жҗңзҙўеј•ж“Һж–°жһ¶жһ„пјҡдёҺSQLдёҚеҫ—дёҚиҜҙзҡ„ж•…дәӢ
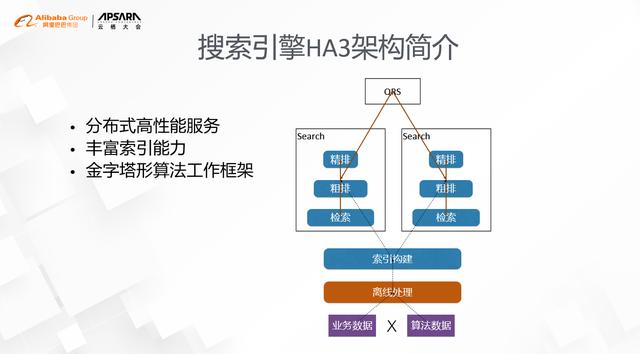
йҳҝйҮҢе·ҙе·ҙжҗңзҙўеј•ж“ҺHA3жһ¶жһ„1.HA3жһ¶жһ„еҲҶдёәеңЁзәҝе’ҢзҰ»зәҝдёӨйғЁеҲҶ
- еңЁзәҝжҳҜдёҖдёӘдј з»ҹзҡ„2еұӮжңҚеҠЎжһ¶жһ„ пјҢ еҲҶеҲ«еҸ«еҒҡQRSе’Ңsearch гҖӮ QRSиҙҹиҙЈжҺҘеҸ—з”ЁжҲ·иҜ·жұӮ пјҢ еҒҡдёҖдәӣз®ҖеҚ•еӨ„зҗҶд№ӢеҗҺжҠҠиҜ·жұӮеҸ‘з»ҷдёӢйқўзҡ„searchиҠӮзӮ№ пјҢ searchиҠӮзӮ№иҙҹиҙЈеҠ иҪҪзҙўеј•е№¶е®ҢжҲҗжЈҖзҙў пјҢ жңҖз»Ҳз”ұQRSжұҮйӣҶеҗ„дёӘsearchиҠӮзӮ№зҡ„з»“жһң并иҝ”еӣһз»ҷз”ЁжҲ· гҖӮ
- зҰ»зәҝйғЁеҲҶеҲҶдёәдёӨдёӘзҺҜиҠӮ пјҢ дёҖдёӘзҺҜиҠӮжҳҜж•°жҚ®зҡ„йў„еӨ„зҗҶ пјҢ е…¶ж ёеҝғзҡ„е·ҘдҪңжҳҜжҠҠдёҡеҠЎе’Ңз®—жі•з»ҙеәҰзҡ„ж•°жҚ®еҠ е·ҘжҲҗеҜ№зҙўеј•еҸӢеҘҪзҡ„еӨ§е®ҪиЎЁ пјҢ еҸҰдёҖдёӘзҺҜиҠӮжҳҜзҙўеј•зҡ„жһ„е»ә пјҢ е®ғзҡ„дё»иҰҒжҢ‘жҲҳжҳҜж—ўиҰҒж”ҜжҢҒеӨ§и§„жЁЎзҡ„зҙўеј•жӣҙж–° пјҢ д№ҹиҰҒдҝқйҡңзҙўеј•жҳҜе®һж—¶жҖ§ гҖӮ
- 第дёҖдёӘжҳҜй«ҳжҖ§иғҪзҡ„жңҚеҠЎжһ¶жһ„пјӣ
- 第дәҢдёӘжҳҜдё°еҜҢзҡ„зҙўеј•иғҪеҠӣпјӣ
- 第дёүдёӘжҳҜйҮ‘еӯ—еЎ”еҪўзҡ„з®—жі•е·ҘдҪңжЎҶжһ¶
 ж–Үз« жҸ’еӣҫ
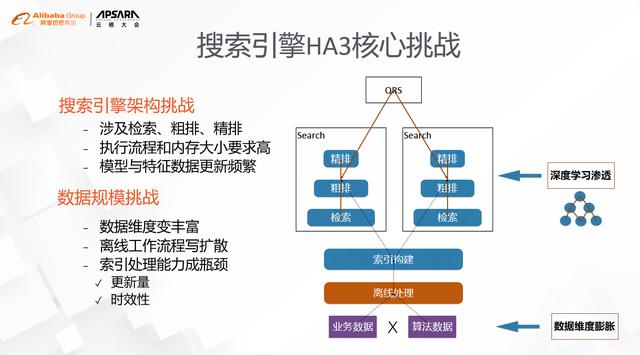
ж–Үз« жҸ’еӣҫжҗңзҙўеј•ж“ҺHA3ж ёеҝғжҢ‘жҲҳе…·дҪ“дҪ“зҺ°еңЁ2дёӘж–№йқў пјҢ дёҖдёӘжҳҜж·ұеәҰеӯҰд№ зҡ„жё—йҖҸ пјҢ еҸҰдёҖдёӘжҳҜж•°жҚ®з»ҙеәҰзҡ„иҶЁиғҖ гҖӮ
