еҪұй©°RTX 3060Ti OCиҜ„жөӢ 80sз»Ҳз»“иҖ…( дёү )
зЁҖз–Ҹж·ұеәҰеӯҰд№
Tensor CoreеҸҜд»ҘзңӢдҪңжҳҜGeForce RTX GPUдёҠзҡ„AIеӨ§и„‘ гҖӮ еҸҜеҠ йҖҹз”ЁдәҺж·ұеәҰзҘһз»ҸзҪ‘з»ңеӨ„зҗҶеҠҹиғҪзҡ„зәҝжҖ§д»Јж•° пјҢ иҝҷжҳҜзҺ°д»ЈAIзҡ„еҹәзЎҖ гҖӮ дҫӢеҰӮз”ЁдәҺAIи¶…еҲҶиҫЁзҺҮзҡ„NVIDIA DLSSе’Ңз”ЁдәҺAIеўһејәзҡ„еЈ°з”»еӨ„зҗҶжҠҖжңҜNVIDIA Broadcastеә”з”Ё гҖӮ
еңЁжң¬ж¬Ўзҡ„NVIDIA Ampereжһ¶жһ„зҡ„Tensor Coreд№ҹеҫ—еҲ°дәҶжһҒеӨ§ең°еҠ ејә пјҢ еңЁз¬¬дёүд»ЈTensor Coreдёӯ пјҢ NVIDIAеј•е…ҘдәҶзЁҖз–ҸеҢ–еҠ йҖҹ пјҢ еҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNпјҲж·ұеәҰзҘһз»ҸзҪ‘з»ңпјүжқғйҮҚ пјҢ еҗҢж—¶дҫқ然иғҪдҝқжҢҒдёҚй”ҷзҡ„зІҫеәҰ гҖӮ
йҰ–е…ҲеҺҹе§Ӣзҡ„еҜҶйӣҶзҹ©йҳөдјҡз»ҸиҝҮи®ӯз»ғ пјҢ еҲ йҷӨжҺүзЁҖз–Ҹзҹ©йҳө пјҢ еҶҚз»ҸиҝҮи®ӯз»ғзЁҖз–Ҹзҹ©йҳө пјҢ д»ҺиҖҢе®һзҺ°зЁҖз–ҸдјҳеҢ– пјҢ иҝӣиҖҢжҸҗй«ҳTensor Coreзҡ„жҖ§иғҪ гҖӮ
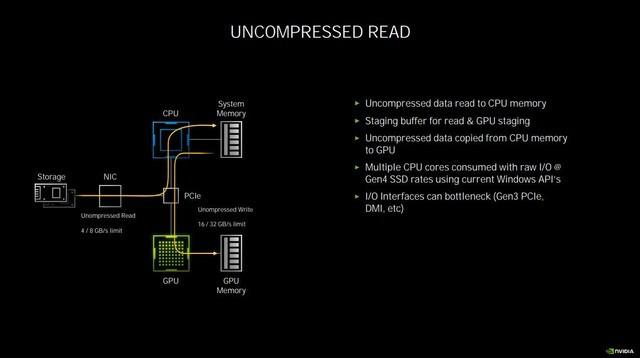
дёҺжӯӨж¬ЎRTX 30зі»жҳҫеҚЎдёҖеҗҢеҸ‘еёғзҡ„иҝҳжңүдёҖйЎ№ж–°жҠҖжңҜвҖ”вҖ”RTX IO гҖӮ зӣ®еүҚеҫҲеӨҡжёёжҲҸеҠЁиҫ„еҮ еҚҒGз”ҡиҮізҷҫGзҡ„е®үиЈ…з©әй—ҙ пјҢ еҜ№дәҺеӯҳеӮЁз©әй—ҙзҡ„иҙҹжӢ…жҡӮдё”дёҚжҸҗ пјҢ дҪҶеӯҳж”ҫеңЁзЎ¬зӣҳдёӯзҡ„ж•°жҚ® пјҢ еҰӮжһңжҳҫеҚЎжғіиҰҒиҜ»еҸ–еҲ° пјҢ йңҖиҰҒе…Ҳз”ұCPUд»ҺзЎ¬зӣҳдёӯиҜ»еҸ–еҺӢзј©иҝҮзҡ„ж•°жҚ® пјҢ з»ҸиҝҮи§ЈеҺӢзј©еҶҚеҸ‘йҖҒеҲ°жҳҫеӯҳдёӯ гҖӮ
иҷҪ然йҡҸзқҖNVMe SSDзҡ„жҺЁеҮә пјҢ иҜ»еҸ–йҖҹеәҰзӣёиҫғжңәжў°зЎ¬зӣҳиғҪеӨҹеҝ«20еҖҚ пјҢ дҪҶеҸ—еҲ¶дәҺдј з»ҹI/OйҷҗеҲ¶ пјҢ NVMeй«ҳиҫҫ7GB/з§’зҡ„й«ҳйҖҹиҜ»еҶҷеҜ№дәҺCPUжҳҜжһҒеӨ§зҡ„иҙҹжӢ… гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дј з»ҹзҡ„ж•°жҚ®дәӨжҚў
еңЁиҝҷдёӘиҝҮзЁӢдёӯ пјҢ дјҡеҚ з”ЁеӨҡдёӘCPUж ёеҝғ пјҢ еҺӢеҠӣжҖҘеү§еўһеӨ§ пјҢ еҚ з”ЁиҫғеӨҡзҡ„еҶ…еӯҳ пјҢ иҖҢжӯӨж—¶е…¶е®һGPUжҳҜеӨ„дәҺй—ІзҪ®зҠ¶жҖҒзҡ„ гҖӮ RTX IOзҡ„дҪңз”Ёе°ұжҳҜи¶ҠиҝҮCPUи§ЈеҺӢеҶҚдј иҫ“ж•°жҚ®иҝҷдёҖжӯҘ пјҢ зӣҙжҺҘд»ҺPCIEжҖ»зәҝиҜ»еҸ–зЎ¬зӣҳдёҠз»ҸиҝҮеҺӢзј©зҡ„ж•°жҚ® пјҢ 并且е®ҢжҲҗж— жҚҹGPUи§ЈеҺӢ пјҢ йҷҚдҪҺCPUеҚ з”Ё пјҢ еҸҳеҗ‘жҸҗеҚҮдәҶжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
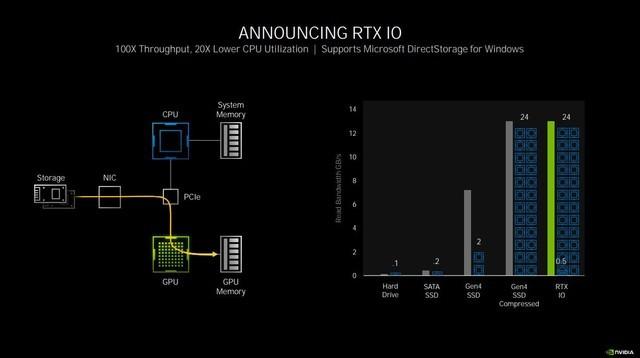
RTX IOеҸҜд»ҘжһҒеӨ§и§Јж”ҫCPUиҙҹжӢ…
