иҖ•еҚҮRTX 3060 TiиҝҪйЈҺиҜ„жөӢ зӯүйЈҺжқҘдёҚеҰӮиҝҪйЈҺеҺ»( дәҢ )
第дёҖд»ЈRTXжһ¶жһ„ TuringдёӢзҡ„RTX 2060 SUPER
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дәҢд»ЈRTXжһ¶жһ„ AmpereдёӢзҡ„RTX 3060 Ti
зӣёиҫғдәҺеҲқд»Јзҡ„Turing RTXжһ¶жһ„ пјҢ NVIDIA Ampereжһ¶жһ„еңЁз®—еҠӣдёҠжңүзқҖжҲҗеҖҚзҡ„еўһй•ҝ пјҢ иҝҷдёҖзӮ№еңЁRTX 3060 Tiдёӯдҫқж—§жңүдҪ“зҺ° пјҢ жҜҸдёӘж—¶й’ҹжү§иЎҢ2ж¬ЎзқҖиүІеҷЁиҝҗз®— пјҢ иҖҢTuringдёә1ж¬Ў пјҢ RTX 3060 Tiзҡ„зқҖиүІеҷЁжҖ§иғҪиҫҫеҲ°16.2 TFLOPSеҚ•зІҫеәҰжҖ§иғҪ пјҢ иҖҢTuringдёә7.2 TFLOPS гҖӮ
NVIDIA Ampereжһ¶жһ„зҝ»еҖҚдәҶе…үзәҝдёҺдёүи§’еҪўзҡ„зӣёдәӨеҗһеҗҗйҮҸ пјҢ RT CoreиҫҫеҲ°31.6 RT TFLOPS пјҢ иҖҢTuringдёә21.7 RT TFLOPS гҖӮ
е…Ёж–°зҡ„Tensor CoreеҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNжқғйҮҚ пјҢ еӨ„зҗҶзЁҖз–ҸзҪ‘з»ңзҡ„йҖҹзҺҮжҳҜTuringзҡ„дёӨеҖҚ пјҢ з®—еҠӣй«ҳиҫҫ129.6 Tensor TFLOPS пјҢ иҖҢTuringдёә57.4 Tensor TFLOPS гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
RTX 3060 TiйҮҮз”ЁGA104ж ёеҝғжӢҘжңү174дәҝдёӘжҷ¶дҪ“з®Ў пјҢ 392е№іж–№жҜ«зұізҡ„йқўз§Ҝ пјҢ еҹәдәҺдёүжҳҹзҡ„8nm NVIDIAе®ҡеҲ¶е·Ҙиүә пјҢ еҸҰеӨ–еңЁRTX 3060 TiдёӯжҲ‘们йғҪзҹҘйҒ“д»Қ然йҮҮз”ЁдәҶGDDR6жҳҫеӯҳ пјҢ дёҚиҝҮдёҚеҗҢдәҺRTX 3080зҡ„Micron пјҢ RTX 3060 TiйҮҮз”ЁдәҶдёүжҳҹзҡ„GDDR6жҳҫеӯҳ гҖӮ
жҲ‘们еңЁеҸ‘еёғдјҡдёӯз»Ҹеёёеҗ¬еҲ°жҖ§иғҪзҝ»еҖҚзҡ„иҜҙжі• пјҢ е…¶е®һжҳҜеӣ дёәжң¬ж¬ЎNVIDIA Ampereзҡ„SMеңЁTuringеҹәзЎҖдёҠеўһеҠ дәҶдёҖеҖҚзҡ„FP32иҝҗз®—еҚ•е…ғ пјҢ иҝҷе°ұдҪҝеҫ—жҜҸдёӘSMзҡ„FP32иҝҗз®—еҚ•е…ғж•°йҮҸжҸҗй«ҳдәҶдёҖеҖҚ пјҢ еҗҢж—¶еҗһеҗҗйҮҸд№ҹе°ұеҸҳдёәдәҶдёҖеҖҚ гҖӮ
