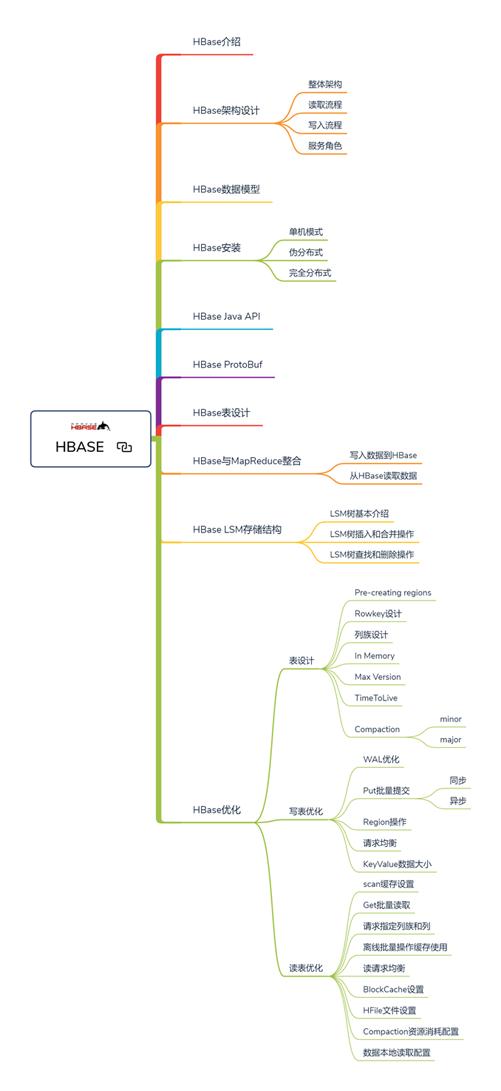
3.Hbase-NOSQL
(1) hbase介绍、搭建及Java api
① hive高可用及压缩存储
② hive复习
③hbase简介
④ hbase数据模型
⑤ hbase架构设计
⑥hbase standalone模式安装
(2)hbase表设计、protobuffer、MR整合、优化
① hbase复习及通话记录表设计
②hbase javaapi2
③hbase用户角色表、部门表设计
④ hbase protobuffer
⑤hbase与MapReduce整合
⑥ hbase优化设计
4.Zookeeper分布式协调架构
①zk介绍
②zk安装
③zk源语命令
④zk源语命令2
⑤zk
⑤zk_api
⑥分布式协调案例
5.Redis内存数据
01基础语法与数据类型
①REDIS_介绍
②String1
③string2
④list1
⑤list2set
⑥sortedset
⑦rdb
02架构模型
①redismode1
②redismode2
③redis-cluster
6.CDH
CDH_clouderaManager使用_hue
CDH_clouderaManager使用_impala_oozie
7.lucene与倒排索引 引擎安装 curl命令 项目案例
01lucene_介绍
02lucene介绍2
03el安装
04curl命令
05搜索项目1
06搜索项目2
8.大总结
01. 大数据知识整体复习
02. HDFS复习
03. HDFS复习2
04. MapReduce与YARN复习
05. Hive复习
06. Hbase复习
Hadoop思维导图
Hadoop体系之离线计算17.97G学习视频(资料+笔记+代码+作业)
每天乐分享 , 希望大家能够喜欢 , 需要的小伙伴可以转发关注小编 , 私信小编“学习”来得到获取方式了 。
感谢大家的支持 , 喜欢文章的小伙伴可以关注一下 , 后续更精彩 。
【「Hadoop」大数据大牛,终于用37部分讲完了Hadoop体系之离线计算,共17.97G】努力与幸运并存 , 但是你不努力 , 一点机会都没有 ,,
推荐阅读

















- 『Java』java数据结构系列——什么是数据结构
- 靓科技解读Thing,a16z、5.15亿美金的数据加密股票基金:找寻下一个Big
- 大数据邦选址很关键,新基建之大数据中心规划设计原则和内容
- 小熊带你玩科技数据成粤企生产新要素,工业互联网深调研〡从经验依赖到数据驱动
- 人工智能爱好者社区当心这个破坏家庭团结的数据泄露重灾区,多款APP违规采集个人信息
- ETtoday新闻云教授与中国学生在爆发前建模,单日10亿点阅约翰霍普金斯即时数据
- 可可酱江苏省销量同比增长164%,苏宁大数据:头盔成母亲节最特别礼物
- 「荣耀」红米K30Pro全方位吊打荣耀30Pro!数据来源:小米实验室
- 反式只防酸看到了未来的数据设计趋势,从阿里设计年鉴里
- []女生修电脑需要格式化,多达50G的“重要数据”,师傅点开后发现了新大陆