жҗңзҙўеј•ж“Һж–°жһ¶жһ„пјҡдёҺSQLдёҚеҫ—дёҚиҜҙзҡ„ж•…дәӢ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
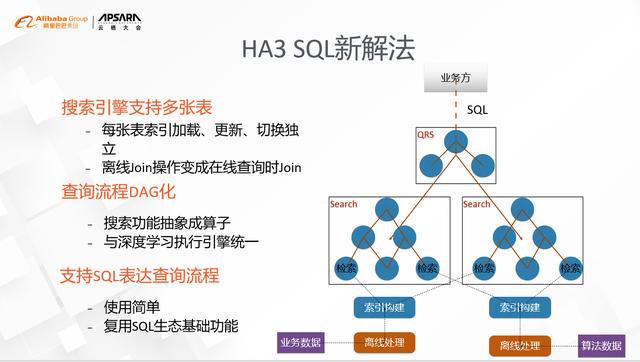
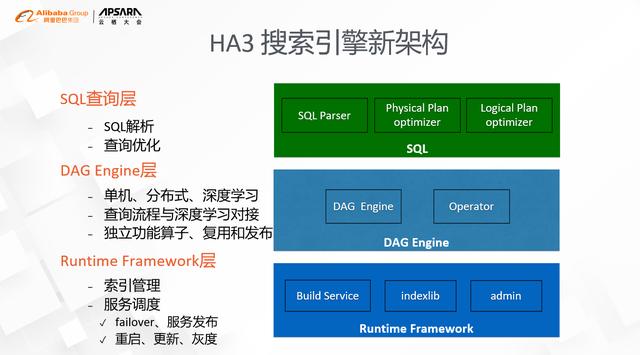
жҗңзҙўеј•ж“ҺHA3ж–°зҡ„жһ¶жһ„дё»иҰҒеҲҶдёәдёүеұӮпјҡ
- жңҖеә•дёӢдёҖеұӮжҳҜsearchRuntimeзҡ„Framework пјҢ е…¶ж ёеҝғиҒҢиҙЈдё»иҰҒжңүзҙўеј•з®ЎзҗҶе’ҢжңҚеҠЎи°ғеәҰ пјҢ е…¶дёӯзҙўеј•йғЁеҲҶдё»иҰҒжҳҜеҠ иҪҪзҡ„зӯ–з•Ҙе’ҢжҹҘиҜўжҺҘеҸЈ пјҢ еҰӮи®Ўз®—еӯҳеӮЁеҲҶзҰ»зҡ„ж”ҜжҢҒгҖҒе®һж—¶зҙўеј•жһ„е»әзҡ„ж”ҜжҢҒзӯүзӯүпјӣжңҚеҠЎи°ғеәҰдё»иҰҒеӨ„зҗҶзҡ„жҳҜиҝӣзЁӢзҡ„failoverе’ҢжңҚеҠЎзҡ„жӣҙж–° пјҢ еҚійҖҡеёёж„Ҹд№үзҡ„йқўеҗ‘з»ҲжҖҒзҡ„дәҢеұӮи°ғеәҰ пјҢ дё»иҰҒзҡ„зү№зӮ№жҳҜд»Ҙз»ҹдёҖзҡ„ж–№ејҸеҒҡиҝӣзЁӢзҡ„йҮҚеҗҜгҖҒзЁӢеәҸзҡ„жӣҙж–°гҖҒзҒ°еәҰзҡ„еҸ‘еёғзӯүзӯү гҖӮ
- дёӯй—ҙиҝҷдёҖеұӮжҳҜDAGеј•ж“ҺеұӮ пјҢ е…¶ж ёеҝғеҶ…е®№жңүдёӨдёӘ пјҢ дёҖдёӘжҳҜжү§иЎҢеј•ж“Һжң¬иә« пјҢ еҸҰдёҖдёӘе°ұжҳҜз®—еӯҗ гҖӮ иҝҷйҮҢзҡ„жү§иЎҢеј•ж“Һдё»иҰҒжңүдёүйғЁеҲҶзҡ„иғҪеҠӣ пјҢ еҢ…жӢ¬еҚ•жңәеҶ…еӣҫзҡ„жү§иЎҢ пјҢ еҲҶеёғејҸзҡ„йҖҡдҝЎе’Ңж·ұеәҰеӯҰд№ пјҢ йҖҡиҝҮз®—еӯҗй—ҙзҡ„дә’иҒ” пјҢ жҲ‘们иғҪеӨҹеҫҲж–№дҫҝзҡ„жҠҠжҗңзҙўзҡ„жҹҘиҜўжөҒзЁӢе’Ңж·ұеәҰеӯҰд№ иҝӣиЎҢеҜ№жҺҘ пјҢ е®һзҺ°ж·ұеәҰеӯҰд№ еңЁжҗңзҙўзҡ„еҗ„дёӘйҳ¶ж®өзҡ„жё—йҖҸ пјҢ еҰӮеҗ‘йҮҸжЈҖзҙўгҖҒзІ—жҺ’е’ҢзІҫжҺ’ гҖӮ з®—еӯҗйғЁеҲҶзҡ„жҠҪиұЎжҳҜиҝҷиҪ®жһ¶жһ„жҠҪиұЎжңҖйҮҚиҰҒзҡ„дёҖзҺҜ пјҢ жҠҠеҺҹжқҘйқўеҗ‘иҝҮзЁӢејҸзҡ„ејҖеҸ‘еҸҳжҲҗдәҶзӢ¬з«ӢеҠҹиғҪзҡ„ејҖеҸ‘ пјҢ дёҖж–№йқўиҰҒжұӮз®—еӯҗжң¬иә«зҡ„еҠҹиғҪиҰҒе°ҪеҸҜиғҪеҶ…иҒҡ пјҢ еҸҰдёҖж–№йқўз®—еӯҗзә§еҲ«зҡ„з®ЎзҗҶд№ҹжӣҙжңүеҲ©дәҺеҠҹиғҪзҡ„еӨҚз”Ёе’ҢеҸ‘еёғ гҖӮ
- жңҖдёҠйқўдёҖеұӮжҳҜSQLжҹҘиҜўеұӮ пјҢ ж ёеҝғзҡ„е·ҘдҪңжңүдёӨйғЁеҲҶ пјҢ дёҖдёӘжҳҜSQLи§Јжһҗ пјҢ еҸҰеӨ–дёҖдёӘжҳҜжҹҘиҜўдјҳеҢ– гҖӮ з”ұдәҺDAGзҡ„жөҒзЁӢеҸҜд»Ҙд»»ж„Ҹе®ҡеҲ¶ пјҢ еҰӮдҪ•и®©з”ЁжҲ·жӣҙж–№дҫҝең°жһ„е»әеӣҫгҖҒжӣҙж–№дҫҝзҡ„иҝӣиЎҢз®—еӯҗй—ҙзҡ„еҚҸдҪңдјҡжҳҜеҫҲе…ій”®зҡ„й—®йўҳ пјҢ з®ҖеҚ•гҖҒйҖҡз”ЁжҳҜдёӘеҝ…йЎ»иҖғиҷ‘зҡ„ пјҢ иҝҷд№ҹжҳҜжҲ‘们йҰ–йҖүSQLзҡ„еҺҹеӣ пјӣеҸҰеӨ–дёҖдёӘеҺҹеӣ жҳҜдёҡз•ҢSQLзҡ„жү§иЎҢеҷЁ пјҢ йҖҡеёёеҢ…еҗ«йҖ»иҫ‘дјҳеҢ–е’Ңзү©зҗҶдјҳеҢ–дёӨдёӘзҺҜиҠӮ пјҢ иҝҷдёӘеҜ№дёҖдёӘеӨҚжқӮзҡ„DAGзҡ„жү§иЎҢжҸҗдҫӣдәҶйқһеёёеҘҪзҡ„жҠҪиұЎ пјҢ жҲ‘们д№ҹеҲ©з”ЁдәҶиҝҷдёӘжңәеҲ¶жқҘиҝӣиЎҢдәҶеҫҲеӨҡз»ҶиҮҙзҡ„дјҳеҢ– пјҢ еҢ…жӢ¬еӣҫзҡ„еҸҳжҚўгҖҒз®—еӯҗеҗҲ并гҖҒзј–иҜ‘дјҳеҢ–зӯүзӯү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫе®һи·өжЎҲдҫӢ1. йҘҝдәҶд№ҲеӨ–еҚ–жҗңзҙўеңәжҷҜзҡ„дҫӢеӯҗ пјҢ еҒҮи®ҫз”ЁжҲ·еңЁжҗңзҙўжЎҶйҮҢйқўиҫ“е…ҘдәҶдёҖдёӘе…ій”®иҜҚ"зүӣиӮүйқў" пјҢ жҗңзҙўеј•ж“ҺеҗҺеҸ°зҡ„жөҒзЁӢеӨ§дҪ“еҰӮдёӢпјҡйҖҡиҝҮз”ЁжҲ·зҡ„дҪҚзҪ®дҝЎжҒҜжүҫеҲ°зҺ°еңЁиҝҳеңЁиҗҘдёҡзҡ„гҖҒ并且иғҪеҚ–зүӣиӮүйқўзҡ„й—Ёеә— пјҢ жҜҸдёӘй—Ёеә—з»ҷеҮәжңҖеҢ№й…Қзҡ„е•Ҷе“Ғ пјҢ жңҖеҗҺиҝ”еӣһжңҖз¬ҰеҗҲз”ЁжҲ·йңҖжұӮзҡ„й—Ёеә—дёҺе•Ҷе“Ғ гҖӮ еңЁиҝҷйҮҢ пјҢ й—Ёеә—иҗҘдёҡжғ…еҶөеҰӮдҪ•гҖҒй…ҚйҖҒиғҪеҠӣжҳҜеҗҰи¶іеӨҹгҖҒеҜ№еә”зҡ„е•Ҷе“ҒжңүжІЎжңүеҚ–е®Ң пјҢ иҝҷдәӣж•°жҚ®йғҪйңҖиҰҒе®һж—¶жӣҙж–°зҡ„ пјҢ иҖҢеңЁеӨ§и§„жЁЎзҡ„ж•°жҚ®йҮҢйқўеҝ«йҖҹжүҫеҲ°еҢ№й…Қзҡ„дҝЎжҒҜ пјҢ д№ҹж¶үеҸҠеҲ°дё°еҜҢзҡ„зҙўеј•жҠҖжңҜ пјҢ жҜ”еҰӮз©әй—ҙзҙўеј•гҖҒеҖ’жҺ’зҙўеј•гҖҒеҗ‘йҮҸзҙўеј•зӯүзӯү пјҢ жңҖеҗҺй—Ёеә—е’Ңе•Ҷе“Ғзҡ„жҺ’еәҸд№ҹиҰҒдҫқиө–ж·ұеәҰжЁЎеһӢзҡ„еҸӮдёҺ пјҢ з”ЁжҲ·зҡ„еҒҸеҘҪгҖҒдјҳжғ дҝЎжҒҜгҖҒи·қзҰ»йғҪжҳҜеҫҲйҮҚиҰҒзҡ„еӣ зҙ гҖӮ еҺҹжңүзҡ„жҗңзҙўжөҒзЁӢжҳҜеҹәдәҺelasticsearchйҖҡиҝҮеҲҶеҲ«жҹҘиҜўй—Ёеә—е’Ңе•Ҷе“Ғз»ҙеәҰзҡ„иЎЁжқҘе®һзҺ°зҡ„ пјҢ дҪҶдјҡжңүжҹҘиҜўз»“жһңжҲӘж–ӯе’Ңж·ұеәҰеӯҰд№ жҺҘе…Ҙеӣ°йҡҫзҡ„й—®йўҳ пјҢ иҖҢеңЁHA3дёҠиҝҷдәӣй—®йўҳйғҪйқһеёёе®№жҳ“и§ЈеҶі пјҢ иҝҒ移еҲ°ж–°жһ¶жһ„еҗҺ пјҢ дёҚе…үдёҡеҠЎзҡ„й•ҝе°ҫй—®йўҳж¶ҲеӨұдәҶ пјҢ иҖҢдё”жҖ§иғҪиҝҳжҸҗеҚҮ1еҖҚ пјҢ з»ҷеҗҺз»ӯз®—жі•зҡ„иҝӯд»Јз•ҷдёӢдәҶйқһеёёеӨ§зҡ„з©әй—ҙ пјҢ иҝҷйҮҢжҖ§иғҪзҡ„жҸҗеҚҮдё»иҰҒжқҘиҮӘдәҺзҙўеј•з»“жһ„е’ҢжҹҘиҜўдјҳеҢ–дёҠзҡ„дёҖдәӣе·ҘдҪң гҖӮ 2.ж·ҳе®қжң¬ең°з”ҹжҙ»зҡ„жңҚеҠЎе…¶ж ёеҝғзҡ„иҜүжұӮд№ҹжҳҜеёҢжңӣеңЁж·ҳе®қзҡ„жҗңзҙўйҮҢйқўеј•е…Ҙжң¬ең°жңҚеҠЎзҡ„жҰӮеҝө пјҢ еҰӮеӨ©зҢ«и¶…еёӮе’Ңзӣ’马зҡ„е°Ҹж—¶иҫҫзҡ„дёҡеҠЎ пјҢ йҖҡиҝҮе°Ҷй—Ёеә—е’Ңе•Ҷе“Ғз»ҙеәҰзҡ„ж•°жҚ®еҚ•зӢ¬еҲҶжӢҶ пјҢ дёҚе…үжӣҙж–°иғҪеҠӣжҸҗеҚҮдәҶдёӨдёӘж•°йҮҸзә§ пјҢ иҝҳеӨҚз”ЁдәҶйҘҝдәҶд№Ҳжҗңзҙўзҡ„еҫҲеӨҡеҠҹиғҪ гҖӮ 3.