Map的底层实现 & 为什么遍历Map总是乱序的
Golang中Map的底层结构【Map的底层实现 & 为什么遍历Map总是乱序的】其实提到Map , 一般想到的底层实现就是哈希表 , 哈希表的结构主要是Hashcode + 数组 。
- 存储kv时 , 首先将k通过hashcode后对数组长度取余 , 决定需要放入的数组的index
- 当数组对应的index已有元素时 , 此时产生一个【哈希冲突】 。 一般来说哈希冲突的解决方式为链表法 , 即在冲突的位置生成一个链表来存储元素
参考:go语言中文文档:www.topgoer.com
对于哈希表的具体实现和哈希冲突的解决方案这里就不赘述了 , 大家可以去看大神程序员小灰的漫画:什么是HashMap? 。
Redis中的Dict结构(用于实现RedisDB、Hashmap , Set等)其实就是非常典型的哈希表 。 Golang中的Map结构与传统的哈希表稍有不同 , 它数组的基本单元并不是kv对 , 而是bucket 。
每个bucket中可以放置8个kv对 , 这样可以减少对象的数量 , 有利于提升GC的性能;当bucket中放置不下时 , 会继续在溢出桶(overflow)中继续存储 , 串成一个链表的结构 , 如图所示:
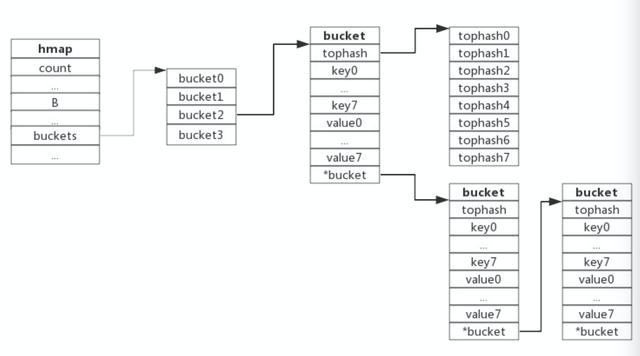 文章插图
文章插图链表法解决哈希冲突
Bucket中结构详解
// map 哈希表type Hmap struct{count int // 元素数量....B uint8 // 哈希表数组的容量大小=2^B...buckets unsafe.PointeroldBuckets unsafe.Pointer // 用于扩容...}// Bucket 桶type bmap struct{tophash [8]uint8 // 哈希值的高8位keysvaluesoverflow *bmap}- key的哈希值的低B位(比如数组大小为32 , 2^5=32 , 则B=5)决定了它放入buckets中的index位置
- key的哈希值的高8位放入bucket中的tophash字段中 , 因为每个bucket中最多可以放8个KV对 , 所以tophash为大小为8的数组:tophash字段可以用于加速key的比较 , 当在一个bucket中查询某key时 , 可以先比较哈希值的高8位是否符合 , 如果符合才会比较对应的key , 这样加速了key比较的过程;
- keys和values为分开存储的 , 因为key和value可能是不同类型 , 比如map[int64]int8 , 分开存储不需要进行字节补齐 , 可以节省空间;
- overflow即溢出桶 , 用于存储哈希冲突后超过8对的kv对
- 扩容时容量翻倍 , 申请一个新的数组 , 采用渐进式哈希的方式进行迁移(和redis类似 , 可以避免影响性能)
- 迁移过程中支持读写:
- 新增kv只写新表
- 修改和删除双写 , 保证新老表中的数据一致
- 读取时优先读老表 , 再读新表
- 迁移过程为每次update/remove操作时触发部分搬迁 , 每次搬迁2部分bucket中的数据:
- 修改的key所在的当前Bucket
- 按照顺序搬迁的一个Bucket(避免某些bucket一直未被访问导致无法搬迁成功)
- 直到所有数据搬迁完成后 , 删除oldBuckets , 使得老哈希表中的Bucket对象被GC回收
结合上文我们说到扩容流程 , 由于扩容过程会新申请一个数组 , 并且将keys重新rehash后放入新的数组中 。 那么新的数组中的key的顺序就改变了 , 因此哈希表的底层实现使得map无法保证稳定地按照同一顺序输出keys 。
Golang的作者为了”提醒“新手程序员不要依赖map遍历时返回的key顺序 , 采用随机选择遍历起始位置的方式使得遍历时返回是乱序的 。
推荐阅读












![[励志视频短片]做好事,微笑挂满两腮才是正道!,早安心语:存好心](https://imgcdn.toutiaoyule.com/20200503/20200503054140414532a_t.jpeg)




- 可与ASML实现联机!国产光刻机传来喜讯,张绍忠预言或成真?
- 烟台港“管道智脑系统”上线 在国内率先实现原油储运全息智能排产
- 想实现《曼达洛人》的数字布景吗?索尼模块化屏幕即将开售
- 快递员工也能当“教授”?上海快递工程技术高级职称评审实现突破
- 资本的价值观:996是福报?底层人物就是用命换钱?
- 骁龙888首次实现可变分辨率渲染 创造沉浸式游戏体验
- 柔宇FlexPai 2实现多次重复折叠无折痕,斩获CES 2021创新奖
- 飞步无人车:实现首个混线工况下的自动驾驶集卡编队独立整船作业
- 荣耀、高通相继宣布,雷军迎来大敌?任正非的预言正在实现
- 李炳忠自我打脸,去年realme销量翻番的目标远未实现