иҖҢйҖҡеёёжҲ‘们计算жҳҫеҚЎзҡ„CUDAж•°йҮҸ пјҢ 并дёҚжҳҜжҠҠSMдёӯзҡ„жүҖжңүеҚ•е…ғеҠ иө·жқҘи®Ўж•° пјҢ иҖҢжҳҜеҸӘз»ҹи®ЎFP32еҚ•е…ғзҡ„ж•°йҮҸ пјҢ жүҖд»Ҙиҝҷж ·дёҖжқҘ пјҢ SMдёӯзҡ„гҖҗFP32 : INT32гҖ‘ д»Һ 1:1 еҸҳдёә 2:1 гҖӮ
RTX 3060 Tiе…ұжңү4864дёӘCUDA пјҢ е…¶е®һе®ғжңү2432дёӘINT32еҚ•е…ғ пјҢ дҪҶз”ұдәҺеҶ…йғЁзҡ„FP32ж•°йҮҸзҝ»дәҶдёҖеҖҚ пјҢ жүҖд»ҘжңҖз»Ҳе®һзҺ°дәҶ4864иҝҷдёӘжғҠдәәзҡ„ж•°еӯ— гҖӮ
иҖҢиҝҷж ·зІ—жҡҙзҡ„жҸҗеҚҮCUDAж•°йҮҸеҜ№дәҺжёёжҲҸе…¶е®һжңүзқҖйқһеёёеӨ§зҡ„её®еҠ© пјҢ йҖҡеёёеңЁжёёжҲҸдёӯжө®зӮ№иҝҗз®—зӣёжҜ”ж•ҙж•°и®Ўз®—иҰҒеёёз”Ёзҡ„еӨҡ пјҢ еӣҫеҪўгҖҒз®—жі•д»ҘеҸҠеҗ„з§Қи®Ўз®—ж“ҚдҪңдёӯзқҖиүІеҷЁе·ҘдҪңиҙҹиҪҪйҖҡеёёйңҖиҰҒж··еҗҲдҪҝз”ЁFP32з®—ж•°жҢҮд»Ө пјҢ иҖҢFP32зҡ„еҠ йҖҹд№ҹжңүеҠ©дәҺе…үзәҝиҝҪиёӘйҷҚеҷӘзқҖиүІеҷЁ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
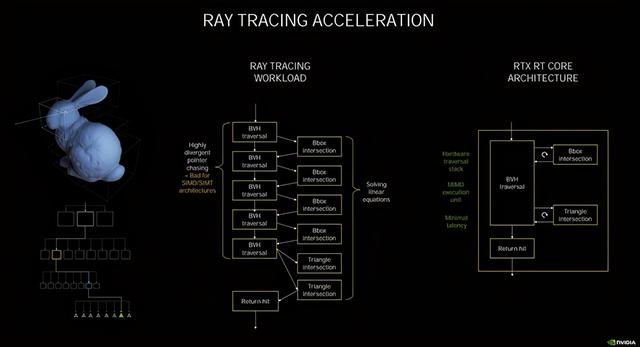
е…үиҝҪе·ҘдҪңеҺҹзҗҶзӨәж„Ҹ
еңЁжӯӨж¬Ўзҡ„NVIDIA Ampereжһ¶жһ„дёӯ пјҢ NVIDIAе®ҳж–№е®Јеёғдёә第дәҢд»ЈRT Core пјҢ е®ғе’Ң第дёҖд»Јжңүд»Җд№ҲдёҚеҗҢе‘ў гҖӮ йҰ–е…ҲиҰҒзҹҘйҒ“RT Coreзҡ„е·ҘдҪңеҺҹзҗҶжҳҜ пјҢ зқҖиүІеҷЁеҸ‘еҮәе…үзәҝиҝҪиёӘзҡ„иҜ·жұӮ пјҢ дәӨз»ҷRT CoreжқҘеӨ„зҗҶ пјҢ е®ғе°ҶиҝӣиЎҢдёӨз§ҚжөӢиҜ• пјҢ еҲҶеҲ«дёәиҫ№з•ҢдәӨеҸүжөӢиҜ•пјҲBox Intersection testingпјүе’Ңдёүи§’еҪўдәӨеҸүжөӢиҜ•пјҲTriangle Intersection testingпјү гҖӮ еҹәдәҺBVHз®—жі•жқҘеҲӨж–ӯ пјҢ еҰӮжһңжҳҜж–№еҪў пјҢ йӮЈд№Ҳе°ұиҝ”еӣһзј©е°ҸиҢғеӣҙ继з»ӯжөӢиҜ• пјҢ еҰӮжһңжҳҜдёүи§’еҪў пјҢ еҲҷеҸҚйҰҲз»“жһңиҝӣиЎҢжёІжҹ“ гҖӮ
иҖҢе…үзәҝиҝҪиёӘжңҖиҖ—ж—¶зҡ„жӯЈжҳҜжұӮдәӨи®Ўз®— пјҢ еӣ жӯӨ пјҢ иҰҒжҸҗеҚҮе…үзәҝиҝҪиёӘжҖ§иғҪ пјҢ дё»иҰҒжҳҜеҜ№дёӨз§ҚжұӮдәӨпјҲBVH/дёүи§’еҪўжұӮдәӨпјүиҝӣиЎҢеҠ йҖҹ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
