爱可可AI论文推介(10月9日)( 三 )
 文章插图
文章插图
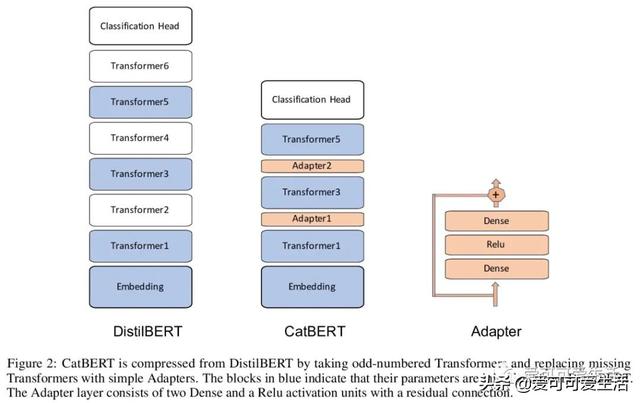 文章插图
文章插图
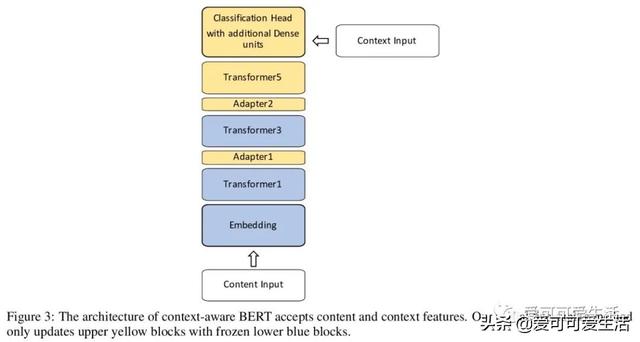 文章插图
文章插图
5、[CL]WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization
F Ladhak, E Durmus, C Cardie, K McKeown
[Columbia University & Cornell University]
跨语种抽象摘要新基准WikiLingua , 一个跨语言和多语言抽象摘要的基准数据集 , 从WikiHow中提取了18种语言的文章和摘要对 , WikiHow是个高质量的协作资源 , 提供了人工撰写的一系列不同主题的操作指南 。 通过对齐文章中用于描述每个how-to步骤的图像 , 创建了跨语言的金标准文章-摘要对齐 。
We introduce WikiLingua, a large-scale, multilingual dataset for the evaluation of crosslingual abstractive summarization systems. We extract article and summary pairs in 18 languages from WikiHow, a high quality, collaborative resource of how-to guides on a diverse set of topics written by human authors. We create gold-standard article-summary alignments across languages by aligning the images that are used to describe each how-to step in an article. As a set of baselines for further studies, we evaluate the performance of existing cross-lingual abstractive summarization methods on our dataset. We further propose a method for direct crosslingual summarization (i.e., without requiring translation at inference time) by leveraging synthetic data and Neural Machine Translation as a pre-training step. Our method significantly outperforms the baseline approaches, while being more cost efficient during inference.
 文章插图
文章插图
 文章插图
文章插图
推荐阅读


















- 谷歌:想发AI论文?请保证写的是正能量
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 2019年度中国高质量国际科技论文数排名世界第二
- 谷歌通过启动敏感话题审查来加强对旗下科学家论文的控制
- Arxiv网络科学论文摘要11篇(2020-10-12)
- 聚焦城市治理新方向,5G+智慧城市推介会在长举行
- 中国移动5G新型智慧城市全国推介会在长沙举行
- 年年都考的数字鸿沟有了新进展?彭波老师的论文给出了解答!
- 打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
- 兰州科技大市场牵线搭台,6项兰州大学科技成果在兰推介