дәәе·ҘжҷәиғҪ|12nmеӘІзҫҺ7nmпјҒзҮ§еҺҹ科жҠҖеҸ‘еёғеёҰе®ҪжңҖеӨ§зҡ„дә‘з«ҜAIжҺЁзҗҶеҚЎ
12жңҲ7ж—ҘпјҢAIеҲӣдёҡе…¬еҸёзҮ§еҺҹ科жҠҖ(Enflame)еҸ‘еёғдәҶ第дәҢд»Јдә‘з«ҜAIжҺЁзҗҶеҠ йҖҹеҚЎ——“дә‘зҮ§i20” гҖӮ
иҝҷжҳҜ继д»Ҡе№ҙ7жңҲзҡ„дә‘з«ҜAIи®ӯз»ғеҠ йҖҹеҚЎ“дә‘зҮ§T20”д№ӢеҗҺпјҢзҮ§еҺҹ科жҠҖж–°дёҖд»Јй’ҲеҜ№дә‘з«ҜжҺЁзҗҶеңәжҷҜзҡ„AIеҠ йҖҹдә§е“Ғ гҖӮ
дә‘зҮ§i20жңҖеӨ§дә®зӮ№е°ұжҳҜжӢҘжңүиҝ„д»ҠжңҖеӨ§зҡ„AIеҠ йҖҹеҚЎеӯҳеӮЁеёҰе®ҪпјҢйҖҡиҝҮHBM2eеҶ…еӯҳиҫҫеҲ°дәҶ819GB/sпјҢеҸҜдёәдә‘з«ҜжҺЁзҗҶдёҡеҠЎжҸҗдҫӣй«ҳеҗһеҗҗгҖҒдҪҺ延时зҡ„жҖ§иғҪ гҖӮ
зӣ®еүҚпјҢд»ҘиҜӯйҹіиҜҶеҲ«гҖҒеӣҫзүҮиҜҶеҲ«гҖҒи§Ҷйў‘еҶ…е®№еҲҶжһҗдёәдё»зҡ„ж„ҹзҹҘзұ»еә”з”ЁпјҢеҶ…е®№жҺЁиҚҗгҖҒж¬әиҜҲдәӨжҳ“жӢҰжҲӘзӯүеҶізӯ–зұ»еә”з”ЁпјҢеңЁдә‘з«ҜеӨ§йғЁеҲҶйғҪжҳҜд»Ҙе®һж—¶еңЁзәҝзҡ„ж–№ејҸжҸҗдҫӣжңҚеҠЎпјҢеҗҢж—¶зҘһз»ҸзҪ‘з»ңзҡ„еҸӮж•°и¶ҠжқҘи¶ҠеӨҡпјҢж•°жҚ®еёҰе®ҪйңҖжұӮд№ҹи¶ҠжқҘи¶Ҡй«ҳпјҢеӣ жӯӨе…јйЎҫй«ҳеёҰе®ҪгҖҒдҪҺ延иҝҹеҸҳеҫ—иҮіе…ійҮҚиҰҒ гҖӮ
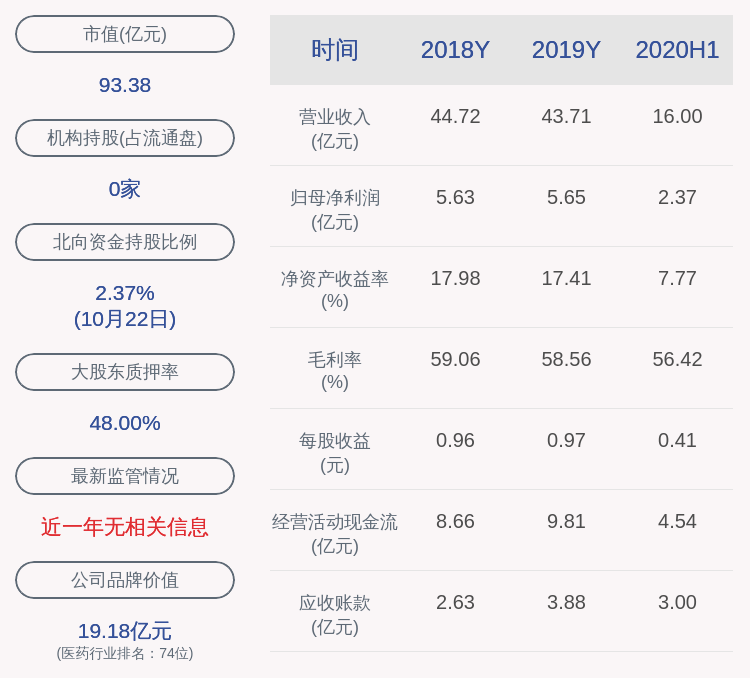
гҖҗдәәе·ҘжҷәиғҪ|12nmеӘІзҫҺ7nmпјҒзҮ§еҺҹ科жҠҖеҸ‘еёғеёҰе®ҪжңҖеӨ§зҡ„дә‘з«ҜAIжҺЁзҗҶеҚЎгҖ‘
ж–Үз« еӣҫзүҮ
дә‘зҮ§i20жҗӯиҪҪдәҶж–°дёҖд»ЈAIжҺЁзҗҶиҠҜзүҮ“йӮғжҖқ”пјҢеҹәдәҺ第дәҢд»Јй«ҳжҖ§иғҪи®Ўз®—ж ёеҝғе’Ңж•°жҚ®еј•ж“ҺпјҢ12nmе·Ҙиүәжү“йҖ пјҢйҖҡиҝҮжһ¶жһ„еҚҮзә§еӨ§еӨ§жҸҗй«ҳдәҶеҚ•дҪҚйқўз§Ҝзҡ„жҷ¶дҪ“з®Ўж•ҲзҺҮпјҢз®—еҠӣеҸҜеӘІзҫҺ7nm GPUпјҢиҖҢдё”жҲҗжң¬жӣҙдҪҺ гҖӮ