гҖҗжҗңзҙўеј•ж“Һж–°жһ¶жһ„пјҡдёҺSQLдёҚеҫ—дёҚиҜҙзҡ„ж•…дәӢгҖ‘1. ж·ұеәҰеӯҰд№
е®ғзҡ„дҪҝз”ЁиҢғеӣҙ пјҢ д»Һж—©жңҹзҡ„зІҫжҺ’ пјҢ йҖҗжӯҘжү©ж•ЈеҲ°дәҶзІ—жҺ’гҖҒжЈҖзҙў пјҢ жҜ”еҰӮеҗ‘йҮҸзҙўеј•зҡ„еҸ¬еӣһ гҖӮ ж·ұеәҰеӯҰд№ зҡ„еј•е…Ҙжң¬иә«д№ҹдјҡеёҰжқҘ2дёӘй—®йўҳпјҡдёҖдёӘжҳҜж·ұеәҰжЁЎеһӢзҡ„жң¬иә«зҡ„зҪ‘з»ңз»“жһ„йҖҡеёёжҜ”иҫғеӨҚжқӮ пјҢ еҜ№жү§иЎҢжөҒзЁӢе’ҢжЁЎеһӢеӨ§е°ҸйғҪжңүйқһеёёй«ҳзҡ„иҰҒжұӮ пјҢ дј з»ҹзҡ„pipelineе·ҘдҪңжЁЎејҸжҳҜйқһеёёйҡҫд»Ҙжңүж•Ҳж”ҜжҢҒзҡ„пјӣеҸҰеӨ–дёҖдёӘй—®йўҳжҳҜжЁЎеһӢе’Ңзү№еҫҒж•°жҚ®зҡ„е®һж—¶жӣҙж–°д№ҹеҜ№зҙўеј•зҡ„иғҪеҠӣжҸҗеҮәдәҶеҫҲеӨ§зҡ„жҢ‘жҲҳ пјҢ еңЁзәҝдёҠзҷҫдәҝзә§еҲ«зҡ„жӣҙж–°жҳҜдёҖдёӘеёёжҖҒ гҖӮ
2. ж•°жҚ®з»ҙеәҰзҡ„иҶЁиғҖ
д»Ҙз”өе•ҶйўҶеҹҹдёәдҫӢ пјҢ еҺҹжқҘиҖғиҷ‘зҡ„з»ҙеәҰдё»иҰҒжҳҜ买家гҖҒеҚ–家иҝҷдёӨдёӘз»ҙеәҰ пјҢ зҺ°еңЁеҫ—иҖғиҷ‘дҪҚзҪ®гҖҒй…ҚйҖҒгҖҒй—Ёеә—гҖҒеұҘзәҰзӯүзӯү пјҢ еҗҢж ·жҳҜй…ҚйҖҒ пјҢ жңү3е…¬йҮҢ5е…¬йҮҢйҖҒзҡ„ пјҢ жңүеҗҢеҹҺзҡ„ пјҢ иҝҳжңүи·ЁеҹҺзҡ„ пјҢ еғҸиҝҷж ·зҡ„дҫӢеӯҗиҝҳжңүеҫҲеӨҡ гҖӮ иҖҢжҗңзҙўеј•ж“ҺзҰ»зәҝзҡ„е·ҘдҪңжөҒзЁӢдјҡжҠҠеҗ„дёӘз»ҙеәҰзҡ„ж•°жҚ®joinжҲҗдёҖеј еӨ§е®ҪиЎЁ пјҢ иҝҷдјҡеҜјиҮҙж•°жҚ®жӣҙж–°зҡ„规模жҲҗз¬ӣеҚЎе°”з§Ҝзҡ„еҪўејҸеұ•ејҖ пјҢ еңЁж–°еңәжҷҜдёӢ пјҢ ж— и®әжҳҜжӣҙж–°зҡ„йҮҸзә§иҝҳжҳҜж—¶ж•ҲжҖ§дёҠйғҪеҫҲйҡҫж»Ўи¶і гҖӮ
