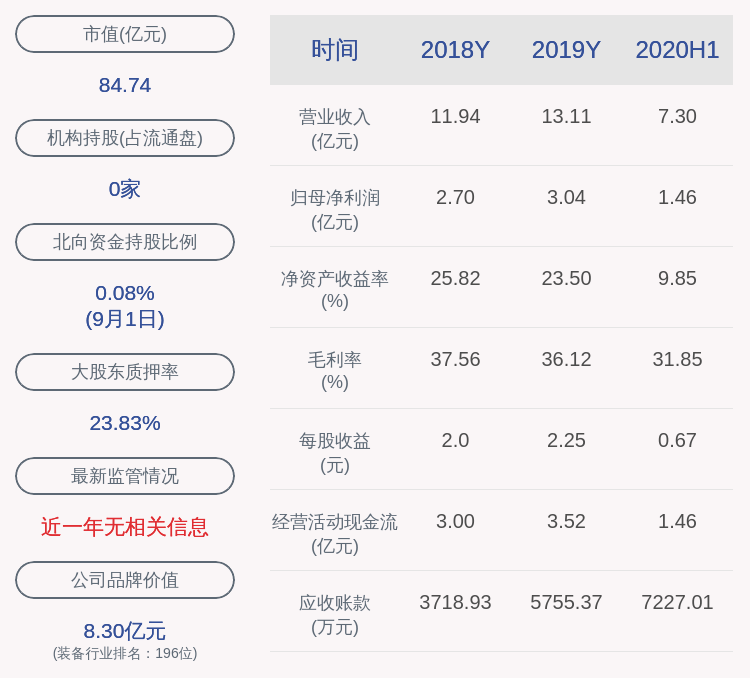
ж•°еӯ—еӯ—ж®өе’Ңеӯ—з¬ҰдёІжҜ”иҫғд»Җд№Ҳж•Ҳжһңе‘ўпјҹеҰӮдёӢпјҡ
mysql> select * from test1 where id = '4000000';+---------+-----------------+-----+-------------------------+| id | name | sex | email |+---------+-----------------+-----+-------------------------+| 4000000 | javacode4000000 | 2 | javacode4000000@163.com |+---------+-----------------+-----+-------------------------+1 row in set (0.00 sec)mysql> select * from test1 where id = 4000000;+---------+-----------------+-----+-------------------------+| id | name | sex | email |+---------+-----------------+-----+-------------------------+| 4000000 | javacode4000000 | 2 | javacode4000000@163.com |+---------+-----------------+-----+-------------------------+1 row in set (0.00 sec)
idдёҠйқўжңүдё»й”®зҙўеј•пјҢidжҳҜintзұ»еһӢзҡ„пјҢеҸҜд»ҘзңӢеҲ°пјҢдёҠйқўдёӨдёӘжҹҘиҜўйғҪйқһеёёеҝ«пјҢйғҪеҸҜд»ҘжӯЈеёёеҲ©з”Ёзҙўеј•еҝ«йҖҹжЈҖзҙўпјҢжүҖд»ҘеҰӮжһңеӯ—ж®өжҳҜж•°з»„зұ»еһӢзҡ„пјҢжҹҘиҜўзҡ„еҖјжҳҜеӯ—з¬ҰдёІиҝҳжҳҜж•°з»„йғҪдјҡиө°зҙўеј• гҖӮеҮҪж•°дҪҝзҙўеј•ж— ж•Ҳ
mysql> select a.name+1 from test1 a where a.name = 'javacode1';+----------+| a.name+1 |+----------+| 1 |+----------+1 row in set, 1 warning (0.00 sec)mysql> select * from test1 a where concat(a.name,'1') = 'javacode11';+----+-----------+-----+-------------------+| id | name | sex | email |+----+-----------+-----+-------------------+| 1 | javacode1 | 1 | javacode1@163.com |+----+-----------+-----+-------------------+1 row in set (2.88 sec)
nameдёҠжңүзҙўеј•пјҢдёҠйқўжҹҘиҜўпјҢ第дёҖдёӘиө°зҙўеј•пјҢ第дәҢдёӘдёҚиө°зҙўеј•пјҢ第дәҢдёӘдҪҝз”ЁдәҶеҮҪж•°д№ӢеҗҺпјҢnameжүҖеңЁзҡ„зҙўеј•ж ‘жҳҜж— жі•еҝ«йҖҹе®ҡдҪҚйңҖиҰҒжҹҘжүҫзҡ„ж•°жҚ®жүҖеңЁзҡ„йЎөзҡ„пјҢеҸӘиғҪе°ҶжүҖжңүйЎөзҡ„и®°еҪ•еҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺеҜ№жҜҸжқЎж•°жҚ®дҪҝз”ЁеҮҪж•°иҝӣиЎҢи®Ўз®—д№ӢеҗҺеҶҚиҝӣиЎҢжқЎд»¶еҲӨж–ӯпјҢжӯӨж—¶зҙўеј•ж— ж•ҲдәҶпјҢеҸҳжҲҗдәҶе…ЁиЎЁж•°жҚ®жү«жҸҸ гҖӮз»“и®әпјҡзҙўеј•еӯ—ж®өдҪҝз”ЁеҮҪж•°жҹҘиҜўдҪҝзҙўеј•ж— ж•Ҳ гҖӮ
