еҝ«йҖҹжҺҢжҸЎHTTP1.0 1.1 2.0 3.0зҡ„зү№зӮ№еҸҠе…¶еҢәеҲ«( дёү )
еҗ‘еүҚзә й”ҷзүәзүІдәҶжҜҸдёӘж•°жҚ®еҢ…еҸҜд»ҘеҸ‘йҖҒж•°жҚ®зҡ„дёҠйҷҗ пјҢ дҪҶжҳҜеёҰжқҘзҡ„жҸҗеҚҮеӨ§дәҺдёўеҢ…еҜјиҮҙзҡ„ж•°жҚ®йҮҚдј пјҢ еӣ дёәж•°жҚ®йҮҚдј е°Ҷдјҡж¶ҲиҖ—жӣҙеӨҡзҡ„ж—¶й—ҙпјҲеҢ…жӢ¬зЎ®и®Өж•°жҚ®еҢ…дёўеӨұ пјҢ иҜ·жұӮйҮҚдј пјҢ зӯүеҫ…ж–°ж•°жҚ®еҢ…зӯүжӯҘйӘӨзҡ„ж—¶й—ҙж¶ҲиҖ—пјү гҖӮ
дҫӢеҰӮпјҡ
- жҲ‘жҖ»е…ұеҸ‘йҖҒдёүдёӘеҢ… пјҢ еҚҸи®®дјҡз®—еҮәиҝҷдёӘдёүдёӘеҢ…зҡ„ејӮжҲ–еҖје№¶еҚ•зӢ¬еҸ‘еҮәдёҖдёӘж ЎйӘҢеҢ… пјҢ д№ҹе°ұжҳҜжҖ»е…ұеҸ‘еҮәдәҶеӣӣдёӘеҢ… гҖӮ
- еҪ“е…¶дёӯеҮәзҺ°дәҶйқһж ЎйӘҢеҢ…дёўеӨұзҡ„жғ…еҶө пјҢ еҸҜд»ҘйҖҡиҝҮеҸҰеӨ–дёүдёӘеҢ…и®Ўз®—еҮәдёўеӨұзҡ„ж•°жҚ®еҢ…зҡ„еҶ…е®№ гҖӮ
- еҪ“然иҝҷз§ҚжҠҖжңҜеҸӘиғҪдҪҝз”ЁеңЁдёўеӨұдёҖдёӘеҢ…зҡ„жғ…еҶөдёӢ пјҢ еҰӮжһңеҮәзҺ°дёўеӨұеӨҡдёӘеҢ… пјҢ е°ұдёҚиғҪдҪҝз”Ёзә й”ҷжңәеҲ¶дәҶ пјҢ еҸӘиғҪдҪҝз”ЁйҮҚдј зҡ„ж–№ејҸдәҶ гҖӮ
еңЁеӨҙйғЁеҺӢзј©жҠҖжңҜдёӯ пјҢ е®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁеқҮдјҡз»ҙжҠӨдёӨд»ҪзӣёеҗҢзҡ„йқҷжҖҒеӯ—е…ёе’ҢеҠЁжҖҒеӯ—е…ё гҖӮ
еңЁйқҷжҖҒеӯ—е…ёдёӯ пјҢ еҢ…еҗ«дәҶеёёи§Ғзҡ„еӨҙйғЁеҗҚз§°дёҺеҖјзҡ„з»„еҗҲ гҖӮ йқҷжҖҒеӯ—е…ёеңЁйҰ–ж¬ЎиҜ·жұӮж—¶еҸҜд»ҘдҪҝз”Ё гҖӮ йӮЈд№ҲзҺ°еңЁеӨҙйғЁзҡ„еӯ—ж®өе°ұеҸҜд»Ҙиў«з®ҖеҶҷжҲҗйқҷжҖҒеӯ—е…ёдёӯзӣёеә”еӯ—ж®өзҡ„index гҖӮ
иҖҢеҠЁжҖҒеӯ—е…ёи·ҹиҝһжҺҘзҡ„дёҠдёӢж–Үзӣёе…і пјҢ жҜҸдёӘHTTP/2иҝһжҺҘз»ҙжҠӨзҡ„еҠЁжҖҒеӯ—е…ёдёҚе°ҪзӣёеҗҢ гҖӮ еҠЁжҖҒеӯ—е…ёеҸҜд»ҘеңЁиҝһжҺҘдёҚеҒңең°иҝӣиЎҢжӣҙж–° гҖӮ
д№ҹе°ұжҳҜиҜҙ пјҢ еҺҹжң¬е®Ңж•ҙзҡ„HTTPжҠҘж–ҮеӨҙйғЁзҡ„й”®еҖјжҲ–еӯ—ж®ө пјҢ з”ұдәҺеӯ—е…ёзҡ„еӯҳеңЁ пјҢ зҺ°еңЁеҸҜд»ҘиҪ¬жҚўжҲҗзҙўеј•index пјҢ еңЁзӣёеә”зҡ„з«ҜеҶҚиҝӣиЎҢжҹҘжүҫиҝҳеҺҹ пјҢ д№ҹе°ұиө·еҲ°дәҶеҺӢзј©зҡ„дҪңз”Ё гҖӮ