 ж–Үз« жҸ’еӣҫ
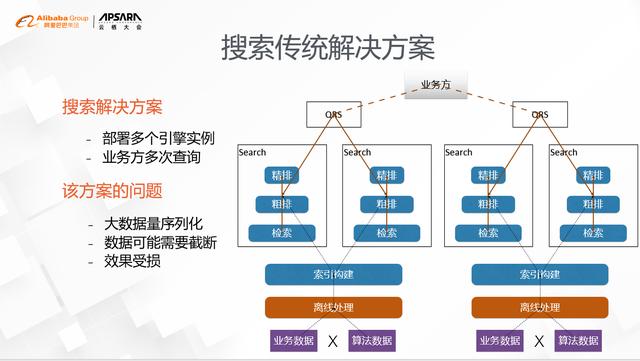
ж–Үз« жҸ’еӣҫжҗңзҙўдј з»ҹи§ЈеҶіж–№жЎҲе°ұжҳҜж №жҚ®дёҡеҠЎж•°жҚ®з»ҙеәҰзҡ„зү№зӮ№ пјҢ жҠҠеј•ж“ҺеҲҶжӢҶжҲҗиҝҮеӨҡдёӘдёҚеҗҢзҡ„е®һдҫӢ пјҢ 然еҗҺеңЁдёҡеҠЎеұӮйҖҡиҝҮжҹҘиҜўдёҚеҗҢзҡ„еј•ж“Һе®һдҫӢжқҘеҫ—еҲ°з»“жһң гҖӮ жҜ”еҰӮиҜҙйҘҝдәҶд№Ҳзҡ„жҗңзҙўеј•ж“Һе°ұжңүй—Ёеә—гҖҒе•Ҷе“Ғзӯүз»ҙеәҰзҡ„ж•°жҚ® пјҢ дёәдәҶи§ЈеҶій—Ёеә—зҠ¶жҖҒзҡ„е®һж—¶еҸҳеҢ–еҜ№зҙўеј•зҡ„еҶІеҮ» пјҢ еҸҜд»ҘйғЁзҪІдёӨдёӘжҗңзҙўеј•ж“Һе®һдҫӢ пјҢ дёҖдёӘз”ЁжқҘжҗңзҙўеҗҲйҖӮзҡ„й—Ёеә— пјҢ еҸҰеӨ–дёҖдёӘз”ЁжқҘжҗңзҙўеҗҲйҖӮзҡ„е•Ҷе“Ғ пјҢ з”ұдёҡеҠЎж–№е…ҲжҹҘй—Ёеә—еј•ж“ҺеҶҚжҹҘе•Ҷе“Ғеј•ж“ҺжқҘе®ҢжҲҗ гҖӮ дҪҶиҝҷдёӘж–№жЎҲжңүдёҖдёӘжҳҺжҳҫзҡ„зјәзӮ№ пјҢ йӮЈе°ұжҳҜз¬ҰеҗҲз”ЁжҲ·ж„Ҹеӣҫзҡ„й—Ёеә—йқһеёёеӨҡзҡ„ж—¶еҖҷ пјҢ й—Ёеә—зҡ„ж•°жҚ®йңҖиҰҒд»Һй—Ёеә—еј•ж“ҺеәҸеҲ—еҢ–еҲ°дёҡеҠЎж–№еҶҚеҸ‘йҖҒз»ҷе•Ҷе“Ғеј•ж“Һ пјҢ иҝҷйҮҢеәҸеҲ—еҢ–зҡ„ејҖй”ҖйқһеёёеӨ§ пјҢ еҫҖеҫҖйңҖиҰҒеҜ№иҝ”еӣһзҡ„й—Ёеә—ж•°зӣ®еҒҡдёҖе®ҡжҲӘж–ӯ пјҢ иҖҢжҲӘж–ӯзҡ„й—Ёеә—дёӯеҫҲеҸҜиғҪжңүжӣҙеҢ№й…Қз”ЁжҲ·ж„Ҹеӣҫзҡ„ пјҢ иҝҷж ·еҜ№дёҡеҠЎж•Ҳжһңд№ҹдјҡжңүжҜ”иҫғеӨ§зҡ„еҪұе“Қ гҖӮ зү№еҲ«зғӯй—Ёзҡ„е•ҶеҢә пјҢ дёҚз®ЎжҳҜеҜ№з”ЁжҲ·иҝҳжҳҜеҚ–家 пјҢ йғҪжҳҜйқһеёёеӨ§зҡ„жҚҹеӨұ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫHA3 SQLж–°зҡ„и§ЈеҶіж–№жЎҲд»Ҙж•°жҚ®еә“SQLзҡ„жү§иЎҢж–№ејҸжқҘйҮҚеЎ‘жҗңзҙў пјҢ ж ёеҝғиҰҒзӮ№жңү3жқЎ гҖӮ
1.е°ҶеҺҹжқҘеёҰе®ҪиЎЁзҡ„жЁЎејҸжү©еұ•жҲҗж”ҜжҢҒеӨҡиЎЁ пјҢ жҜҸдёӘиЎЁзҡ„зҙўеј•еҠ иҪҪгҖҒжӣҙж–°гҖҒеҲҮжҚўеҒҡеҲ°зӣёдә’зӢ¬з«Ӣ пјҢ жҠҠеҺҹжқҘйңҖиҰҒзҰ»зәҝjoinзҡ„ж“ҚдҪңеҸҳжҲҗеңЁзәҝжҹҘиҜўж—¶join гҖӮ2.еҪ»еә•жҠӣејғеҺҹжңүзҡ„pipelineзҡ„е·ҘдҪңжЁЎејҸ пјҢ д»ҘDAGеӣҫеҢ–зҡ„ж–№ејҸжқҘжү§иЎҢ пјҢ 并е°Ҷжҗңзҙўзҡ„еҠҹиғҪжҠҪиұЎжҲҗдёҖдёӘдёӘзӢ¬з«Ӣзҡ„з®—еӯҗ пјҢ дёҺж·ұеәҰеӯҰд№ зҡ„жү§иЎҢеј•ж“ҺиҝӣиЎҢз»ҹдёҖ гҖӮ 3.д»ҘSQLзҡ„ж–№ејҸжқҘиЎЁиҫҫеӣҫеҢ–зҡ„жҹҘиҜўжөҒзЁӢ пјҢ иҝҷж ·дёҚе…үз”ЁжҲ·дҪҝз”Ёиө·жқҘз®ҖеҚ• пјҢ д№ҹеҸҜд»ҘеӨҚз”ЁSQLз”ҹжҖҒзҡ„дёҖдәӣеҹәзЎҖеҠҹиғҪ гҖӮ дёҫдёӘдҫӢеӯҗ пјҢ з”өе•ҶдёӘжҖ§еҢ–жҗңзҙўжҠҖжңҜйҮҢйқў пјҢ жҠҠе•Ҷе“ҒгҖҒдёӘжҖ§еҢ–жҺЁиҚҗгҖҒж·ұеәҰжЁЎеһӢзӯүдҝЎжҒҜеҲҶеҲ«ж”ҫеҲ°дёҚеҗҢзҡ„иЎЁдёӯ пјҢ й…ҚеҗҲдёҠзҒөжҙ»зҡ„зҙўеј•ж јејҸ пјҢ жҜ”еҰӮеҖ’жҺ’зҙўеј•гҖҒжӯЈжҺ’зҙўеј•гҖҒKVзҙўеј•зӯүзӯү