иҝҗз®—з¬ҰдҪҝзҙўеј•ж— ж•Ҳ
mysql> select * from test1 a where id = 2 - 1;+----+-----------+-----+-------------------+| id | name | sex | email |+----+-----------+-----+-------------------+| 1 | javacode1 | 1 | javacode1@163.com |+----+-----------+-----+-------------------+1 row in set (0.00 sec)mysql> select * from test1 a where id+1 = 2;+----+-----------+-----+-------------------+| id | name | sex | email |+----+-----------+-----+-------------------+| 1 | javacode1 | 1 | javacode1@163.com |+----+-----------+-----+-------------------+1 row in set (2.41 sec)
idдёҠжңүдё»й”®зҙўеј•пјҢдёҠйқўжҹҘиҜўпјҢ第дёҖдёӘиө°зҙўеј•пјҢ第дәҢдёӘдёҚиө°зҙўеј•пјҢ第дәҢдёӘдҪҝз”Ёиҝҗз®—з¬ҰпјҢidжүҖеңЁзҡ„зҙўеј•ж ‘жҳҜж— жі•еҝ«йҖҹе®ҡдҪҚйңҖиҰҒжҹҘжүҫзҡ„ж•°жҚ®жүҖеңЁзҡ„йЎөзҡ„пјҢеҸӘиғҪе°ҶжүҖжңүйЎөзҡ„и®°еҪ•еҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺеҜ№жҜҸжқЎж•°жҚ®зҡ„idиҝӣиЎҢи®Ўз®—д№ӢеҗҺеҶҚеҲӨж–ӯжҳҜеҗҰзӯүдәҺ1пјҢжӯӨж—¶зҙўеј•ж— ж•ҲдәҶпјҢеҸҳжҲҗдәҶе…ЁиЎЁж•°жҚ®жү«жҸҸ гҖӮз»“и®әпјҡзҙўеј•еӯ—ж®өдҪҝз”ЁдәҶеҮҪж•°е°ҶдҪҝзҙўеј•ж— ж•Ҳ гҖӮ
дҪҝз”Ёзҙўеј•дјҳеҢ–жҺ’еәҸ
жҲ‘们жңүдёӘи®ўеҚ•иЎЁt_order(id,user_id,addtime,price)пјҢз»ҸеёёдјҡжҹҘиҜўжҹҗдёӘз”ЁжҲ·зҡ„и®ўеҚ•пјҢ并且жҢүз…§addtimeеҚҮеәҸжҺ’еәҸпјҢеә”иҜҘжҖҺд№ҲеҲӣе»әзҙўеј•е‘ўпјҹжҲ‘们жқҘеҲҶжһҗдёҖдёӢ гҖӮ
еңЁuser_idдёҠеҲӣе»әзҙўеј•пјҢжҲ‘们еҲҶжһҗдёҖдёӢиҝҷз§Қжғ…еҶөпјҢж•°жҚ®жЈҖзҙўзҡ„иҝҮзЁӢпјҡ
- иө°user_idзҙўеј•пјҢжүҫеҲ°и®°еҪ•зҡ„зҡ„id
- йҖҡиҝҮidеңЁдё»й”®зҙўеј•дёӯеӣһиЎЁжЈҖзҙўеҮәж•ҙжқЎж•°жҚ®
- йҮҚеӨҚдёҠйқўзҡ„ж“ҚдҪңпјҢиҺ·еҸ–жүҖжңүзӣ®ж Үи®°еҪ•
- еңЁеҶ…еӯҳдёӯеҜ№зӣ®ж Үи®°еҪ•жҢүз…§addtimeиҝӣиЎҢжҺ’еәҸ
