гҖҢзі»з»ҹжһ¶жһ„гҖҚд»Җд№ҲжҳҜй“ҫи·ҜиҝҪиёӘпјҹеҲҶеёғејҸзі»з»ҹеҰӮдҪ•е®һзҺ°й“ҫи·ҜиҝҪиёӘпјҹ( дёү )
3гҖҒtraceId еҰӮдҪ•дҝқиҜҒе…ЁеұҖе”ҜдёҖ
иҰҒдҝқиҜҒе…ЁеұҖе”ҜдёҖпјҢ жҲ‘们еҸҜд»ҘйҮҮз”ЁеҲҶеёғејҸжҲ–иҖ…жң¬ең°з”ҹжҲҗзҡ„ ID гҖӮ дҪҝз”ЁеҲҶеёғејҸзҡ„иҜқ пјҢ йңҖиҰҒжңүдёҖдёӘеҸ‘еҸ·еҷЁ пјҢ жҜҸж¬ЎиҜ·жұӮйғҪиҰҒе…ҲиҜ·жұӮдёҖдёӢеҸ‘еҸ·еҷЁ пјҢ дјҡжңүдёҖж¬ЎзҪ‘з»ңи°ғз”Ёзҡ„ејҖй”Җ гҖӮ жүҖд»Ҙ SkyWalking жңҖз»ҲйҮҮз”ЁдәҶжң¬ең°з”ҹжҲҗ ID зҡ„ж–№ејҸ пјҢ е®ғйҮҮз”ЁдәҶеӨ§еҗҚйјҺйјҺзҡ„ snowflow з®—жі• пјҢ жҖ§иғҪеҫҲй«ҳ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
snowflake з®—жі•з”ҹжҲҗзҡ„ id
дёҚиҝҮ snowflake з®—жі•жңүдёҖдёӘдј—жүҖе‘ЁзҹҘзҡ„й—®йўҳпјҡж—¶й—ҙеӣһжӢЁ пјҢ иҝҷдёӘй—®йўҳеҸҜиғҪдјҡеҜјиҮҙз”ҹжҲҗзҡ„ id йҮҚеӨҚ гҖӮ йӮЈд№Ҳ SkyWalking жҳҜеҰӮдҪ•и§ЈеҶіж—¶й—ҙеӣһжӢЁй—®йўҳзҡ„е‘ў гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
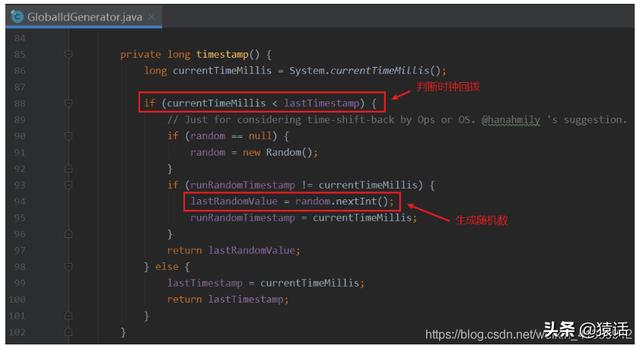
жҜҸз”ҹжҲҗдёҖдёӘ id пјҢ йғҪдјҡи®°еҪ•дёҖдёӢз”ҹжҲҗ id зҡ„ж—¶й—ҙпјҲlastTimestampпјү пјҢ еҰӮжһңеҸ‘зҺ°еҪ“еүҚж—¶й—ҙжҜ”дёҠдёҖж¬Ўз”ҹжҲҗ id зҡ„ж—¶й—ҙпјҲlastTimestampпјүиҝҳе°Ҹ пјҢ йӮЈиҜҙжҳҺеҸ‘з”ҹдәҶж—¶й—ҙеӣһжӢЁ пјҢ жӯӨж—¶дјҡз”ҹжҲҗдёҖдёӘйҡҸжңәж•°жқҘдҪңдёә traceId гҖӮ иҝҷйҮҢеҸҜиғҪе°ұжңүеҗҢеӯҰиҰҒиҫғзңҹдәҶ пјҢ еҸҜиғҪдјҡи§үеҫ—з”ҹжҲҗзҡ„иҝҷдёӘйҡҸжңәж•°д№ҹдјҡе’Ңе·Із”ҹжҲҗзҡ„е…ЁеұҖ id йҮҚеӨҚ пјҢ жҳҜеҗҰеҶҚеҠ дёҖеұӮж ЎйӘҢдјҡеҘҪзӮ№ гҖӮ