еҗҢж—¶пјҢе…Ёйқўж”ҜжҢҒFP32гҖҒTF32гҖҒFP16гҖҒBF16гҖҒINT8зҡ„и®Ўз®—зІҫеәҰпјҢе…¶дёӯеҚ•зІҫеәҰFP32еі°еҖјз®—еҠӣ32TFLOPSпјҢеҚ•зІҫеәҰеј йҮҸTF32еі°еҖјз®—еҠӣ128TFLOPSпјҢж•ҙеһӢINT8еі°еҖјз®—еҠӣ256TOPSпјҢеҜ№жҜ”дёҠд»Јдә‘зҮ§i10жө®зӮ№гҖҒж•ҙеһӢз®—еҠӣеҲҶеҲ«жҸҗеҚҮеҲ°1.8еҖҚгҖҒ3.6еҖҚ гҖӮ

ж–Үз« еӣҫзүҮ
жҗӯй…ҚеҚҮзә§еҗҺзҡ„иҪҜ件ж Ҳ“й©ӯз®—TopsRider”пјҢжҖ§иғҪгҖҒејҖеҸ‘ж•ҲзҺҮгҖҒжЁЎеһӢиҰҶзӣ–йқўйғҪеҫ—еҲ°еӨ§е№…жҸҗеҚҮ гҖӮ
йҖҡиҝҮеј•е…ҘйҖҡз”Ёй«ҳеұӮеӣҫдјҳеҢ–е’ҢеӨ§и§„жЁЎз®—еӯҗиһҚеҗҲжҠҖжңҜпјҢйҮҠж”ҫеӨ§е®№йҮҸзүҮеҶ…еӯҳеӮЁе’Ңй«ҳеёҰе®ҪеӯҳеӮЁзҡ„еҲ©з”ЁзҺҮпјҢжЁЎеһӢе№іеқҮжҖ§иғҪжҸҗеҚҮ3.5еҖҚпјҢ硬件算еҠӣеҲ©з”ЁзҺҮе№іеқҮжҸҗеҚҮ2еҖҚ гҖӮ
йҖҡиҝҮеҚҮзә§зҡ„зј–зЁӢжЁЎеһӢд»ҘеҸҠз®—еӯҗиҮӘеҠЁеҲҶзүҮгҖҒиҮӘеҠЁз”ҹжҲҗжҠҖжңҜпјҢиҮӘе®ҡд№үз®—еӯҗејҖеҸ‘ж•ҲзҺҮзҝ»еҖҚпјҢжЁЎеһӢиҝҒ移жҲҗжң¬еӨ§еӨ§йҷҚдҪҺ гҖӮ
жӯӨеӨ–пјҢеҜ№еҠЁжҖҒжҖ§зҡ„ж”ҜжҢҒд№ҹеӨ§еӨ§еўһејәпјҢеңЁжЈҖжөӢгҖҒиҜӯйҹіиҜҶеҲ«гҖҒиҜӯд№үзҗҶи§ЈзӯүеңәжҷҜжӣҙе…·з«һдәүеҠӣ гҖӮ
