NLP:иҜҚдёӯзҡ„ж•°еӯҰ( дёғ )
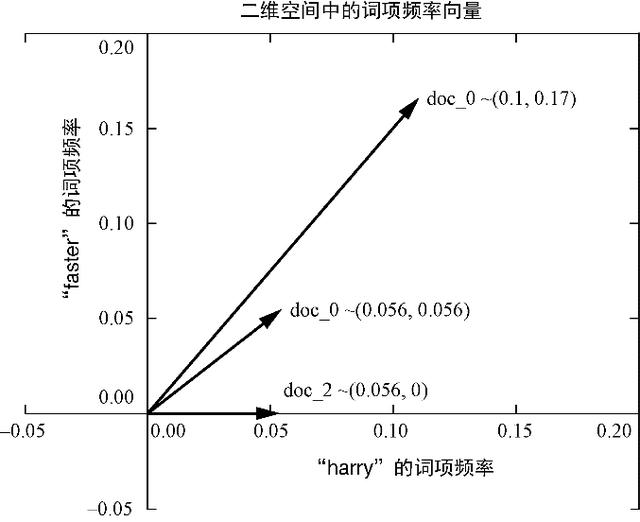
еҜ№дәҺиҮӘ然иҜӯиЁҖж–ҮжЎЈеҗ‘йҮҸз©әй—ҙ пјҢ еҗ‘йҮҸз©әй—ҙзҡ„з»ҙж•°жҳҜж•ҙдёӘиҜӯж–ҷеә“дёӯеҮәзҺ°зҡ„дёҚеҗҢиҜҚзҡ„ж•°йҮҸ гҖӮ еҜ№дәҺTFпјҲе’ҢеҗҺйқўзҡ„TF-IDFпјү пјҢ жңүж—¶жҲ‘们дјҡз”ЁдёҖдёӘеӨ§еҶҷеӯ—жҜҚK пјҢ з§°е®ғдёәKз»ҙз©әй—ҙ гҖӮ дёҠиҝ°еңЁиҜӯж–ҷеә“дёӯдёҚеҗҢзҡ„иҜҚзҡ„ж•°йҮҸд№ҹжӯЈеҘҪжҳҜиҜӯж–ҷеә“зҡ„иҜҚжұҮйҮҸзҡ„规模 пјҢ еӣ жӯӨеңЁеӯҰжңҜи®әж–Үдёӯ пјҢ е®ғйҖҡеёёиў«з§°дёә|V| гҖӮ 然еҗҺеҸҜд»Ҙз”ЁиҝҷдёӘKз»ҙз©әй—ҙдёӯзҡ„дёҖдёӘKз»ҙеҗ‘йҮҸжқҘжҸҸиҝ°жҜҸзҜҮж–ҮжЎЈ гҖӮ еңЁеүҚйқў3зҜҮе…ідәҺHarryе’ҢJillзҡ„ж–ҮжЎЈиҜӯж–ҷеә“дёӯ пјҢ K = 18 гҖӮ еӣ дёәдәәзұ»ж— жі•иҪ»жҳ“ең°еҜ№дёүз»ҙд»ҘдёҠзҡ„з©әй—ҙиҝӣиЎҢеҸҜи§ҶеҢ– пјҢ жүҖд»ҘжҲ‘们жҺҘдёӢжқҘжҠҠеӨ§йғЁеҲҶзҡ„й«ҳз»ҙз©әй—ҙж”ҫеңЁдёҖиҫ№ пјҢ е…ҲзңӢдёҖдёӢдәҢз»ҙз©әй—ҙ пјҢ иҝҷж ·жҲ‘们е°ұиғҪеңЁеҪ“еүҚжӯЈеңЁйҳ…иҜ»зҡ„е№ійқўдёҠзңӢеҲ°еҗ‘йҮҸзҡ„еҸҜи§ҶеҢ–иЎЁзӨә гҖӮ еӣ жӯӨ пјҢ еңЁеӣҫ3-2дёӯ пјҢ жҲ‘们з»ҷеҮәдәҶ18з»ҙHarryе’ҢJillж–ҮжЎЈеҗ‘йҮҸз©әй—ҙзҡ„дәҢз»ҙи§Ҷеӣҫ пјҢ жӯӨж—¶Kиў«з®ҖеҢ–дёә2 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ3-2гҖҖдәҢз»ҙиҜҚйЎ№йў‘зҺҮеҗ‘йҮҸ
Kз»ҙеҗ‘йҮҸе’ҢдёҖиҲ¬еҗ‘йҮҸзҡ„е·ҘдҪңж–№ејҸжҳҜе®Ңе…ЁдёҖж ·зҡ„ пјҢ еҸӘжҳҜдёҚеӨӘе®№жҳ“ең°еҜ№е…¶иҝӣиЎҢеҸҜи§ҶеҢ–иҖҢе·І гҖӮ 既然зҺ°еңЁе·Із»ҸжңүдәҶжҜҸдёӘж–ҮжЎЈзҡ„иЎЁзӨәеҪўејҸ пјҢ 并且зҹҘйҒ“е®ғ们е…ұдә«е…¬е…ұз©әй—ҙ пјҢ йӮЈд№ҲжҺҘдёӢжқҘеҸҜд»ҘеҜ№е®ғ们иҝӣиЎҢжҜ”иҫғ гҖӮ жҲ‘们еҸҜд»ҘйҖҡиҝҮеҗ‘йҮҸзӣёеҮҸ пјҢ 然еҗҺи®Ўз®—з»“жһңеҗ‘йҮҸзҡ„еӨ§е°ҸжқҘеҫ—еҲ°дёӨдёӘеҗ‘йҮҸд№Ӣй—ҙзҡ„欧еҮ йҮҢеҫ—и·қзҰ» пјҢ д№ҹз§°дёә2иҢғж•°и·қзҰ» гҖӮ иҝҷжҳҜвҖңд№ҢйёҰвҖқд»ҺдёҖдёӘеҗ‘йҮҸзҡ„йЎ¶зӮ№дҪҚзҪ®пјҲеӨҙпјүеҲ°еҸҰдёҖдёӘеҗ‘йҮҸзҡ„йЎ¶зӮ№дҪҚзҪ®йЈһиЎҢзҡ„пјҲзӣҙзәҝпјүи·қзҰ» гҖӮ иҜ»иҖ…еҸҜд»ҘжҹҘзңӢдёҖдёӢе…ідәҺзәҝжҖ§д»Јж•°зҡ„йҷ„еҪ•C пјҢ дәҶи§Јдёәд»Җд№Ҳ欧еҮ йҮҢеҫ—и·қзҰ»еҜ№иҜҚйў‘пјҲиҜҚйЎ№йў‘зҺҮпјүеҗ‘йҮҸжқҘиҜҙдёҚжҳҜдёҖдёӘеҘҪж–№жі• гҖӮ
еҰӮжһңдёӨдёӘеҗ‘йҮҸзҡ„ж–№еҗ‘зӣёдјј пјҢ е®ғ们е°ұвҖңзӣёдјјвҖқ гҖӮ е®ғ们еҸҜиғҪе…·жңүзӣёдјјзҡ„еӨ§е°ҸпјҲй•ҝеәҰпјү пјҢ иҝҷж„Ҹе‘ізқҖиҝҷдёӨдёӘиҜҚйў‘пјҲиҜҚйЎ№йў‘зҺҮпјүеҗ‘йҮҸжүҖеҜ№еә”зҡ„ж–ҮжЎЈй•ҝеәҰеҹәжң¬зӣёзӯү гҖӮ дҪҶжҳҜ пјҢ еҪ“еҜ№ж–ҮжЎЈдёӯиҜҚзҡ„еҗ‘йҮҸиЎЁзӨәиҝӣиЎҢзӣёдјјеәҰдј°з®—ж—¶ пјҢ жҲ‘们жҳҜеҗҰдјҡе…іеҝғж–ҮжЎЈй•ҝеәҰпјҹжҒҗжҖ•дёҚдјҡ гҖӮ жҲ‘们еңЁеҜ№ж–ҮжЎЈзӣёдјјеәҰиҝӣиЎҢдј°з®—ж—¶еёҢжңӣиғҪеӨҹжүҫеҲ°зӣёеҗҢиҜҚзҡ„зӣёдјјдҪҝз”ЁжҜ”дҫӢ гҖӮ еҮҶзЎ®дј°з®—зӣёдјјеәҰдјҡи®©жҲ‘们确дҝЎ пјҢ дёӨзҜҮж–ҮжЎЈеҸҜиғҪж¶үеҸҠзӣёдјјзҡ„дё»йўҳ гҖӮ
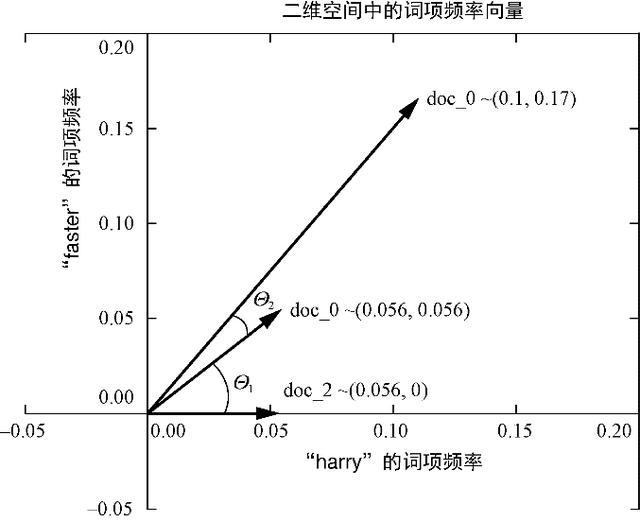
дҪҷејҰзӣёдјјеәҰд»…д»…жҳҜдёӨдёӘеҗ‘йҮҸеӨ№и§’зҡ„дҪҷејҰеҖј пјҢ еҰӮеӣҫ3-3жүҖзӨә пјҢ еҸҜд»Ҙ用欧еҮ йҮҢеҫ—зӮ№з§ҜжқҘи®Ўз®—пјҡ