иҝҷйҮҢиҰҒиҜҙдёҖдёӢзі»з»ҹи®ҫи®ЎдёҠзҡ„ж–№жЎҲеҸ–иҲҚй—®йўҳдәҶ пјҢ йҰ–е…ҲеҰӮжһңй’ҲеҜ№дә§з”ҹзҡ„иҝҷдёӘйҡҸжңәж•°дҪңе”ҜдёҖжҖ§ж ЎйӘҢж— з–‘дјҡеӨҡдёҖеұӮи°ғз”Ё пјҢ дјҡжңүдёҖе®ҡзҡ„жҖ§иғҪжҚҹиҖ— пјҢ дҪҶе…¶е®һж—¶й—ҙеӣһжӢЁеҸ‘з”ҹзҡ„жҰӮзҺҮеҫҲе°ҸпјҲеҸ‘з”ҹд№ӢеҗҺз”ұдәҺжңәеҷЁж—¶й—ҙзҙҠд№ұ пјҢ дёҡеҠЎдјҡеҸ—еҲ°еҫҲеӨ§еҪұе“Қ пјҢ жүҖд»ҘжңәеҷЁж—¶й—ҙзҡ„и°ғж•ҙеҝ…然иҰҒж…Һд№ӢеҸҲж…Һпјү пјҢ еҶҚеҠ дёҠз”ҹжҲҗзҡ„йҡҸжңәж•°йҮҚеҗҲзҡ„жҰӮзҺҮд№ҹеҫҲе°Ҹ пјҢ з»јеҗҲиҖғиҷ‘иҝҷйҮҢзЎ®е®һжІЎжңүеҝ…иҰҒеҶҚеҠ дёҖеұӮе…ЁеұҖе”ҜдёҖжҖ§ж ЎйӘҢ гҖӮ еҜ№дәҺжҠҖжңҜж–№жЎҲзҡ„йҖүеһӢ пјҢ дёҖе®ҡиҰҒйҒҝе…ҚиҝҮеәҰи®ҫи®Ў пјҢ иҝҮзҠ№дёҚеҸҠ гҖӮ
4гҖҒиҜ·жұӮйҮҸиҝҷд№ҲеӨҡ пјҢ е…ЁйғЁйҮҮйӣҶдјҡдёҚдјҡеҪұе“ҚжҖ§иғҪ?
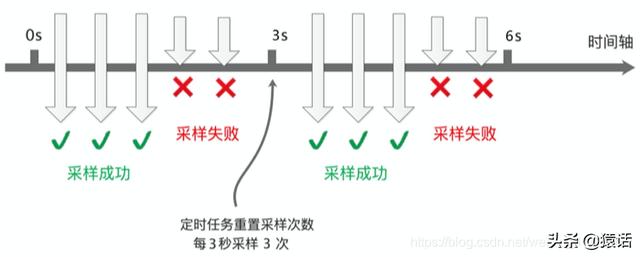
еҰӮжһңеҜ№жҜҸдёӘиҜ·жұӮи°ғз”ЁйғҪйҮҮйӣҶ пјҢ йӮЈжҜ«ж— з–‘й—®ж•°жҚ®йҮҸдјҡйқһеёёеӨ§ пјҢ дҪҶеҸҚиҝҮжқҘжғідёҖдёӢ пјҢ жҳҜеҗҰзңҹзҡ„жңүеҝ…иҰҒеҜ№жҜҸдёӘиҜ·жұӮйғҪйҮҮйӣҶе‘ўпјҹе…¶е®һжІЎжңүеҝ…иҰҒ пјҢ жҲ‘们еҸҜд»Ҙи®ҫзҪ®йҮҮж ·йў‘зҺҮ пјҢ еҸӘйҮҮж ·йғЁеҲҶж•°жҚ® пјҢ SkyWalking й»ҳи®Өи®ҫзҪ®дәҶ 3 з§’йҮҮж · 3 ж¬Ў пјҢ е…¶дҪҷиҜ·жұӮдёҚйҮҮж · пјҢ еҰӮеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
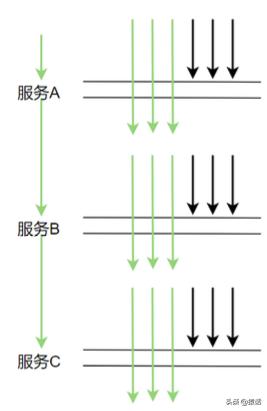