пјҢ еҠ дёҠжү§иЎҢеј•ж“Һжң¬иә«еҸҜд»Ҙж”ҜжҢҒ并иЎҢгҖҒејӮжӯҘгҖҒзј–иҜ‘дјҳеҢ–зӯүжҠҖжңҜ пјҢ дёҚз®ЎжҳҜеҶ…еӯҳиҝҳжҳҜCPUйғҪиғҪеҫ—еҲ°жңүж•ҲеҲ©з”Ё пјҢ еҫҲиҪ»жқҫең°е°ұиғҪи§ЈеҶідёҡеҠЎдёҠзҡ„еҗ„з§Қй—®йўҳ гҖӮ
жҺЁиҚҗйҳ…иҜ»












![[жңЁдёҖи®әеҸІ]еҸӘеӣ еҘіжҠӨеЈ«дёә10дёҮзҫҺйҮ‘пјҢеҒ·еҒ·жҺҗж–ӯж°§ж°”з®ЎпјҢдјҠжң—еҜјеј№дё“家зӘ’жҒҜиә«дәЎ](https://imgcdn.toutiaoyule.com/20200425/20200425183300092024a_t.jpeg)


- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- NVIDIA 5nmжһ¶жһ„зҢӣж–ҷпјҡжөҒеӨ„зҗҶеҷЁи¶…1.84дёҮдёӘ
- MIPSжһ¶жһ„еҺӮе•Ҷж—ҘжёҗејҸеҫ® LinuxжҠҘе‘Ҡе…¶жјҸжҙһйҒӯйҒҮеӣ°йҡҫ
- NVIDIA 5nmжһ¶жһ„зҢӣж–ҷжӣқе…үпјҡ1.84дёҮдёӘж ёеҝғ
- е–өеҚҡеЈ«иө„и®Ҝ | дёӯеӣҪжүӢжңәеңЁеҚ°еәҰй”ҖйҮҸдёҚйҷҚеҸҚеҚҮпјӣиӢұдјҹиҫҫжӯЈи§„еҲ’5nmжһ¶жһ„жҳҫеҚЎ
- MIUI 12.5еҚҮзә§е…үй”ҘеҠЁж•Ҳжһ¶жһ„пјҡи°ҒдёҺдәүй”Ӣ
- AMD Zen3жһ¶жһ„й”җйҫҷ5000Hи·‘еҲҶжӣқе…үпјҡеҚ•ж ёжҖ§иғҪжҡҙж¶Ёиҝ‘40пј…
- иӢ№жһңжӯЈеңЁз ”еҸ‘зҡ„жҗңзҙўеј•ж“ҺиғҪе№Ізҡ„иҝҮи°·жӯҢеҗ—пјҹ
- AMDзЎ®и®ӨZen3жһ¶жһ„ж–°дёҖд»Јй”җйҫҷзәҝзЁӢж’•иЈӮиҖ…еӨ„зҗҶеҷЁпјҡиҰҒжҳҺе№ҙи§ҒдәҶ
- зҫҺеӣў|зҺӢж…§ж–ҮйҖҖдј‘ зҫҺеӣўи°ғж•ҙз»„з»Үжһ¶жһ„