жңүе…іиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„ж·ұеәҰеӯҰд№ зҹҘиҜҶжңүе“Әдәӣпјҹ( дёғ )
иҝҳжңүи®ёеӨҡе…¶д»–зҡ„жҝҖжҙ»еҮҪж•° пјҢ еҰӮеҸҢжӣІжӯЈеҲҮеҮҪж•°е’Ңдҝ®жӯЈзәҝжҖ§еҚ•е…ғеҮҪж•° пјҢ е®ғ们еҗ„жңүдјҳеҠЈ пјҢ йҖӮз”ЁдәҺдёҚеҗҢзҡ„зҘһз»ҸзҪ‘з»ңз»“жһ„ пјҢ еӨ§е®¶е°ҶеңЁд№ӢеҗҺзҡ„з« иҠӮдёӯеӯҰд№ гҖӮ
дёәд»Җд№ҲиҰҒжұӮеҸҜеҫ®е‘ўпјҹеҰӮжһңиғҪеӨҹи®Ўз®—еҮәиҝҷдёӘеҮҪж•°зҡ„еҜјж•° пјҢ е°ұиғҪеҜ№еҮҪж•°дёӯзҡ„еҗ„дёӘеҸҳйҮҸжұӮеҒҸеҜјж•° гҖӮ иҝҷйҮҢзҡ„е…ій”®жҳҜвҖңеҗ„дёӘеҸҳйҮҸвҖқ пјҢ иҝҷж ·е°ұиғҪйҖҡиҝҮжҺҘ收еҲ°зҡ„иҫ“е…ҘжқҘжӣҙж–°жқғйҮҚпјҒ
7пјҺжұӮеҜјйҰ–е…Ҳз”Ёе№іж–№иҜҜе·®дҪңдёәд»Јд»·еҮҪж•°жқҘи®Ўз®—зҪ‘з»ңзҡ„иҜҜе·® пјҢ еҰӮе…¬ејҸ5-5жүҖзӨә[12]пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ5-5гҖҖеқҮж–№иҜҜе·®
然еҗҺеҲ©з”Ёеҫ®з§ҜеҲҶй“ҫејҸжі•еҲҷи®Ўз®—еӨҚеҗҲеҮҪж•°зҡ„еҜјж•° пјҢ еҰӮе…¬ејҸ5-6жүҖзӨә гҖӮ зҪ‘з»ңжң¬иә«еҸӘдёҚиҝҮжҳҜеҮҪж•°зҡ„еӨҚеҗҲпјҲзӮ№з§Ҝд№ӢеҗҺзҡ„йқһзәҝжҖ§жҝҖжҙ»еҮҪж•°пјү гҖӮ
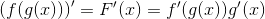 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ5-6гҖҖй“ҫејҸжі•еҲҷ
жҺҘдёӢжқҘеҸҜд»Ҙз”ЁиҝҷдёӘе…¬ејҸи®Ўз®—жҜҸдёӘзҘһз»Ҹе…ғдёҠжҝҖжҙ»еҮҪж•°зҡ„еҜјж•° гҖӮ йҖҡиҝҮиҝҷдёӘж–№жі•еҸҜд»Ҙи®Ўз®—еҮәеҗ„дёӘжқғйҮҚеҜ№жңҖз»ҲиҜҜе·®зҡ„иҙЎзҢ® пјҢ д»ҺиҖҢиҝӣиЎҢйҖӮеҪ“зҡ„и°ғж•ҙ гҖӮ
еҰӮжһңиҜҘеұӮжҳҜиҫ“еҮәеұӮ пјҢ еҖҹеҠ©дәҺеҸҜеҫ®зҡ„жҝҖжҙ»еҮҪж•° пјҢ жқғйҮҚзҡ„жӣҙж–°жҜ”иҫғз®ҖеҚ• пјҢ еҜ№дәҺ第jдёӘиҫ“еҮә пјҢ иҜҜе·®зҡ„еҜјж•°еҰӮдёӢ[13]пјҡ
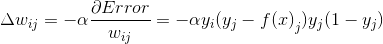 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ5-7гҖҖиҜҜе·®еҜјж•°
еҰӮжһңиҰҒжӣҙж–°йҡҗи—ҸеұӮзҡ„жқғйҮҚ пјҢ еҲҷдјҡзЁҚеҫ®еӨҚжқӮдёҖзӮ№е„ҝ пјҢ еҰӮе…¬ејҸ5-8жүҖзӨәпјҡ
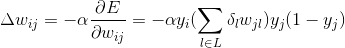 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ5-8гҖҖеүҚдёҖеұӮзҡ„еҜјж•°
еңЁе…¬ејҸ5-7дёӯ пјҢ еҮҪж•°f(x)иЎЁзӨәе®һйҷ…з»“жһңеҗ‘йҮҸ пјҢ f(x)jиЎЁзӨәиҜҘеҗ‘йҮҸ第jдёӘдҪҚзҪ®дёҠзҡ„еҖј пјҢ yiгҖҒyjжҳҜеҖ’数第дәҢеұӮ第iдёӘиҠӮзӮ№е’Ңиҫ“еҮә第jдёӘиҠӮзӮ№зҡ„иҫ“еҮә пјҢ иҝһжҺҘиҝҷдёӨдёӘиҠӮзӮ№зҡ„жқғйҮҚдёәwij пјҢ иҜҜе·®д»Јд»·еҮҪж•°еҜ№wijжұӮеҜјзҡ„з»“жһңзӣёеҪ“дәҺз”ЁОұпјҲеӯҰд№ зҺҮпјүд№ҳд»ҘеүҚдёҖеұӮзҡ„иҫ“еҮәеҶҚд№ҳд»ҘеҗҺдёҖеұӮд»Јд»·еҮҪж•°зҡ„еҜјж•° гҖӮ е…¬ејҸ5-8дёӯОҙlиЎЁзӨәLеұӮ第lдёӘиҠӮзӮ№дёҠзҡ„иҜҜе·®йЎ№ пјҢ еүҚдёҖеұӮ第jдёӘиҠӮзӮ№еҲ°LеұӮжүҖжңүзҡ„иҠӮзӮ№иҝӣиЎҢеҠ жқғжұӮе’Ң[14] гҖӮ
йҮҚиҰҒзҡ„жҳҜиҰҒжҳҺзЎ®дҪ•ж—¶жӣҙж–°жқғйҮҚ гҖӮ еңЁи®Ўз®—жҜҸдёҖеұӮдёӯжқғйҮҚзҡ„жӣҙж–°ж—¶ пјҢ йңҖиҰҒдҫқиө–зҪ‘з»ңеңЁеүҚеҗ‘дј ж’ӯдёӯзҡ„еҪ“еүҚзҠ¶жҖҒ гҖӮ дёҖж—Ұи®Ўз®—еҮәиҜҜе·® пјҢ жҲ‘们е°ұеҸҜд»Ҙеҫ—еҲ°зҪ‘з»ңдёӯеҗ„дёӘжқғйҮҚзҡ„жӣҙж–°еҖј пјҢ дҪҶд»Қ然йңҖиҰҒеӣһеҲ°зҪ‘з»ңзҡ„иө·е§ӢиҠӮзӮ№жүҚиғҪеҺ»еҒҡжӣҙж–° гҖӮ еҗҰеҲҷ пјҢ еҰӮжһңеңЁзҪ‘з»ңжң«з«Ҝжӣҙж–°жқғйҮҚ пјҢ еүҚйқўи®Ўз®—зҡ„еҜјж•°е°ҶдёҚеҶҚжҳҜеҜ№дәҺжң¬иҫ“е…Ҙзҡ„жӯЈзЎ®зҡ„жўҜеәҰ гҖӮ еҸҰеӨ– пјҢ д№ҹеҸҜд»Ҙе°ҶжқғйҮҚеңЁжҜҸдёӘи®ӯз»ғж ·жң¬дёҠзҡ„еҸҳеҢ–еҖји®°еҪ•дёӢжқҘ пјҢ е…¶й—ҙдёҚеҒҡд»»дҪ•жӣҙж–° пјҢ зӯүи®ӯз»ғз»“жқҹеҗҺеҶҚдёҖиө·жӣҙж–° пјҢ жҲ‘们е°ҶеңЁ5.1.6иҠӮдёӯи®Ёи®әиҝҷйЎ№еҶ…е®№ гҖӮ
жҺҘдёӢжқҘе°Ҷе…ЁйғЁж•°жҚ®иҫ“е…ҘзҪ‘з»ңдёӯиҝӣиЎҢи®ӯз»ғ пјҢ еҫ—еҲ°жҜҸдёӘиҫ“е…ҘеҜ№еә”зҡ„иҜҜе·® пјҢ 然еҗҺе°ҶиҝҷдәӣиҜҜе·®еҸҚеҗ‘дј ж’ӯиҮіжҜҸдёӘжқғйҮҚ пјҢ ж №жҚ®иҜҜе·®зҡ„жҖ»дҪ“еҸҳеҢ–жқҘжӣҙж–°жҜҸдёӘжқғйҮҚ гҖӮ еҪ“зҪ‘з»ңеӨ„зҗҶе®Ңе…ЁйғЁзҡ„и®ӯз»ғж•°жҚ®еҗҺ пјҢ иҜҜе·®зҡ„еҸҚеҗ‘дј ж’ӯд№ҹйҡҸд№Ӣе®ҢжҲҗ пјҢ жҲ‘们е°ҶиҝҷдёӘиҝҮзЁӢз§°дёәзҘһз»ҸзҪ‘з»ңзҡ„дёҖдёӘи®ӯз»ғе‘ЁжңҹпјҲepochпјү гҖӮ жҲ‘们еҸҜд»Ҙе°Ҷж•°жҚ®йӣҶдёҖйҒҚеҸҲдёҖйҒҚең°иҫ“е…ҘзҪ‘з»ңжқҘдјҳеҢ–жқғйҮҚ гҖӮ дҪҶжҳҜиҰҒжіЁж„Ҹ пјҢ зҪ‘з»ңеҸҜиғҪдјҡеҜ№и®ӯз»ғйӣҶиҝҮжӢҹеҗҲ пјҢ еҜјиҮҙеҜ№и®ӯз»ғйӣҶеӨ–йғЁзҡ„ж–°ж•°жҚ®ж— жі•еҒҡеҮәжңүж•Ҳзҡ„йў„жөӢ гҖӮ
