йҡҗжҖ§зҡ„еҸҚйҰҲеңЁspark MLlib дёӯжҖҺж ·еӨ„зҗҶиҝҷз§Қж•°жҚ®зҡ„ж–№жі•
йҡҗејҸеҸҚйҰҲеңЁspark https://spark.apache.org/docs/2.2.0/mllib-collaborative-filtering.htmlпјү дёӯжңүд»Ӣз»ҚпјҢдё»иҰҒеҹәдәҺи®әж–ҮCollaborative Filtering for Implicit Feedback Datasetsе®һзҺ°пјҢж ёеҝғжҖқжғі:
и·ҹжҳҫејҸеҸҚйҰҲдёҚеҗҢзҡ„жҳҜпјҢз”ұдәҺжІЎжңүжҳҫејҸзҡ„ratingпјҢеӣ жӯӨеј•е…Ҙpreferenceд»ҘеҸҠconfidence levelпјҢ preferenceиЎЁзӨәuserеҜ№itemжҳҜеҗҰж„ҹе…ҙи¶Јпјӣconfidence levelиЎЁзӨәpreferenceзҡ„зҪ®дҝЎеәҰпјҲжҜ”еҰӮuserеҜ№itemзҡ„ж“ҚдҪңж—¶й•ҝжҲ–иҖ…ж¬Ўж•°и¶Ҡй«ҳпјҢuserеҜ№itemж„ҹе…ҙи¶Јзҡ„еҸҜдҝЎеәҰе°ұи¶Ҡй«ҳпјҢиҖҢеҜ№дәҺиҙҹж ·жң¬пјҢеҚіuserжІЎжңүеҜ№itemж“ҚдҪңиҝҮпјҢдёҚж„ҹе…ҙи¶Јзҡ„зҪ®дҝЎеәҰзӣёеҜ№иҫғдҪҺпјҢеӣ дёәuserжІЎжңүж“ҚдҪңиҝҮitemзҡ„еҺҹеӣ еҫҲеӨҡпјҢдёҚдёҖе®ҡжҳҜз”ұдәҺuserеҜ№itemдёҚж„ҹе…ҙи¶ЈпјҢеҸҜиғҪжҳҜжІЎжңүзңӢеҲ°зӯүпјүпјӣ
ж•°еӯҰиЎЁиҫҫпјҡ
еҚіpreferenceпјҢ
дёәuserеҜ№itemзҡ„ж“ҚдҪңж¬Ўж•°жҲ–иҖ…ж—¶й•ҝзӯүпјӣ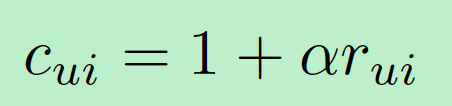
гҖҗйҡҗжҖ§зҡ„еҸҚйҰҲеңЁspark MLlib дёӯжҖҺж ·еӨ„зҗҶиҝҷз§Қж•°жҚ®зҡ„ж–№жі•гҖ‘
дёәconfidenceпјҢеҸҜд»ҘжңүеӨҡз§ҚйҮҸеҢ–ж–№жі•зҡ„йҖүжӢ©пјҢиҝҷйҮҢеҲ—еҮәзҡ„жҳҜи®әж–ҮдёӯдҪҝз”Ёзҡ„дёҖз§ҚпјҢ
и·ҹ
е‘ҲжӯЈзӣёе…іпјӣ
loss functionе®ҡд№үдёә: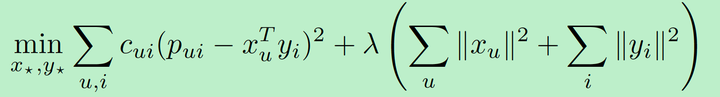
confidenceеңЁе…¶дёӯдҪ“зҺ°дёәпјҢ
и¶ҠеӨ§пјҢиҜҘжқЎж ·жң¬еңЁж•ҙдҪ“loss functionдёӯзҡ„еҪұе“Қе°ұи¶ҠеӨ§гҖӮ
и®ӯз»ғж•°жҚ®зҡ„ж јејҸдёәпјҡ
user_i item_j rij
вҖҰ.
вҖҰ.
е…·дҪ“еҸҜд»ҘеҸӮиҖғе®ҳзҪ‘https://spark.apache.org/docs/2.2.0/mllib-collaborative-filtering.htmlд»ҘеҸҠи®әж–ҮCollaborative Filtering for Implicit Feedback Datasets пјҢйҮҢйқўжңүжӣҙдёәиҜҰз»Ҷзҡ„иҜҙжҳҺгҖӮ


жҺЁиҚҗйҳ…иҜ»













- дә’иҒ”зҪ‘жҖҺж ·и§ЈеҶівҖң家ж”ҝжңҚеҠЎдёҠй—ЁйҖҹеәҰж…ўвҖқзҡ„й—®йўҳ
- дәӨжҚўжңәпјҢи·Ҝз”ұеҷЁз»ҸеёёжҖ§зҡ„жӯ»жңәе’ӢеҠһ
- |еҫҲеӨҡдәәз”ЁзҮ•йәҰеҪ“ж—©йӨҗпјҢзҮ•йәҰжҳҜзғӯжҖ§зҡ„иҝҳжҳҜеҮүжҖ§зҡ„пјҹ
- и‘ЈжҙҒ|40еІҒзҡ„и‘ЈжҙҒеҲ°еә•жҖҺд№Ҳе•Ұпјҹе°‘еҘійҖ еһӢиў«еҗҗж§ҪпјҢеҘіжҖ§зҡ„жё©жҹ”ж„ҹд№ҹдёҚи§ҒдәҶ
- иҘҝе®үеңЁиҘҝе’ёж–°еҢәе»әжҲҗеҗҺ3-5е№ҙйҮҢITдҝЎжҒҜдә§дёҡдјҡжңүйқ©е‘ҪжҖ§зҡ„зӘҒз ҙд№Ҳ
- жұҪиҪҰи§ӮеҜҹ家|еӨ§дј—жңҖжңүдёӘжҖ§зҡ„SUVпјҢT-ROCжҺўжӯҢеҰӮдҪ•дҝҳиҺ·е№ҙиҪ»дәәиҠіеҝғпјҹ
- йқ’е№ҙ|е®һжӢҚд»»жҖ§зҡ„з”өдёүиҪ®еӣӣеӨ„й—ҜзәўзҒҜ
- гҖҠй»‘жҡ—д№ӢйӯӮ3гҖӢжҚҸи„ёжҳҜжҖҺж ·еҒҡеҲ°еҸ–ж¶Ҳеҗ„дёӘзү№еҫҒзҡ„зӣёе…іжҖ§зҡ„
- вҖңзҗҶжҖ§вҖқжҳҜеҶізӯ–е’ҢйҖүжӢ©дёӯзҡ„жңҖдјҳи§Јеҗ—и§ЈжһҗйқһзҗҶжҖ§зҡ„зҗҶжҖ§йӣҶеҗҲиғҪеҗҰиҰҶзӣ–е…ЁйғЁйқһзҗҶжҖ§жҖҺж ·зңӢеҫ…AIиҝӣеҢ–д№Ӣи·Ҝ
- жұҪиҪҰй…ҚзҪ®|йў иҰҶжҖ§зҡ„е…Ёж–°еҫ·зі»Mи·‘иҪҰпјҢзўізәӨз»ҙиҪҰйЎ¶е…Ёзі»6зјёеј•ж“ҺпјҢзҺ°еңЁжҸҗиҪҰиҰҒеҠ д»·