二叉状态树的结构,Part-1( 三 )
我们真的需要 RLP 吗?所有这些优化都是有用的吗?不见得呀 。
举个例子 , 假如我们不使用 rlp < 32 bytes这条规则 , 需要多占用多少存储空间呢?
跟今天全同步节点所需的约 300 GB 的存储空间相比 , 简直是微不足道 。
类似地 , 不使用十六进制前缀编码 , 也只会导致多占用 100 MB 的存储 , 也就是多占用 0.03% 。 只要仔细选择二进制 trie 的编码格式 , 这点差距就可以补回来 。
二进制 trie:送 RLP 入土为安在二级制 trie 上 , 分支节点会变得简单很多:一个节点最多只有两个子节点 , 可以由其哈希值来指出 。 一个 Keccak256/Sha256 的哈希值 , 也就是 32 个字节 。
在当前 , 显然的事情是 , 我们根本不需要一个能编码任意长度的值的通用编码方案 。 举个例子 , 假设新的二进制树种的每个节点都具有下列的字段:
- 左子节点哈希值 , 用作指针;
- 右子节点哈希值 , 用作指针;
- 值(可选) , 即存储在用于寻得此节点的键中(stored at the key used to get to this node)的值
- 前缀(可选) , 目的是替换十六进制 trie 中的延伸节点
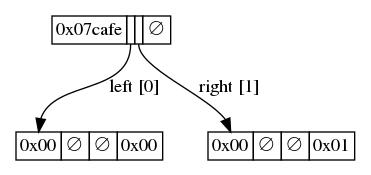 文章插图
文章插图- 例子中的树存储着键值对 (0xcafe, 0x00) 以及 (0xcaff, 0x01):根节点以键数据 “0xcafe” 和一个数字作为前缀;该数字表示最后一个字节中仅有 7 个比特用于存储前缀 。 然后该节点有两个指针指向其两个子节点 , 同时不包含值 。 每一个子节点都以空值为前缀(以 0x00 为标记) , 都有一个值 , 都没有子节点 。 -
客户端可以用只占两个字节的 header 来编码这个节点的数据:
- 中间节点序列化头提案 -
这个模式只需额外占用两个字节 , 相比之下 , RLP 则至少需要 5 个字节 。 第一个字节包含下列标签:
- 如果 #7 bit 为有 , 则此 header 后面所跟随的数据的前 32 个字节即是左子节点的哈希值 。 如果该比特为空 , 则左子节点的哈希值也为空 。
- 如果 #6 bit 为有 , 则跟着的 32 个字节表示右子节点的哈希值 。 如果该比特为空 , 则右子节点的哈希值也为空 。
- 如果 #4 bit 为有 , 则该 header 会有一个额外的字节来给出前缀比特中的数字;前缀比特则跟着 左/右 子节点哈希值放置;
- 如果 #5 bit 为有 , 则 header 后载荷剩下的字节就用来表示该值
结论我承认 , 在解释 RLP 的工作模式时 , 我一直在发泄使用 RLP 时累积的挫败感 。
客观来说 , 这个设计并不差 , 而且在过去五年的使用中毫无疑问也达到了它的设计目的 。 但随着时间推移 , 变得越来越清楚的是 , 其复杂性是一个过于昂贵的代价 , 我希望能说服你 , 在与存储树相关的部分中 , 取代 RLP 是利大于弊的 。
本文中所描述的存储树格式也远远称不上完备 , 我们会在日后介绍更多侧面 。
非常感谢 Sina Mahmoodi 和 Martin H. Swende 的反馈 。
(完)
(文内有许多超链接 , 可点击左下 ”阅读原文“ 从 EthFans 网站上获取)
原文链接:
@gballet/structure-of-a-binary-state-tree-part-1-48c587836d2f
作者:Guillaume Ballet
翻译&校对: 闵敏 & 阿剑
【二叉状态树的结构,Part-1】作者:以太坊爱好者;来自链得得内容开放平台“得得号” , 本文仅代表作者观点 , 不代表链得得官方立场凡“得得号”文章 , 原创性和内容的真实性由投稿人保证 , 如果稿件因抄袭、作假等行为导致的法律后果 , 由投稿人本人负责
推荐阅读














- “女性机器人”为啥火?外表颜值高、功能强,内部结构也一清二楚
- AMD Zen 3锐龙5000系列APU核心结构图曝光 较上一代更加强大
- 小米11官方公开内部结构,轻薄机身都藏了什么?
- 每经11点丨虾米音乐:2月5日起停止音乐服务;港股三大电信运营商直线拉升,均涨超5%;河北邢台全面进入战时状态
- 仅用168天,商汤科技“新一代人工智能计算与赋能平台”项目结构封顶
- 文化|广州再迎文化创意新地标!粤传媒大厦主体结构顺利封顶
- 每经22点 | 北京东城区:全区上下迅速进入应急状态;雷军回应小米“取消附送充电器”;国家卫健委医疗机构感染防控专家委员会成立
- 1184:平面点排序(二)&1185:添加记录(结构体专题)
- 工程项目|钢结构设计的发展前景?!国内分析...
- “停尸间已完全装满”,医疗系统进入紧急状态,苹果关闭加州所有零售店,医护人员控诉:我们已被压垮……