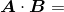 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дҪҷејҰзӣёдјјеәҰзҡ„и®Ўз®—еҫҲй«ҳж•Ҳ пјҢ еӣ дёәзӮ№з§ҜдёҚйңҖиҰҒд»»дҪ•еҜ№дёүи§’еҮҪж•°жұӮеҖј гҖӮ жӯӨеӨ– пјҢ дҪҷејҰзӣёдјјеәҰзҡ„еҸ–еҖјиҢғеӣҙеҚҒеҲҶдҫҝдәҺеӨ„зҗҶеӨ§еӨҡж•°жңәеҷЁеӯҰд№ й—®йўҳпјҡ?1еҲ°+1 гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ3-3гҖҖдәҢз»ҙеҗ‘йҮҸзҡ„еӨ№и§’
еңЁPythonдёӯ пјҢ еҸҜд»ҘдҪҝз”Ё
a.dot(b) == np.linalg.norm(a) * np.linalg.norm(b) / np.cos(theta)жұӮи§Јcos(theta)зҡ„е…ізі» пјҢ еҫ—еҲ°еҰӮдёӢдҪҷејҰзӣёдјјеәҰзҡ„и®Ўз®—е…¬ејҸпјҡ
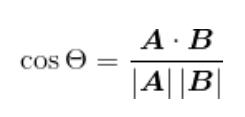 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҲ–иҖ…еҸҜд»ҘйҮҮз”ЁзәҜPythonпјҲжІЎжңүnumpyпјүдёӯзҡ„и®Ўз®—ж–№жі• пјҢ еҰӮд»Јз Ғжё…еҚ•3-1жүҖзӨә гҖӮ
д»Јз Ғжё…еҚ•3-1гҖҖPythonдёӯзҡ„дҪҷејҰзӣёдјјеәҰи®Ўз®—
>>> import math>>> def cosine_sim(vec1, vec2):...""" Let's convert our dictionaries to lists for easier matching."""...vec1 = [val for val in vec1.values()]...vec2 = [val for val in vec2.values()]......dot_prod = 0...for i, v in enumerate(vec1):...dot_prod += v * vec2[i]......mag_1 = math.sqrt(sum([x**2 for x in vec1]))...mag_2 = math.sqrt(sum([x**2 for x in vec2]))......return dot_prod / (mag_1 * mag_2)жүҖд»Ҙ пјҢ жҲ‘们йңҖиҰҒе°ҶдёӨдёӘеҗ‘йҮҸдёӯзҡ„е…ғзҙ жҲҗеҜ№зӣёд№ҳ пјҢ 然еҗҺеҶҚжҠҠиҝҷдәӣд№ҳз§ҜеҠ иө·жқҘ пјҢ иҝҷж ·е°ұеҸҜд»Ҙеҫ—еҲ°дёӨдёӘеҗ‘йҮҸзҡ„зӮ№з§Ҝ гҖӮ еҶҚе°Ҷеҫ—еҲ°зҡ„зӮ№з§ҜйҷӨд»ҘжҜҸдёӘеҗ‘йҮҸзҡ„жЁЎпјҲеӨ§е°ҸжҲ–й•ҝеәҰпјү пјҢ еҗ‘йҮҸзҡ„жЁЎзӯүдәҺеҗ‘йҮҸзҡ„еӨҙйғЁеҲ°е°ҫйғЁзҡ„欧еҮ йҮҢеҫ—и·қзҰ» пјҢ д№ҹе°ұжҳҜе®ғзҡ„еҗ„е…ғзҙ е№іж–№е’Ңзҡ„е№іж–№ж № гҖӮ дёҠиҝ°еҪ’дёҖеҢ–зҡ„зӮ№з§ҜпјҲnormalized dot productпјүзҡ„иҫ“еҮәе°ұеғҸдҪҷејҰеҮҪж•°дёҖж ·еҸ–?1еҲ°1д№Ӣй—ҙзҡ„еҖј пјҢ е®ғд№ҹжҳҜиҝҷдёӨдёӘеҗ‘йҮҸеӨ№и§’зҡ„дҪҷејҰеҖј гҖӮ иҝҷдёӘеҖјзӯүдәҺзҹӯеҗ‘йҮҸеңЁй•ҝеҗ‘йҮҸдёҠзҡ„жҠ•еҪұй•ҝеәҰеҚ й•ҝеҗ‘йҮҸй•ҝеәҰзҡ„жҜ”дҫӢ пјҢ е®ғз»ҷеҮәзҡ„жҳҜдёӨдёӘеҗ‘йҮҸжҢҮеҗ‘еҗҢдёҖж–№еҗ‘зҡ„зЁӢеәҰ гҖӮ
жҺЁиҚҗйҳ…иҜ»















![[иЎўе·һйӣҶиҒҡеҢә]гҖҗдёҖзәҝжҲҳвҖңз–«вҖқгҖ‘дёҖдҪҚ80еҗҺдёҡ委дјҡдё»д»»зҡ„йҳІз–«ж•…дәӢ](https://imgcdn.toutiaoyule.com/20200404/20200404084152089853a_t.jpeg)



- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- з”°дјҹйҷўеЈ«пјҡжҲ‘зңјдёӯзҡ„еҢ»з–—жңәеҷЁдәә
- Mozillaе°Ҷй»ҳи®ӨзҰҒз”ЁFirefoxдёӯзҡ„йҖҖж јй”®д»ҘйҳІжӯўз”ЁжҲ·зј–иҫ‘ж•°жҚ®дёўеӨұ
- LG Stylo 7жёІжҹ“еӣҫжӣқе…үпјҡжІЎжңүйў„жғідёӯзҡ„йҮҚеӨ§еҚҮзә§
- е№іж·Ўж— еҘҮдёӯзҡ„жҡ—иҮӘеҚҮзә§пјҢ2020е№ҙдё»жқҝеёӮеңәе№ҙз»ҲзӣҳзӮ№
- жүӢжңәдёӯзҡ„вҖңе“ҲжӣјеҚЎйЎҝвҖқпјҢе°Ҹзұі11еҸҲжңү黑科жҠҖжӣқе…ү
- и°·жӯҢProject ZeroжҠ«йңІдәҶWindowsдёӯзҡ„дёҘйҮҚе®үе…ЁжјҸжҙһ
- еҫ®дҝЎжҺЁеҮәвҖңеҫ®дҝЎиұҶвҖқпјҢеҸҜз”ЁдәҺиҙӯд№°зӣҙж’ӯдёӯзҡ„иҷҡжӢҹзӨјзү©пјҢдҪ дјҡе……еҖјеҗ—пјҹ
- жӣҫжҳҜзӣ—зүҲдёӯзҡ„жҲҗеҠҹжЎҲдҫӢпјҢиҝҳе°ҶжӯЈе“Ғе…¬еҸёж”¶иҙӯпјҢеҺҹеӣ жҳҜвҖңиҝ·еӨұдәҶвҖқж–№еҗ‘
- и°·жӯҢжҠ«йңІеӯҳеңЁдәҺй«ҳйҖҡйӘҒйҫҷAdreno GPUдёӯзҡ„й«ҳеҚұжјҸжҙһ