иҝҷж ·зҡ„йҮҮж ·йў‘зҺҮе…¶е®һи¶іеӨҹжҲ‘们еҲҶжһҗ组件зҡ„жҖ§иғҪдәҶ пјҢ жҢү 3 з§’йҮҮж · 3 ж¬Ў пјҢ иҝҷж ·зҡ„йў‘зҺҮжқҘйҮҮж ·ж•°жҚ®дјҡжңүе•Ҙй—®йўҳе‘ў гҖӮ зҗҶжғіжғ…еҶөдёӢ пјҢ жҜҸдёӘжңҚеҠЎи°ғз”ЁйғҪеңЁеҗҢдёҖдёӘж—¶й—ҙзӮ№ пјҢ иҝҷж ·зҡ„иҜқжҜҸж¬ЎйғҪеңЁеҗҢдёҖж—¶й—ҙзӮ№йҮҮж ·зЎ®е®һжІЎй—®йўҳ гҖӮ еҰӮдёӢеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
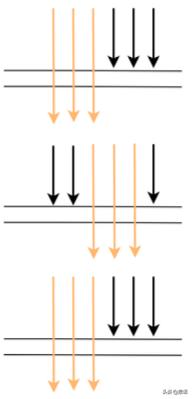
дҪҶеңЁз”ҹдә§дёҠ пјҢ жҜҸж¬ЎжңҚеҠЎи°ғз”Ёеҹәжң¬дёҚеҸҜиғҪйғҪеңЁеҗҢдёҖж—¶й—ҙзӮ№и°ғз”Ё пјҢ еӣ дёәжңҹй—ҙжңүзҪ‘з»ңи°ғ用延时зӯү пјҢ е®һйҷ…и°ғз”Ёжғ…еҶөеҫҲеҸҜиғҪжҳҜдёӢеӣҫиҝҷж ·пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷж ·зҡ„иҜқе°ұдјҡеҜјиҮҙжҹҗдәӣи°ғз”ЁеңЁжңҚеҠЎ A дёҠиў«йҮҮж ·дәҶ пјҢ еңЁжңҚеҠЎ B пјҢ C дёҠдёҚиў«йҮҮж · пјҢ д№ҹе°ұжІЎжі•еҲҶжһҗи°ғз”Ёй“ҫзҡ„жҖ§иғҪ гҖӮ
йӮЈд№Ҳ SkyWalking жҳҜеҰӮдҪ•и§ЈеҶізҡ„е‘ўпјҹ
е®ғжҳҜиҝҷж ·и§ЈеҶізҡ„пјҡеҰӮжһңдёҠжёёжңүжҗәеёҰ Context иҝҮжқҘпјҲиҜҙжҳҺдёҠжёёйҮҮж ·дәҶпјү пјҢ еҲҷдёӢжёёе°ҶејәеҲ¶йҮҮйӣҶж•°жҚ® пјҢ иҝҷж ·еҸҜд»ҘдҝқиҜҒй“ҫи·Ҝе®Ңж•ҙ гҖӮ
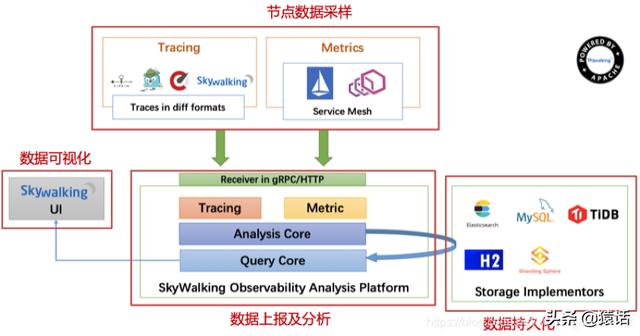
SkyWalking зҡ„еҹәзЎҖжһ¶жһ„SkyWalking зҡ„еҹәзЎҖеҰӮдёӢжһ¶жһ„ пјҢ еҸҜд»ҘиҜҙеҮ д№ҺжүҖжңүзҡ„зҡ„еҲҶеёғејҸи°ғз”ЁйғҪжҳҜз”ұд»ҘдёӢеҮ дёӘ组件组жҲҗзҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҰ–е…ҲеҪ“然жҳҜиҠӮзӮ№ж•°жҚ®зҡ„е®ҡж—¶йҮҮж · пјҢ йҮҮж ·еҗҺе°Ҷж•°жҚ®е®ҡж—¶дёҠжҠҘ пјҢ е°Ҷе…¶еӯҳеӮЁеҲ° ES, MySQL зӯүжҢҒд№…еҢ–еұӮ пјҢ жңүдәҶж•°жҚ®иҮӘ然иҖҢ然еҸҜж №жҚ®ж•°жҚ®еҒҡеҸҜи§ҶеҢ–еҲҶжһҗ гҖӮ