еңЁе…¬ејҸ5-7е’Ңе…¬ејҸ5-8дёӯ пјҢ ОұиЎЁзӨәеӯҰд№ зҺҮ гҖӮ е®ғеҶіе®ҡдәҶеңЁдёҖдёӘи®ӯз»ғе‘ЁжңҹжҲ–дёҖжү№ж•°жҚ®дёӯжқғйҮҚдёӯиҜҜе·®зҡ„дҝ®жӯЈйҮҸ гҖӮ йҖҡеёёеңЁдёҖдёӘи®ӯз»ғе‘ЁжңҹеҶ…ОұдҝқжҢҒдёҚеҸҳ пјҢ дҪҶд№ҹжңүдёҖдәӣеӨҚжқӮзҡ„и®ӯз»ғз®—жі•дјҡеҜ№ОұиҝӣиЎҢиҮӘйҖӮеә”и°ғж•ҙ пјҢ д»ҘеҠ еҝ«и®ӯз»ғйҖҹеәҰ并确дҝқ收ж•ӣ гҖӮ еҰӮжһңОұиҝҮеӨ§ пјҢ еҫҲеҸҜиғҪдјҡзҹ«жһүиҝҮжӯЈ пјҢ дҪҝдёӢдёҖж¬ЎиҜҜе·®еҸҳеҫ—жӣҙеӨ§ пјҢ еҜјиҮҙжқғйҮҚзҰ»зӣ®ж Үжӣҙиҝң гҖӮ еҰӮжһңОұи®ҫзҪ®еӨӘе°ҸдјҡдҪҝжЁЎеһӢ收ж•ӣиҝҮж…ў пјҢ жӣҙзіҹзі•зҡ„жҳҜ пјҢ еҸҜиғҪдјҡйҷ·е…ҘиҜҜе·®жӣІйқўзҡ„еұҖйғЁжһҒе°ҸеҖј гҖӮ
жң¬ж–Үж‘ҳиҮӘгҖҠиҮӘ然иҜӯиЁҖеӨ„зҗҶе®һжҲҳ еҲ©з”ЁPythonзҗҶи§ЈгҖҒеҲҶжһҗе’Ңз”ҹжҲҗж–Үжң¬гҖӢ
жҺЁиҚҗйҳ…иҜ»














- iQOO 7жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁе’Ң120Wи¶…е……пјҢ3798е…ғиө·е”®
- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- иҷҫзұійҹід№җж’ӯж”ҫеҷЁе°ҶдәҺ2жңҲ5ж—ҘеҒңжӯўжңҚеҠЎпјҢд»ҠејҖеҗҜз”ЁжҲ·иө„дә§еӨ„зҗҶйҖҡйҒ“
- RHEL 9жҸҗеҚҮдәҶx86_64еӨ„зҗҶеҷЁзҡ„е…Ҙй—ЁиҰҒжұӮ
- иҒ”жғіIdeaPad 5 Proзі»еҲ—笔记жң¬еҸ‘еёғ еҸҜйҖүдёӨз§ҚеӨ„зҗҶеҷЁе’ҢдёӨз§Қе°әеҜё
- иҒ”жғіжҺЁеҮәжҗӯиҪҪйӘҒйҫҷеӨ„зҗҶеҷЁзҡ„IdeaPad 5G
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- иӢ№жһңиҮӘз ”ж–°еӨ„зҗҶеҷЁжӣқе…үпјҡ64ж ёеҝғ
- жҺЁиҝӣ|жҲ‘еӣҪд»Ҡе№ҙе°ҶжҺЁиҝӣеҝ«йҖ’вҖңиҝӣжқ‘вҖқвҖңиҝӣеҺӮвҖқвҖңеҮәжө·вҖқжһ„е»әж—ҘеӨ„зҗҶи¶…10дәҝ件еҜ„йҖ’зҪ‘з»ң
- ж”Ҝд»ҳеӨ„зҗҶе…¬еҸёJuspayеҸ‘з”ҹж•°жҚ®жі„жјҸпјҡ1дәҝз”ЁжҲ·дҝЎжҒҜеңЁжҡ—зҪ‘еҮәе”®