网易数据湖探索与实践( 二 )
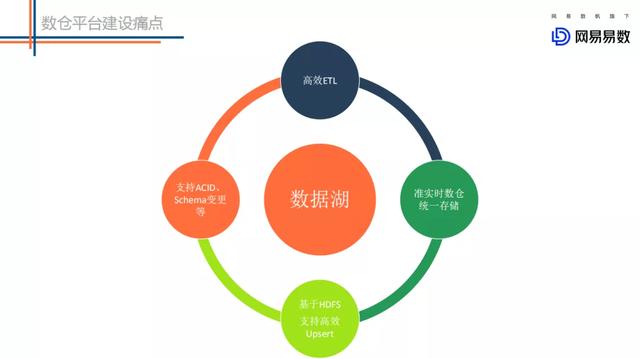
不能友好地支持高效更新场景 。 大数据的更新场景一般有两种 , 一种是CDC ( Change Data Capture ) 的更新 , 尤其在电商的场景下 , 将binlog中的更新删除同步到HDFS上 。 另一种是延迟数据带来的聚合后结果的更新 。 目前HDFS只支持追加写 , 不支持更新 。 因此业界很多公司引入了Kudu 。 但是Kudu本身是有一些局限的 , 比如计算存储没有做到分离 。 这样整个数仓系统中引入了HDFS、Kafka以及Kudu , 运维成本不可谓不大 。
 文章插图
文章插图
上面就是针对目前数仓所涉及到的四个痛点的大致介绍 , 因此我们也是通过对数据湖的调研和实践 , 希望能在这四个方面对数仓建设有所帮助 。 接下来重点讲解下对数据湖的一些思考 。
02
数据湖Iceberg核心原理
1. 数据湖开源产品调研
 文章插图
文章插图
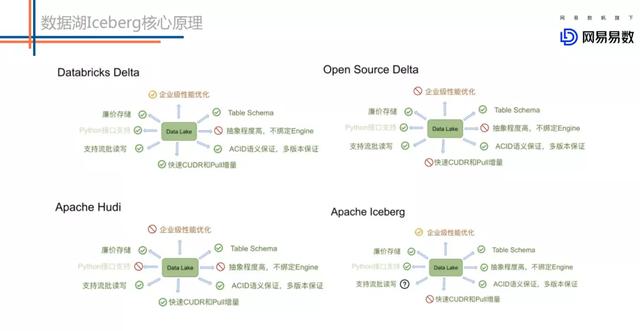
数据湖大致是从19年开始慢慢火起来的 , 目前市面上核心的数据湖开源产品大致有这么几个:
- DELTA LAKE , 在17年的时候DataBricks就做了DELTA LAKE的商业版 。 主要想解决的也是基于Lambda架构带来的存储问题 , 它的初衷是希望通过一种存储来把Lambda架构做成kappa架构 。
- Hudi ( Uber开源 ) 可以支持快速的更新以及增量的拉取操作 。 这是它最大的卖点之一 。
- Iceberg的初衷是想做标准的Table Format以及高效的ETL 。
 文章插图
文章插图上图是来自阿里Flink团体针对数据湖方案的一些调研对比 , 总体来看这些方案的基础功能相对都还是比较完善的 。 我说的基础功能主要包括:
- 高效Table Schema的变更 , 比如针对增减分区 , 增减字段等功能
- ACID语义保证
- 同时支持流批读写 , 不会出现脏读等现象
- 支持OSS这类廉价存储
- Hudi的特性主要是支持快速的更新删除和增量拉取 。
- Iceberg的特性主要是代码抽象程度高 , 不绑定任何的Engine 。 它暴露出来了非常核心的表层面的接口 , 可以非常方便的与Spark/Flink对接 。 然而Delta和Hudi基本上和spark的耦合很重 。 如果想接入flink , 相对比较难 。
- 现在国内的实时数仓建设围绕flink的情况会多一点 。 所以能够基于flink扩展生态 , 是我们选择iceberg一个比较重要的点 。
- 国内也有很多基于Iceberg开发的重要力量 , 比如腾讯团队、阿里Flink官方团队 , 他们的数据湖选型也是Iceberg 。 目前他们在社区分别主导update以及flink的生态对接 。
 文章插图
文章插图这是来自官方对于Iceberg的一段介绍 , 大致就是Iceberg是一个开源的基于表格式的数据湖 。 关于table format再给大家详细介绍下:
 文章插图
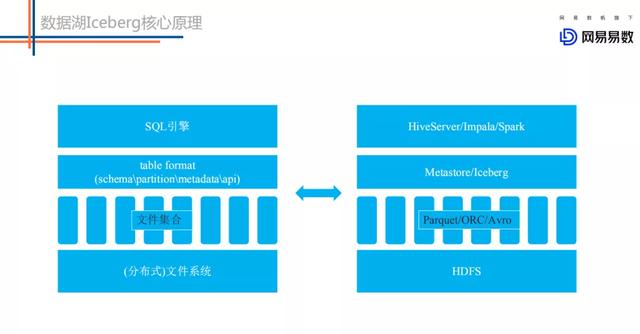
文章插图左侧图是一个抽象的数据处理系统 , 分别由SQL引擎、table format、文件集合以及分布式文件系统构成 。 右侧是对应的现实中的组件 , SQL引擎比如HiveServer、Impala、Spark等等 , table format比如Metastore或者Iceberg , 文件集合主要有Parquet文件等 , 而分布式文件系统就是HDFS 。
对于table format , 我认为主要包含4个层面的含义 , 分别是表schema定义(是否支持复杂数据类型) , 表中文件的组织形式 , 表相关统计信息、表索引信息以及表的读写API实现 。 详述如下:
推荐阅读







![[快科技]小米10青春版邀请函图赏:哆啦A梦迷你抓娃娃机](http://ttbs.guangsuss.com/image/3edcbb553cbab8a02c1d1c782772809f)







- 网易云音乐上线“一键迁移”虾米歌单功能:还免费送3个月黑胶VIP
- 虾米音乐别了!教你把虾米导入QQ音乐网易云音乐
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 虾米音乐活跃用户一千万不到,QQ音乐、网易云音乐花式抢客
- 虾米音乐歌单可导入QQ音乐、网易云音乐 方法这
- 市科委与联影集团联合首设“探索者计划”,共推基础及应用基础研究
- 美的探索工业互联网+5G+AI应用场景,成本可降低10%
- 网易数帆亮相中台战略大会,解读云原生软件生产力实践
- 聊聊网易云音乐:“心动模式”
- 小姐姐带你探索萌粉电竞显示器的秘密