гҖҢзі»з»ҹжһ¶жһ„гҖҚд»Җд№ҲжҳҜй“ҫи·ҜиҝҪиёӘпјҹеҲҶеёғејҸзі»з»ҹеҰӮдҪ•е®һзҺ°й“ҫи·ҜиҝҪиёӘпјҹ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
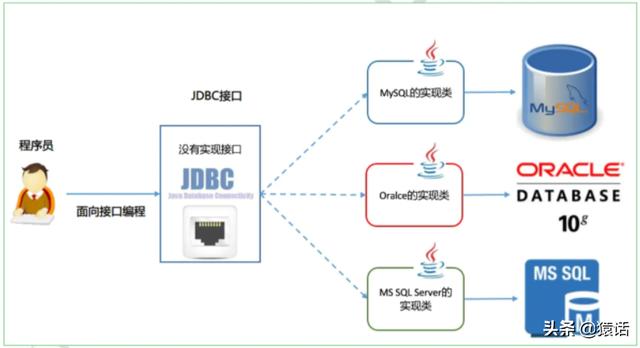
OpenTracing зҡ„ж•°жҚ®жЁЎеһӢ пјҢ дё»иҰҒжңүд»ҘдёӢдёүдёӘпјҡ
- TraceпјҡдёҖдёӘе®Ңж•ҙиҜ·жұӮй“ҫи·Ҝ
- SpanпјҡдёҖж¬Ўи°ғз”ЁиҝҮзЁӢпјҲйңҖиҰҒжңүејҖе§Ӣж—¶й—ҙе’Ңз»“жқҹж—¶й—ҙпјү
- SpanContextпјҡTrace зҡ„е…ЁеұҖдёҠдёӢж–ҮдҝЎжҒҜ пјҢ еҰӮйҮҢйқўжңүtraceId
 ж–Үз« жҸ’еӣҫ
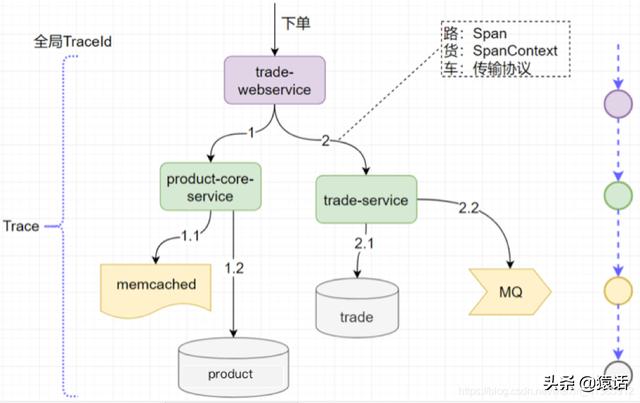
ж–Үз« жҸ’еӣҫеҰӮеӣҫжүҖзӨә пјҢ дёҖж¬ЎдёӢеҚ•зҡ„е®Ңж•ҙиҜ·жұӮе°ұжҳҜдёҖдёӘ Trace гҖӮ TraceIdжҳҜиҝҷдёӘиҜ·жұӮзҡ„е…ЁеұҖж ҮиҜҶ гҖӮ еҶ…йғЁзҡ„жҜҸдёҖж¬Ўи°ғз”Ёе°ұз§°дёәдёҖдёӘ Span пјҢ жҜҸдёӘ Span йғҪиҰҒеёҰдёҠе…ЁеұҖзҡ„ TraceId пјҢ иҝҷж ·жүҚеҸҜжҠҠе…ЁеұҖ TraceId дёҺжҜҸдёӘи°ғз”Ёе…іиҒ”иө·жқҘ гҖӮ иҝҷдёӘ TraceId жҳҜйҖҡиҝҮ SpanContext дј иҫ“зҡ„ пјҢ 既然иҰҒдј иҫ“ пјҢ жҳҫ然йғҪиҰҒйҒөеҫӘеҚҸи®®жқҘи°ғз”Ё гҖӮ еҰӮеӣҫжүҖзӨә пјҢ еҰӮжһңжҲ‘们жҠҠдј иҫ“еҚҸи®®жҜ”дҪңиҪҰ пјҢ жҠҠ SpanContext жҜ”дҪңиҙ§ пјҢ жҠҠ Span жҜ”дҪңи·Ҝеә”иҜҘдјҡжӣҙеҘҪзҗҶи§ЈдёҖдәӣ гҖӮ
зҗҶи§ЈдәҶиҝҷдёүдёӘжҰӮеҝө пјҢ жҺҘдёӢжқҘжҲ‘们е°ұзңӢзңӢеҲҶеёғејҸиҝҪиёӘзі»з»ҹжҳҜеҰӮдҪ•йҮҮйӣҶеӣҫдёӯзҡ„еҫ®жңҚеҠЎи°ғз”Ёй“ҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
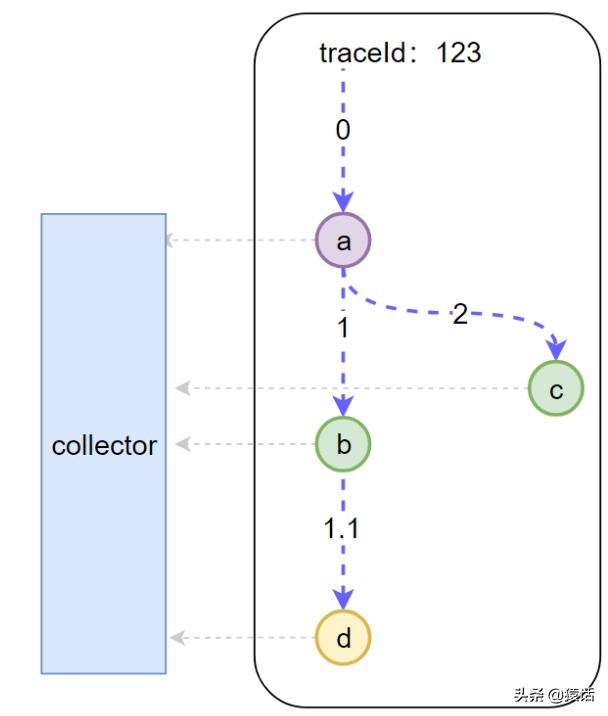
ж–Үз« жҸ’еӣҫжҲ‘们еҸҜд»ҘзңӢеҲ°еә•еұӮжңүдёҖдёӘ Collector дёҖзӣҙеңЁй»ҳй»ҳж— й—»ең°ж”¶йӣҶж•°жҚ® пјҢ йӮЈд№ҲжҜҸдёҖж¬Ўи°ғз”Ё Collector дјҡ收йӣҶе“ӘдәӣдҝЎжҒҜе‘ў гҖӮ
- е…ЁеұҖ trace_idпјҡиҝҷжҳҜжҳҫ然зҡ„ пјҢ иҝҷж ·жүҚиғҪжҠҠжҜҸдёҖдёӘеӯҗи°ғз”ЁдёҺжңҖеҲқзҡ„иҜ·жұӮе…іиҒ”иө·жқҘ
- span_id: еӣҫдёӯзҡ„ 0 пјҢ 1 пјҢ 1.1 пјҢ 2 пјҢ иҝҷж ·е°ұиғҪж ҮиҜҶжҳҜе“ӘдёҖдёӘи°ғз”Ё
- parent_span_idпјҡжҜ”еҰӮ b и°ғз”Ё d зҡ„ span_id жҳҜ 1.1 пјҢ йӮЈд№Ҳе®ғзҡ„ parent_span_id еҚідёә a и°ғз”Ё b зҡ„ span_id еҚі 1 пјҢ иҝҷж ·жүҚиғҪжҠҠдёӨдёӘзҙ§йӮ»зҡ„и°ғз”Ёе…іиҒ”иө·жқҘ гҖӮ
 ж–Үз« жҸ’еӣҫ
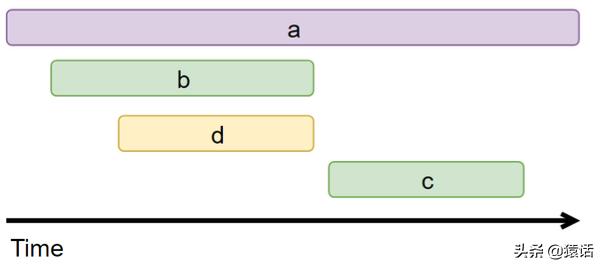
ж–Үз« жҸ’еӣҫж №жҚ®иҝҷдәӣеӣҫиЎЁдҝЎжҒҜжҳҫ然еҸҜд»ҘжҚ®жӯӨжқҘз”»еҮәи°ғз”Ёй“ҫзҡ„еҸҜи§ҶеҢ–и§ҶеӣҫеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫдәҺжҳҜдёҖдёӘе®Ңж•ҙзҡ„еҲҶеёғејҸиҝҪиёӘзі»з»ҹе°ұе®һзҺ°дәҶ гҖӮ