жҚ®д»Ӣз»ҚпјҢзҮ§еҺҹ科жҠҖдё“жіЁAIйўҶеҹҹдә‘з«Ҝз®—еҠӣе№іеҸ°пјҢжҸҗдҫӣиҮӘдё»зҹҘиҜҶдә§жқғзҡ„й«ҳз®—еҠӣгҖҒй«ҳиғҪж•ҲжҜ”гҖҒеҸҜзј–зЁӢзҡ„йҖҡз”ЁAIи®ӯз»ғе’ҢжҺЁзҗҶдә§е“ҒпјҢеҸҜе№ҝжіӣеә”з”ЁдәҺдә‘ж•°жҚ®дёӯеҝғгҖҒи¶…з®—дёӯеҝғгҖҒдә’иҒ”зҪ‘гҖҒйҮ‘иһҚгҖҒжҷәж…§еҹҺеёӮзӯүеӨҡдёӘдәәе·ҘжҷәиғҪеңәжҷҜпјҢе·ІеңЁдә’иҒ”зҪ‘гҖҒйҮ‘иһҚгҖҒж”ҝеҠЎзӯүеӨҡ家客жҲ·зҡ„е•ҶдёҡиҗҪең°пјҢ并иҺ·еҫ—и®ӨеҸҜ гҖӮ

ж–Үз« еӣҫзүҮ
жҺЁиҚҗйҳ…иҜ»
















- Steam|иҪҰжңәеӨ„зҗҶеҷЁеӘІзҫҺPS5дё»жңәпјҒ马ж–Ҝе…ӢйҖҸйңІеӨ§и®ЎеҲ’ SteamзҺ©е®¶з¬‘дәҶ
- дәәе·ҘжҷәиғҪ|дёӯеӣҪејҸжөӘжј«д№ӢеӨ–зҡ„еҢ—дә¬еҶ¬еҘҘпјҡиҝҷдҪҚеҢ—дә¬еӨ§еҰһжңҖи®©дәәжғідёҚеҲ°
- дёүжҳҹ|дёүжҳҹиҜ•дә§4080еңҶжҹұеҪўз”өжұ пјҡеӘІзҫҺзү№ж–ҜжӢү4680гҖҒиғҪйҮҸеҜҶеәҰеӨ§еўһ
- 马иҫҫ|еӘІзҫҺiPhoneпјҒRedmi K50е®Үе®ҷе®ҳе®Јпјҡе…ЁзҗғйҰ–еҸ‘и¶…е®Ҫйў‘XиҪҙ马иҫҫ
- Intel|иЎЁзҺ°еҮәиүІпјҒIntelеҸҢж ёеҘ”и…ҫG7400и·‘еҲҶжҲҗз»©еҮәзӮүпјҡеӘІзҫҺеӣӣж ёй”җйҫҷR3 3200G
- иӢ№жһң|1.3дёҮеқ—пјҒиӢ№жһңж–°ж——иҲ°ARи®ҫеӨҮжӣқе…үпјҡжҖ§иғҪеӘІзҫҺM1 ProгҖҒж”ҜжҢҒ8K
- иөӣжү¬|Intelиөӣжү¬G6900жҖ§иғҪи·‘еҲҶжӣқе…үпјҡеҚ•ж ёеӘІзҫҺй…·зқҝi9-10900K
- еӣәжҖҒзЎ¬зӣҳ|иҒ”иҠёеҸ‘еёғ12nm PCIe 4.0дё»жҺ§иҠҜзүҮпјҡж— йңҖи¶…йў‘еҚіеҸҜж»ЎиЎҖи·‘еҮә7.4GB/s
- Intel|Intelй…·зқҝi5-1250Pи·‘еҲҶжӣқе…үпјҡеҚ•ж ёеӘІзҫҺй”җйҫҷ7 5800X
- дјҳзӣҳ|еҸ°з”өжҺЁеҮәйЈһиұ№еӣәжҖҒUзӣҳпјҡйҖҹеәҰиҫҫ400MB/s еӘІзҫҺSSD