еҪ“然иҝҷйЎ№жҠҖжңҜдҪңдёәзі»з»ҹеә•еұӮзҡ„иҝҗиЎҢж–№ејҸж”№еҸҳ пјҢ иҝҳйңҖиҰҒеҖҹеҠ©еҫ®иҪҜеҸ‘еёғзҡ„DirectStorageжқҘе®һзҺ° пјҢ еҜ№дәҺзӣ®еүҚе®№йҮҸзҡ„жёёжҲҸжқҘиҜҙ пјҢ RTX IOзҡ„ж”№е–„ж•Ҳжһңжңүйҷҗ пјҢ дҪҶеҒҮд»Ҙж—¶ж—ҘзӯүжёёжҲҸе®№йҮҸдёҠзҷҫGжҲҗдёәеёёжҖҒзҡ„ж—¶еҖҷ пјҢ иҝҷйЎ№жҠҖжңҜе°ҶдјҡеҸ‘жҢҘе·ЁеӨ§зҡ„еҠҹж•Ҳ гҖӮ
еҗҢж—¶жҗӯй…Қж–°еўһзҡ„HDMI 2.1жҺҘеҸЈ пјҢ еҸҜд»Ҙж”ҜжҢҒеҚ•зәҝ8Kзҡ„и§Ҷйў‘иҫ“еҮә пјҢ иҖҢдёҠдёҖд»ЈHDMI 2.0д»…ж”ҜжҢҒ4K 98Hzзҡ„и§Ҷйў‘иҫ“еҮә пјҢ еҰӮжһңжғіиҰҒиҝһжҺҘ8Kз”өи§Ҷ пјҢ еҲҷйңҖиҰҒжӣҙеӨҡзҡ„зәҝзјҶж”ҜжҢҒ гҖӮ
04 ејәеӨ§ж ёеҝғ еҮәеҺӮи¶…йў‘ з”Ёж–ҷеҺҡйҒ“
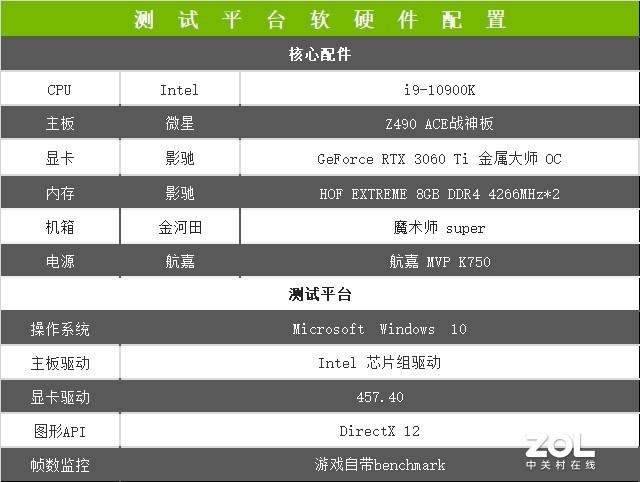
йҰ–е…Ҳд»Ӣз»ҚдёҖдёӢжөӢиҜ•е№іеҸ° пјҢ дёәдәҶдҝқиҜҒжӯӨж¬ЎиҜ„жөӢиғҪеӨҹеҸ‘жҢҘеҪұй©° RTX 3060 TiйҮ‘еұһеӨ§еёҲ OC жҳҫеҚЎзҡ„жңҖдҪіжҖ§иғҪ пјҢ дё»жқҝе’ҢCPUйҮҮз”ЁдәҶзӣ®еүҚжЎҢйқўж——иҲ°зә§й…ҚзҪ® пјҢ е…·дҪ“еҰӮдёӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
й…ҚзҪ®дҝЎжҒҜ
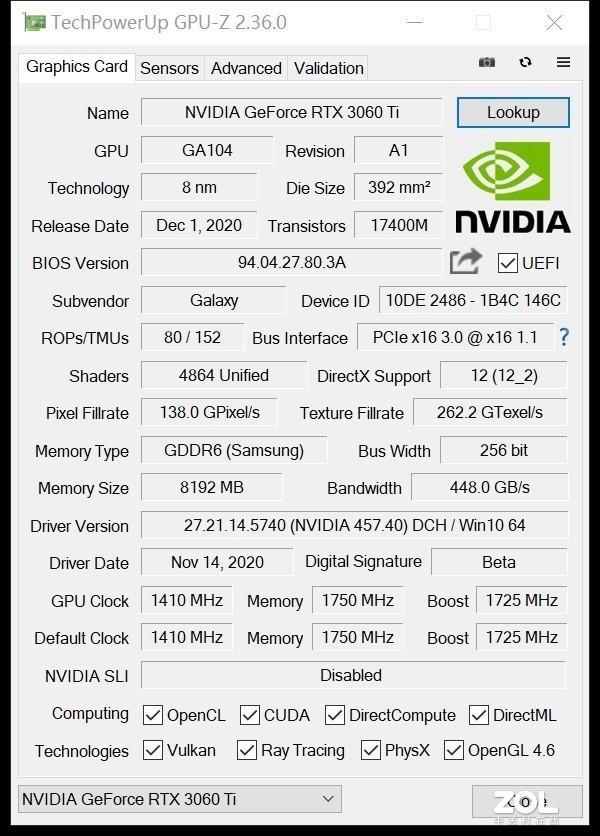