д»ҘдёҠе®һзҺ°зңӢиө·жқҘзЎ®е®һз®ҖеҚ• пјҢ дҪҶжңүд»ҘдёӢеҮ дёӘй—®йўҳйңҖиҰҒжҲ‘们仔з»ҶжҖқиҖғдёҖдёӢпјҡ
- жҖҺд№ҲиҮӘеҠЁйҮҮйӣҶ span ж•°жҚ®пјҡиҮӘеҠЁйҮҮйӣҶ пјҢ еҜ№дёҡеҠЎд»Јз Ғж— дҫөе…Ҙ
- еҰӮдҪ•и·ЁиҝӣзЁӢдј йҖ’ context
- traceId еҰӮдҪ•дҝқиҜҒе…ЁеұҖе”ҜдёҖ
- иҜ·жұӮйҮҸиҝҷд№ҲеӨҡйҮҮйӣҶдјҡдёҚдјҡеҪұе“ҚжҖ§иғҪ
й“ҫи·ҜиҝҪиёӘзі»з»ҹSkyWalkingзҡ„еҺҹзҗҶ1гҖҒжҖҺд№ҲиҮӘеҠЁйҮҮйӣҶ span ж•°жҚ®
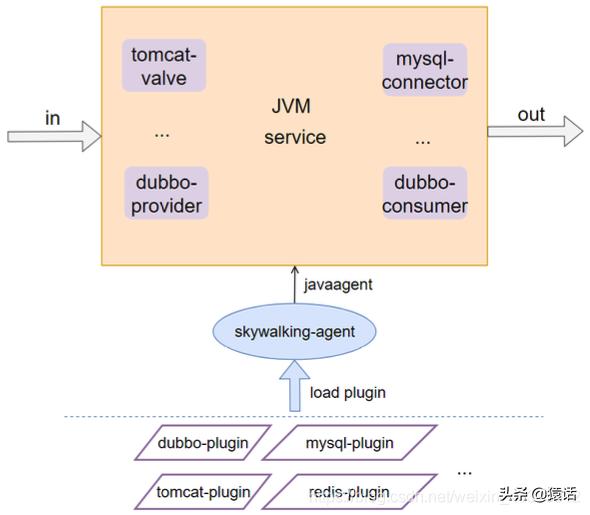
гҖҗгҖҢзі»з»ҹжһ¶жһ„гҖҚд»Җд№ҲжҳҜй“ҫи·ҜиҝҪиёӘпјҹеҲҶеёғејҸзі»з»ҹеҰӮдҪ•е®һзҺ°й“ҫи·ҜиҝҪиёӘпјҹгҖ‘SkyWalking йҮҮз”ЁдәҶжҸ’件еҢ– + javaagent зҡ„еҪўејҸжқҘе®һзҺ°дәҶ span ж•°жҚ®зҡ„иҮӘеҠЁйҮҮйӣҶ пјҢ иҝҷж ·еҸҜд»ҘеҒҡеҲ°еҜ№д»Јз Ғзҡ„ж— дҫөе…ҘжҖ§ гҖӮ жҸ’件еҢ–ж„Ҹе‘ізқҖеҸҜжҸ’жӢ” пјҢ жү©еұ•жҖ§еҘҪ гҖӮ еҰӮдёӢеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
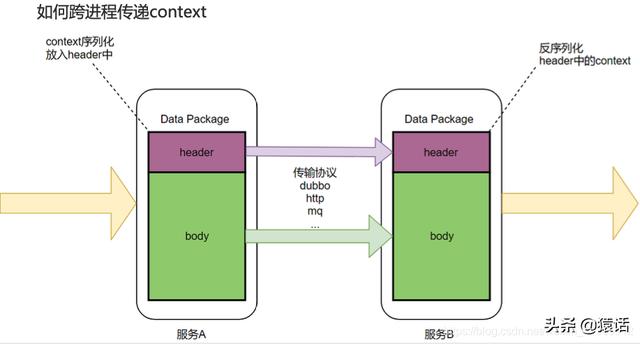
ж–Үз« жҸ’еӣҫ2гҖҒеҰӮдҪ•и·ЁиҝӣзЁӢдј йҖ’ context