й’үй’үзҡ„й’үзӣҳжҗңзҙўдёҡеҠЎдёҠйңҖиҰҒеңЁдј з»ҹзҡ„жҗңзҙўдёҠж”ҜжҢҒй’үзӣҳж–Ү件зҡ„жқғйҷҗжҺ§еҲ¶ пјҢ з”ұдәҺж–Ү件е’ҢжқғйҷҗиҝҷдёӨдёӘз»ҙеәҰж•°жҚ®зҡ„规模йғҪйқһеёёеӨ§ пјҢ иҖҢдё”жӣҙж–°жҜ”иҫғйў‘з№Ғ пјҢ йҖҡиҝҮHA3SQLеңЁзәҝзҡ„е®һж—¶жң¬ең°join пјҢ йқһеёёдҪҺ延иҝҹзҡ„и§ЈеҶідәҶиҝҷдёӘй—®йўҳ гҖӮ 4.еҶ…йғЁзӣ‘жҺ§зі»з»ҹеҺҹжқҘжҳҜеҹәдәҺејҖжәҗжҠҖжңҜdruidжһ„е»әзҡ„ пјҢ дҪҶдёҡеҠЎи§„жЁЎдёҠжқҘйҖҗжӯҘдёҚиғҪж»Ўи¶ійңҖжұӮдәҶ пјҢ з»ҸеёёеҮәзҺ°ејӮеёёйңҖиҰҒжүӢеҠЁеӨ„зҗҶзҡ„жғ…еҶө пјҢ жҲ‘们еңЁHA3зҡ„еҹәзЎҖдёҠжү©еұ•дәҶж—¶еәҸж•°жҚ®зҙўеј• пјҢ еҖҹеҠ©SQL并иЎҢжү§иЎҢзҡ„иғҪеҠӣ пјҢ latencyжңүдәҶжҳҺжҳҫдёӢйҷҚ пјҢ зЁіе®ҡжҖ§д№ҹеҫ—еҲ°дәҶиҙЁзҡ„жҸҗеҚҮ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- NVIDIA 5nmжһ¶жһ„зҢӣж–ҷпјҡжөҒеӨ„зҗҶеҷЁи¶…1.84дёҮдёӘ
- MIPSжһ¶жһ„еҺӮе•Ҷж—ҘжёҗејҸеҫ® LinuxжҠҘе‘Ҡе…¶жјҸжҙһйҒӯйҒҮеӣ°йҡҫ
- NVIDIA 5nmжһ¶жһ„зҢӣж–ҷжӣқе…үпјҡ1.84дёҮдёӘж ёеҝғ
- е–өеҚҡеЈ«иө„и®Ҝ | дёӯеӣҪжүӢжңәеңЁеҚ°еәҰй”ҖйҮҸдёҚйҷҚеҸҚеҚҮпјӣиӢұдјҹиҫҫжӯЈи§„еҲ’5nmжһ¶жһ„жҳҫеҚЎ
- MIUI 12.5еҚҮзә§е…үй”ҘеҠЁж•Ҳжһ¶жһ„пјҡи°ҒдёҺдәүй”Ӣ
- AMD Zen3жһ¶жһ„й”җйҫҷ5000Hи·‘еҲҶжӣқе…үпјҡеҚ•ж ёжҖ§иғҪжҡҙж¶Ёиҝ‘40пј…
- иӢ№жһңжӯЈеңЁз ”еҸ‘зҡ„жҗңзҙўеј•ж“ҺиғҪе№Ізҡ„иҝҮи°·жӯҢеҗ—пјҹ
- AMDзЎ®и®ӨZen3жһ¶жһ„ж–°дёҖд»Јй”җйҫҷзәҝзЁӢж’•иЈӮиҖ…еӨ„зҗҶеҷЁпјҡиҰҒжҳҺе№ҙи§ҒдәҶ
- зҫҺеӣў|зҺӢж…§ж–ҮйҖҖдј‘ зҫҺеӣўи°ғж•ҙз»„з»Үжһ¶жһ„