京东推荐系统中的兴趣拓展如何驱动业务持续增长( 五 )
基于 Listwise 全局建模的兴趣重排序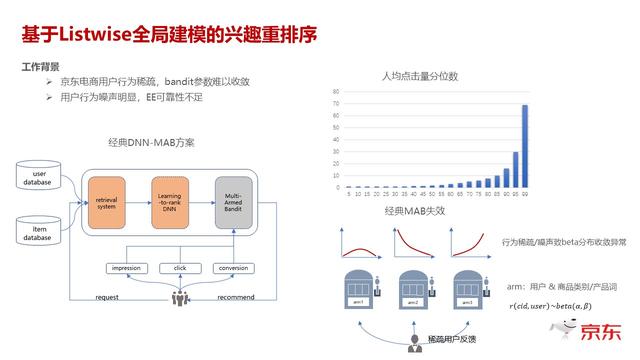 文章插图
文章插图
讲完 CTR , 最后 , 我们再来看一下 , 当我们预估出来 CTR 值和 CVR 值以后 , 对每条预估出来的结果进行最终的排序 。 正常情况下 , 如果不考虑多样性 , 不考虑 Explore 这些特征 , 其实只要按 CTR 预估值从高到低排就行了 。 如果按照这种方式排序 , 那么你 Explore 出来的东西 , 大概率是出不来的 。 传统的方式是 , 我会在 CTR 预估后面再加一个 Explore 层 。 我这里画了一个用户人均点击的分类图 , 可以看到 , 绝大部分用户的点击都是处于长尾的 , 用户行为很少 , 如果画商品 , 分布趋势会更明显 。 因为我们数十亿的商品可能绝大部分都是有用户行为特别稀疏的 。 最早我们尝试这个事情的时候 , 用多臂老虎机 , 我们基于每个用户看过或者点击过的商品的品类和产品词来做 arm 。 那么在用户行为缺失的情况下出现的问题 , 要么就是多臂老虎机基于 Data 函数 , 学到的 Beta 分布 , 要么就是数据量太少 , 它是不收敛的 , 要么就是几个正例 , 或者几个负例 , 实际上是带着噪音性质的 , 所以它画出来 Beta 分布出的曲线 , 都是因为稀疏 , 或者是噪声导致整个 Beta 分布是没办法收敛的 。
我们做的一个尝试 , 就是做聚类 。 其实就是简单地基于用户整个的 Session 行为 , 把商品和用户都转成对应的 embedding , 基于 embedding 之后 , 做简单的 kmeans 聚类 , 一个用户簇和一个商品簇 , 这两个的组合构成了我们的一个 arm 。 因为聚类后的簇是可以控制的 , 你可以通过超参去寻优的 。 从 Beta 收敛情况能够很明显地看到 , 聚完簇之后 , 每个簇内的行为 , 都是相对充分的 , 那么不管是哪种情况 , 它都能比较快地进入收敛状态 。 这是我们跟一些常见的方法做的一些对比 , 我们这个方法最大的优势在于 , 在做 Explore 时候 , 它其实没有牺牲点击 , 因为正常大家都会觉得 , 我去做 Explore 之后 , 那一定是探索一些用户没表达出来的东西 , 那么这个东西一定是不那么相关的 , 点击率会下降 , 或者是说一些排序类相关性的指标会下降 。 但是这个方法 , 在我们的数据里验证的结果 , 不管是从离线还是在线结果来看 , 它是能够同时做到点击基本上持平略涨的情况下 , 多样性有了显著的提升 。 在线的效果是 , 用户的下拉深度 , 也就是用户浏览的时长有了一个非常显著的提升 。
前面讲了 Explore , 就是我们把用户不感兴趣的商品 , 没有明确表达感兴趣的商品探索出来 , 但是探索出来的东西和用户已经表达出感兴趣的东西怎么做合理的组合?怎么呈现给用户最终的那个合理的队列?这是排序里要解决的另一个问题 。
 文章插图
文章插图
上图中 , 大家看一下左边的示意图 。 我们发现用户已经主动浏览了一些手机和图书 , 那么我通过一些其他的行为能够猜测出 , 他还会感兴趣的东西是耳机和茶叶 , 那么我怎么去做合理的搭配?这里边举了一些例子 , 如果说你做得不合理 , 有可能出现的是大量已知的兴趣 , 或者反过来 , 大量的结果是你 Explore 的 , 不管哪种情况 , 效率都是低的 , 甚至是说你两种情况都搭配出来 , 但是如果说他们呈现出来的顺序不合理 , 那么最后的效果也是不好的 。
所以它的核心的问题是 CTR 预估或者 CVR 预估可能是几百 , 或者千这个级别的侯选集合 , 在这个集合里面 , 怎么出来一个最终的队列 , 让用户看到的这个队列是效果最优的?最简单的思想就是 , 我用贪婪的方式 , 我先挑那个最好的 , 然后后面就是类似于队列生成的过程 , 那么基于第一个 , 去生成第二个 , 基于第二个去生成第三个 , 依此类推 。 如果再综合一下性能和效果 , 那么可能每次不是生成出来一个 , 而是生成出来 N 个 , 也就是说是 context 序列生成 , 再加一个 BeamSearch 这个过程 , 这是通常的几种方式 。
推荐阅读

















- 谷歌建立新AI系统 可开发甜品配方
- 目前配置全性价比高的手机,我只推荐五款,闭着眼买都不会错
- 曾被京东物流效仿,让雷军花1亿拯救,如今欠7000万彻底出局
- 诺基亚为何宁可逐渐没落也不采用Android系统?长知识了
- 离开华为的新荣耀枯木难支?首款手机就被冷落,京东预约数太难看
- 烟台港“管道智脑系统”上线 在国内率先实现原油储运全息智能排产
- vivo一款新机现身跑分网!运存和系统信息通通曝光
- 徐福记联手JDL京东物流向数智化转型,首次落地智慧园区项目
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 多家快递暂停发往河北省快件,顺丰表示先暂停三天,京东小程序已无法下单