жҲ‘们зҹҘйҒ“ж•°жҚ®дёҖиҲ¬еҲҶдёә header е’Ң body пјҢ е°ұеғҸ http жңү header е’Ң body пјҢ RocketMQ д№ҹжңү MessageHeader пјҢ Message Body гҖӮ body дёҖиҲ¬ж”ҫзқҖдёҡеҠЎж•°жҚ® пјҢ жүҖд»ҘдёҚе®ңеңЁ body дёӯдј йҖ’ context пјҢ еә”иҜҘеңЁ header дёӯдј йҖ’ context пјҢ еҰӮеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫdubbo дёӯзҡ„ attachment е°ұзӣёеҪ“дәҺ header пјҢ жүҖд»ҘжҲ‘们жҠҠ context ж”ҫеңЁ attachment дёӯ пјҢ иҝҷж ·е°ұи§ЈеҶідәҶ context зҡ„дј йҖ’й—®йўҳ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»















- й»‘йІЁ4proд»Җд№Ҳж—¶еҖҷеҮәеӨҡе°‘й’ұпјҢй»‘йІЁ4proд»·ж јеҸӮж•°д»Ӣз»Қ
- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- жһҒйҖҹйІЁиҜҫе Ӯ89пјҡдё»жқҝеҗҚеӯ—еёҰWIFIе’ҢдёҚеёҰжңүд»Җд№ҲеҢәеҲ«
- зғҹеҸ°жёҜвҖңз®ЎйҒ“жҷәи„‘зі»з»ҹвҖқдёҠзәҝ еңЁеӣҪеҶ…зҺҮе…Ҳе®һзҺ°еҺҹжІ№еӮЁиҝҗе…ЁжҒҜжҷәиғҪжҺ’дә§
- жҜ”иө·007пјҢ996зңҹзҡ„жҳҜзҰҸжҠҘпјҒдә’иҒ”зҪ‘еӨ§еҺӮдёәд»Җд№ҲеҠ зҸӯйғҪиҝҷд№ҲзӢ пјҹ
- vivoдёҖж¬ҫж–°жңәзҺ°иә«и·‘еҲҶзҪ‘пјҒиҝҗеӯҳе’Ңзі»з»ҹдҝЎжҒҜйҖҡйҖҡжӣқе…ү
- vivoиҝҪжұӮзҡ„жң¬еҺҹи®ҫи®ЎжҳҜд»Җд№ҲпјҹX60 Proз»ҷеҮәдәҶзӯ”жЎҲ