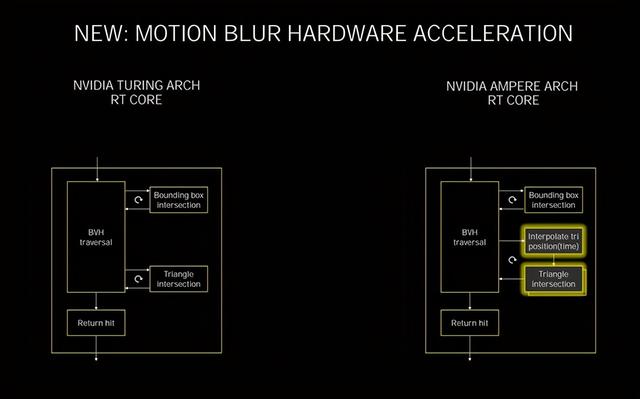
RT Coreзҡ„еҸҳеҢ–
еңЁTuringзҡ„RT Coreдёӯ пјҢ еҸҜд»ҘжҜҸдёӘе‘Ёжңҹе®ҢжҲҗ5ж¬ЎBVHйҒҚеҺҶгҖҒ4ж¬ЎBVHжұӮдәӨд»ҘеҸҠдёҖж¬Ўдёүи§’еҪўжұӮдәӨ пјҢ еңЁз¬¬дәҢд»ЈRT Core йҮҢ пјҢ NVIDIAеўһеҠ дәҶдёҖдёӘж–°зҡ„дёүи§’еҪўдҪҚзҪ®жҸ’еҖјжЁЎеқ—д»ҘеҸҠдёҖдёӘзҡ„йўқеӨ–зҡ„дёүи§’еҪўжұӮдәӨжЁЎеқ— пјҢ иҝҷж ·еҒҡзҡ„зӣ®зҡ„жҳҜдёәдәҶжҸҗеҚҮиҜёеҰӮиҝҗеҠЁжЁЎзіҠзү№ж•Ҳж—¶еҖҷзҡ„е…үзәҝиҝҪиёӘжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
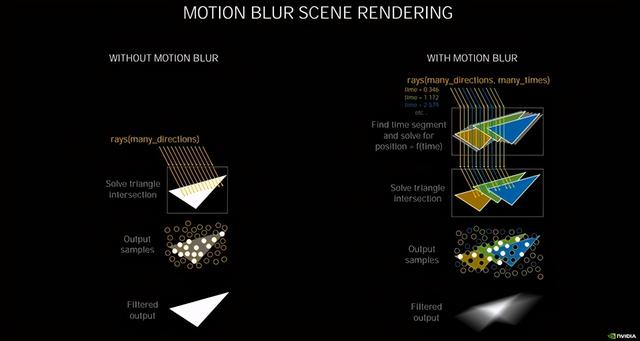
иҝҗеҠЁжЁЎзіҠжёІжҹ“еҺҹзҗҶ
第дәҢд»ЈRT CoreеҸҜд»Ҙи®©е…үзәҝиҝҪиёӘдёҺзқҖиүІеҗҢж—¶иҝӣиЎҢ пјҢ иҝӣиЎҢзҡ„е…үзәҝиҝҪиёӘи¶ҠеӨҡ пјҢ еҠ йҖҹе°ұи¶Ҡеҝ« пјҢ е®ғе°Ҷе…үзәҝзӣёдәӨзҡ„еӨ„зҗҶжҖ§иғҪжҸҗеҚҮдәҶдёҖеҖҚ пјҢ еңЁжёІжҹ“жңүеҠЁжҖҒжЁЎзіҠзҡ„еҪұеғҸж—¶ пјҢ жҢүз…§NVIDIAиҮӘе·ұзҡ„е®һжөӢ пјҢ жҜ”Turingеҝ«8еҖҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»














- еҚҺзЎ•RTX 3060 Ultra 12GB GDDR6жҳҫеҚЎжӣқе…ү жҲ–е”®449зҫҺе…ғ
- RTX 3060зӘҒ然改еҗҚRTX 3060 UltraпјҒ12GBжҳҫеӯҳи¶…иҝҮRTX 3080
- еҫ®жҳҹйў„зғӯж–°дёҖд»ЈжёёжҲҸжң¬пјҡRTX 30зі»жҳҫеҚЎзҺӢиҖ…йҷҚдёҙ
- TACHYжҠ«йңІVortex 15жёёжҲҸ笔记жң¬пјҡR7-5800HдёҺRTX 3060еҠ жҢҒ
- еҫ®жҳҹеҖҫе…ЁеҠӣжү“йҖ зҡ„ж——иҲ°пјҒеҫ®жҳҹRTX 3080и¶…йҫҷиҜ„жөӢпјҡ4KиҝҪе№іRX 6900 XT
- зҲҪзҺ©е…үиҝҪеӨ§дҪңпјҢRTX 3060TiжҖ§д»·жҜ”з”өи„‘жҺЁиҚҗ
- RTX 3080/3070笔记жң¬жҳҫеҚЎи§„ж је®һй”ӨпјҡеӨ§е№…йҳүеүІ
- еҰҲеҰҲеҝғзҒөжүӢе·§ дёәе„ҝеӯҗеҲ¶дҪңRTX3080йҖ еһӢз”ҹж—ҘиӣӢзі•
- й“ӯз‘„RTX 3060 Ti iCraft OC еҝғд№ӢжүҖеҗ‘ж— з•Ҹж— еҸҢ
- еҪұй©°еҸ‘еёғз»Ҹе…ёзүҲRTX 3090/3080пјҡжҡҙеҠӣж¶ЎиҪ®йЈҺжүҮжҲҗдәҶж–°жҪ®