жҲ‘们еҶҚеӣһйЎҫдёҖдёӢmysqlдёӯb+ж ‘ж•°жҚ®зҡ„з»“жһ„пјҢи®°еҪ•жҳҜжҢүз…§зҙўеј•зҡ„еҖјжҺ’еәҸз»„жҲҗзҡ„й“ҫиЎЁпјҢеҰӮжһңе°Ҷuser_idе’Ңaddtimeж”ҫеңЁдёҖиө·з»„жҲҗиҒ”еҗҲзҙўеј•(user_id,addtime)пјҢиҝҷж ·йҖҡиҝҮuser_idжЈҖзҙўеҮәжқҘзҡ„ж•°жҚ®иҮӘ然е°ұжҳҜжҢүз…§addtimeжҺ’еҘҪеәҸзҡ„пјҢиҝҷж ·зӣҙжҺҘе°‘дәҶдёҖжӯҘжҺ’еәҸж“ҚдҪңпјҢж•ҲзҺҮжӣҙеҘҪпјҢеҰӮжһңйңҖaddtimeйҷҚеәҸпјҢеҸӘйңҖиҰҒе°Ҷз»“жһңзҝ»иҪ¬дёҖдёӢе°ұеҸҜд»ҘдәҶ гҖӮ
жҖ»з»“дёҖдёӢдҪҝз”Ёзҙўеј•зҡ„дёҖдәӣе»әи®®
- еңЁеҢәеҲҶеәҰй«ҳзҡ„еӯ—ж®өдёҠйқўе»әз«Ӣзҙўеј•еҸҜд»Ҙжңүж•Ҳзҡ„дҪҝз”Ёзҙўеј•пјҢеҢәеҲҶеәҰеӨӘдҪҺпјҢж— жі•жңүж•Ҳзҡ„еҲ©з”Ёзҙўеј•пјҢеҸҜиғҪйңҖиҰҒжү«жҸҸжүҖжңүж•°жҚ®йЎөпјҢжӯӨж—¶е’ҢдёҚдҪҝз”Ёзҙўеј•е·®дёҚеӨҡ
- иҒ”еҗҲзҙўеј•жіЁж„ҸжңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҡеҝ…йЎ»жҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸеҢ№й…ҚпјҢmysqlдјҡдёҖзӣҙеҗ‘еҸіеҢ№й…ҚзӣҙеҲ°йҒҮеҲ°иҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒlike)е°ұеҒңжӯўеҢ№й…ҚпјҢжҜ”еҰӮa = 1 and b = 2 and c > 3 and d = 4 еҰӮжһңе»әз«Ӣ(a,b,c,d)йЎәеәҸзҡ„зҙўеј•пјҢdжҳҜз”ЁдёҚеҲ°зҙўеј•зҡ„пјҢеҰӮжһңе»әз«Ӣ(a,b,d,c)зҡ„зҙўеј•еҲҷйғҪеҸҜд»Ҙз”ЁеҲ°пјҢa,b,dзҡ„йЎәеәҸеҸҜд»Ҙд»»ж„Ҹи°ғж•ҙ
- жҹҘиҜўи®°еҪ•зҡ„ж—¶еҖҷпјҢе°‘дҪҝз”Ё*пјҢе°ҪйҮҸеҺ»еҲ©з”Ёзҙўеј•иҰҶзӣ–пјҢеҸҜд»ҘеҮҸе°‘еӣһиЎЁж“ҚдҪңпјҢжҸҗеҚҮж•ҲзҺҮ
- жңүдәӣжҹҘиҜўеҸҜд»ҘйҮҮз”ЁиҒ”еҗҲзҙўеј•пјҢиҝӣиҖҢдҪҝз”ЁеҲ°зҙўеј•дёӢжҺЁпјҲIPCпјүпјҢд№ҹеҸҜд»ҘеҮҸе°‘еӣһиЎЁж“ҚдҪңпјҢжҸҗеҚҮж•ҲзҺҮ
- зҰҒжӯўеҜ№зҙўеј•еӯ—ж®өдҪҝз”ЁеҮҪж•°гҖҒиҝҗз®—з¬Ұж“ҚдҪңпјҢдјҡдҪҝзҙўеј•еӨұж•Ҳ
жҺЁиҚҗйҳ…иҜ»
- MysqlжҖ§иғҪдјҳеҢ–д№ӢйҖҗзә§дјҳеҢ–пјҢејҖеҸ‘дәәе‘ҳеҝ…еӨҮжҠҖе·§
- еҰӮдҪ•еҺ»еәҠдёҠиһЁиҷ«жңҖеҝ«ж–№жі• е№Іиҙ§ж»Ўж»ЎеәҠдёҠйҷӨиһЁиҷ«зҡ„з®ҖеҚ•ж–№жі•йҖҹжқҘдәҶи§Ј
- ж•ҷдҪ еҰӮдҪ•з”Ё openresty е®ҢзҫҺжӣҝжҚў nginx
- MySQLй”ҒиҜҰз»Ҷи®Іи§Ј
- ж•°жҚ®еә“жһ¶жһ„дёҫдҫӢиҜҙжҳҺ
- зңӢиө„ж·ұз«ҷй•ҝж•ҷдҪ еҰӮдҪ•еҒҡеҘҪзҪ‘з«ҷиҝҗиҗҘ
- еҰӮдҪ•е®һзҺ°дәӨжҚўжңәдёҚеҗҢVLANгҖҒдёҚеҗҢзҪ‘ж®өд№Ӣй—ҙдә’и®ҝпјҹ
- зӯ’зҒҜе°әеҜёдёҖиҲ¬жҳҜеӨҡе°‘ еҰӮдҪ•йҖүжӢ©зӯ’зҒҜе°әеҜё
- жӮЈжңүйј»зӘҰзӮҺеҰӮдҪ•жҺ’и„“
- йј»зӘҰзӮҺеј•иө·зҡ„дҪҺзғ§еҰӮдҪ•жІ»з–—