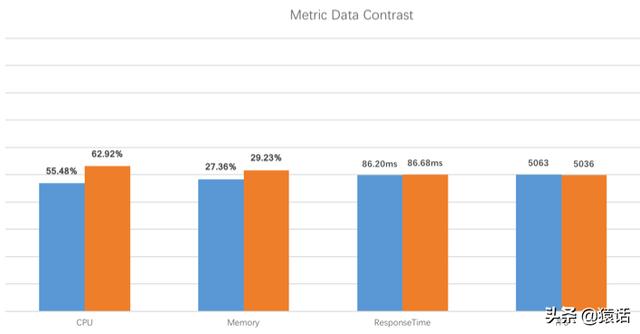
SkyWalking зҡ„жҖ§иғҪеҰӮдҪ•еҰӮдёӢжҳҜе®ҳж–№зҡ„жөӢиҜ„ж•°жҚ®пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫдёӯи“қиүІд»ЈиЎЁжңӘдҪҝз”Ё SkyWalking зҡ„иЎЁзҺ° пјҢ ж©ҷиүІд»ЈиЎЁдҪҝз”ЁдәҶ SkyWalking зҡ„иЎЁзҺ° пјҢ д»ҘдёҠжҳҜеңЁ TPS дёә 5000 зҡ„жғ…еҶөдёӢжөӢеҮәзҡ„ж•°жҚ® пјҢ еҸҜд»ҘзңӢеҮә пјҢ дёҚи®әжҳҜ CPU пјҢ еҶ…еӯҳ пјҢ иҝҳжҳҜе“Қеә”ж—¶й—ҙ пјҢ дҪҝз”Ё SkyWalking еёҰжқҘзҡ„жҖ§иғҪжҚҹиҖ—еҮ д№ҺеҸҜд»ҘеҝҪз•ҘдёҚи®Ў гҖӮ
жҺЁиҚҗйҳ…иҜ»













![[и…ҫи®Ҝ科жҠҖ]дәҡ马йҖҠд»“еә“еҸӘиҝӣеҝ…йңҖе“ҒпјҢиҙ·ж¬ҫзј иә«зҡ„еҚ–家дёҡеҠЎеҸ—жҚҹгҖҒеІҢеІҢеҸҜеҚұ](http://ttbs.guangsuss.com/image/5f41d7bbff536ef727029b8fdf70c7a9)
- й»‘йІЁ4proд»Җд№Ҳж—¶еҖҷеҮәеӨҡе°‘й’ұпјҢй»‘йІЁ4proд»·ж јеҸӮж•°д»Ӣз»Қ
- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- жһҒйҖҹйІЁиҜҫе Ӯ89пјҡдё»жқҝеҗҚеӯ—еёҰWIFIе’ҢдёҚеёҰжңүд»Җд№ҲеҢәеҲ«
- зғҹеҸ°жёҜвҖңз®ЎйҒ“жҷәи„‘зі»з»ҹвҖқдёҠзәҝ еңЁеӣҪеҶ…зҺҮе…Ҳе®һзҺ°еҺҹжІ№еӮЁиҝҗе…ЁжҒҜжҷәиғҪжҺ’дә§
- жҜ”иө·007пјҢ996зңҹзҡ„жҳҜзҰҸжҠҘпјҒдә’иҒ”зҪ‘еӨ§еҺӮдёәд»Җд№ҲеҠ зҸӯйғҪиҝҷд№ҲзӢ пјҹ
- vivoдёҖж¬ҫж–°жңәзҺ°иә«и·‘еҲҶзҪ‘пјҒиҝҗеӯҳе’Ңзі»з»ҹдҝЎжҒҜйҖҡйҖҡжӣқе…ү
- vivoиҝҪжұӮзҡ„жң¬еҺҹи®ҫи®ЎжҳҜд»Җд№ҲпјҹX60 Proз»ҷеҮәдәҶзӯ”жЎҲ