йҰ–е…ҲзңӢдёҖдёӢGPU-Zзҡ„еҸӮж•° пјҢ еҪұй©° RTX 3060 Ti йҮ‘еұһеӨ§еёҲ OC жҳҫеҚЎдҪҝз”ЁдәҶGA104иҠҜзүҮ пјҢ иҠҜзүҮйҮҮз”Ё8nmе·ҘиүәеҲ¶жҲҗ пјҢ жӢҘжңү4864з»„CUDAж ёеҝғ пјҢ е…¶ж ёеҝғйў‘зҺҮдёә1410-1750MHz пјҢ иҝӣиЎҢдәҶеҮәеҺӮи¶…йў‘ пјҢ жҜ”е…¬зүҲжҖ§иғҪжӣҙејә гҖӮ жҳҫеҚЎйҮҮз”Ё8GB GDDR6жҳҫеӯҳ пјҢ дҪҚе®Ҫдёә256bit пјҢ жҳҫеӯҳеёҰе®ҪиҫҫеҲ°дәҶ448GB/s пјҢ е…үж …еҚ•е…ғе’Ңзә№зҗҶеҚ•е…ғдёә80е’Ң152 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
GPU-ZеҸӮж•°
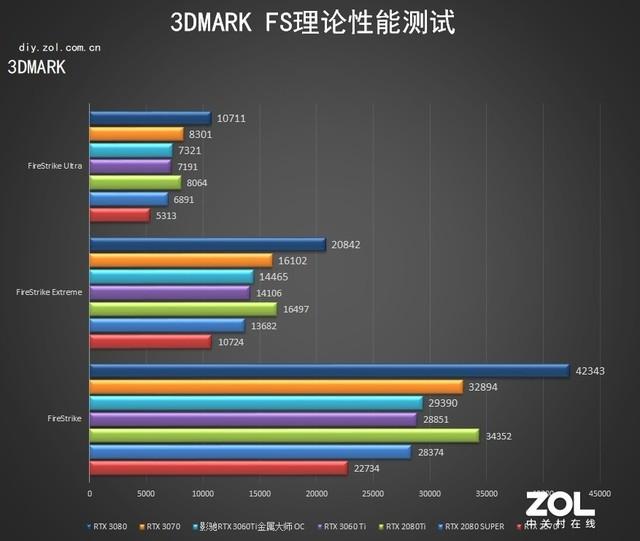
дёӢйқўе…ҲиҝӣиЎҢзҡ„жҳҜз”ЁжқҘиЎЎйҮҸжҳҫеҚЎDX11зҗҶи®әжҖ§иғҪзҡ„3DMARK FSеҘ—иЈ…пјҡFS,FSE,FSUдёүиҖ…еҲҶеҲ«еҜ№еә”жҳҫеҚЎеңЁ1080PгҖҒ2KгҖҒ4Kзҡ„зҗҶи®әжҖ§иғҪ пјҢ еҸ–жҳҫеҚЎеҲҶж•°е®һйҷ…жөӢиҜ•з»“жһңеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
3D MARK FSеҘ—иЈ…жөӢиҜ•
еңЁй’ҲеҜ№жҳҫеҚЎDX11жҖ§иғҪзҡ„3DMARK FSеҘ—иЈ…жөӢиҜ•дёӯ пјҢ жҲ‘们主иҰҒеҜ№жҜ”еҪұй©° RTX 3060 Ti йҮ‘еұһеӨ§еёҲ OCе’ҢRTX 2080 SUPER пјҢ ж•ҙдҪ“жқҘзңӢеҗ„йЎ№жҲҗз»©дёӯеқҮе°Ҹе№…йўҶе…ҲRTX 2080 SUPER гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
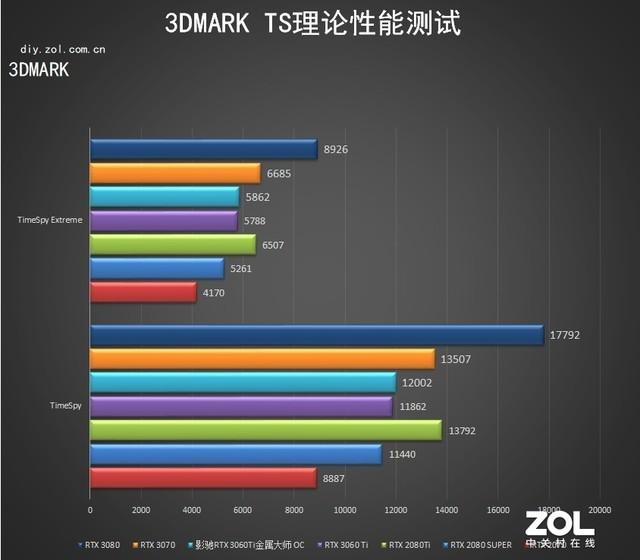
3D MARK TSеҘ—иЈ…жөӢиҜ•
иҖҢеңЁй’ҲеҜ№DX12зҺҜеўғдёӢзҡ„Time Spyе’ҢTime Spy ExtremeжөӢиҜ•дёӯ пјҢ еҪұй©° RTX 3060 Ti йҮ‘еұһеӨ§еёҲ OCеҗҢж ·е…ЁйқўйўҶе…ҲдәҺRTX 2080 SUPER пјҢ йўҶе…Ҳе№…еәҰеңЁ5%е·ҰеҸі гҖӮ
жҺЁиҚҗйҳ…иҜ»








![[иЎўе·һйӣҶиҒҡеҢә]гҖҗдёҖзәҝжҲҳвҖңз–«вҖқгҖ‘дёҖдҪҚ80еҗҺдёҡ委дјҡдё»д»»зҡ„йҳІз–«ж•…дәӢ](https://imgcdn.toutiaoyule.com/20200404/20200404084152089853a_t.jpeg)










- еҚҺзЎ•RTX 3060 Ultra 12GB GDDR6жҳҫеҚЎжӣқе…ү жҲ–е”®449зҫҺе…ғ
- RTX 3060зӘҒ然改еҗҚRTX 3060 UltraпјҒ12GBжҳҫеӯҳи¶…иҝҮRTX 3080
- еҫ®жҳҹйў„зғӯж–°дёҖд»ЈжёёжҲҸжң¬пјҡRTX 30зі»жҳҫеҚЎзҺӢиҖ…йҷҚдёҙ
- TACHYжҠ«йңІVortex 15жёёжҲҸ笔记жң¬пјҡR7-5800HдёҺRTX 3060еҠ жҢҒ
- еҫ®жҳҹеҖҫе…ЁеҠӣжү“йҖ зҡ„ж——иҲ°пјҒеҫ®жҳҹRTX 3080и¶…йҫҷиҜ„жөӢпјҡ4KиҝҪе№іRX 6900 XT
- зҲҪзҺ©е…үиҝҪеӨ§дҪңпјҢRTX 3060TiжҖ§д»·жҜ”з”өи„‘жҺЁиҚҗ
- RTX 3080/3070笔记жң¬жҳҫеҚЎи§„ж је®һй”ӨпјҡеӨ§е№…йҳүеүІ
- еҰҲеҰҲеҝғзҒөжүӢе·§ дёәе„ҝеӯҗеҲ¶дҪңRTX3080йҖ еһӢз”ҹж—ҘиӣӢзі•
- й“ӯз‘„RTX 3060 Ti iCraft OC еҝғд№ӢжүҖеҗ‘ж— з•Ҹж— еҸҢ
- еҪұй©°еҸ‘еёғз»Ҹе…ёзүҲRTX 3090/3080пјҡжҡҙеҠӣж¶ЎиҪ®йЈҺжүҮжҲҗдәҶж–°жҪ®