жүҖд»Ҙ пјҢ еҗҢдёҖдёӘй“ҫжҺҘдёҠдә§з”ҹзҡ„иҜ·жұӮе’Ңе“Қеә”и¶ҠеӨҡ пјҢ еҠЁжҖҒеӯ—е…ёзҙҜз§Ҝеҫ—и¶Ҡе…Ё пјҢ еӨҙйғЁеҺӢзј©зҡ„ж•Ҳжһңд№ҹе°ұи¶ҠеҘҪ пјҢ жүҖд»Ҙй’ҲеҜ№HTTP/2зҪ‘з«ҷ пјҢ жңҖдҪіе®һи·өжҳҜдёҚиҰҒеҗҲ并иө„жәҗ гҖӮ
еҸҰеӨ– пјҢ HTTP2.0еӨҡи·ҜеӨҚз”Ё пјҢ дҪҝеҫ—иҜ·жұӮеҸҜд»Ҙ并иЎҢдј иҫ“ пјҢ иҖҢHTTP1.1еҗҲ并иҜ·жұӮзҡ„дёҖдёӘеҺҹеӣ д№ҹжҳҜдёәдәҶйҳІжӯўиҝҮеӨҡзҡ„HTTPиҜ·жұӮеёҰжқҘзҡ„йҳ»еЎһй—®йўҳ гҖӮ иҖҢзҺ°еңЁHTTP2.0е·Із»ҸиғҪеӨҹ并иЎҢдј иҫ“дәҶ пјҢ жүҖд»ҘеҗҲ并иҜ·жұӮд№ҹе°ұжІЎжңүеҝ…иҰҒдәҶ гҖӮ
дёәд»Җд№ҲиҰҒжңүHTTP3.0пјҡHTTP/2еә•еұӮTCPзҡ„еұҖйҷҗеёҰжқҘзҡ„й—®йўҳз”ұдәҺHTTP/2дҪҝз”ЁдәҶеӨҡи·ҜеӨҚз”Ё пјҢ дёҖиҲ¬жқҘиҜҙ пјҢ еҗҢдёҖдёӘеҹҹеҗҚдёӢеҸӘйңҖиҰҒдҪҝз”ЁдёҖдёӘTCPй“ҫжҺҘ пјҢ дҪҶеҪ“иҝҷдёӘиҝһжҺҘдёӯеҮәзҺ°дәҶдёўеҢ…зҡ„жғ…еҶө пјҢ е°ұдјҡеҜјиҮҙHTTP/2зҡ„иЎЁзҺ°жғ…еҶөеҸҚеҖ’дёҚеҰӮHTTP/2дәҶ гҖӮ
еҺҹеӣ жҳҜпјҡ еңЁеҮәзҺ°дёўеҢ…зҡ„йўқжғ…еҶөдёӢ пјҢ ж•ҙдёӘTCPйғҪиҰҒејҖе§Ӣзӯүеҫ…йҮҚдј пјҢ еҜјиҮҙеҗҺйқўзҡ„жүҖжңүж•°жҚ®йғҪиў«йҳ»еЎһ гҖӮ
дҪҶжҳҜеҜ№дәҺHTTP/1.1жқҘиҜҙ пјҢ еҸҜд»ҘејҖеҗҜеӨҡдёӘTCPиҝһжҺҘ пјҢ еҮәзҺ°иҝҷз§Қжғ…еҶөеҸӘдјҡеҪұе“Қе…¶дёӯдёҖдёӘиҝһжҺҘ пјҢ еү©дҪҷзҡ„TCPй“ҫжҺҘиҝҳеҸҜд»ҘжӯЈеёёдј иҫ“ж•°жҚ® гҖӮ
з”ұдәҺдҝ®ж”№TCPеҚҸи®®жҳҜдёҚеҸҜиғҪе®ҢжҲҗзҡ„д»»еҠЎ гҖӮ
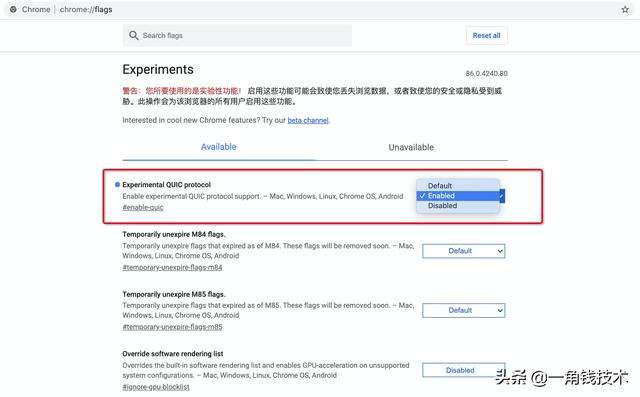
еҰӮдҪ•еңЁChromeдёӯеҗҜз”Ё QUIC еҚҸи®®MTFеңЁиө„жәҗжңҚеҠЎеҷЁе’ҢеҶ…е®№еҲҶеҸ‘иҠӮзӮ№йғҪе·Із»ҸеҗҜз”ЁдәҶ HTTP3.0 еҚҸи®® пјҢ ж №жҚ® з”ЁжҲ·жөҸи§ҲеҷЁ еҗ‘дёӢе…је®№ пјҢ ејәзғҲе»әи®®жӮЁеңЁChromeжөҸи§ҲеҷЁејҖеҗҜе®һйӘҢжҖ§QUICKеҚҸи®®ж”ҜжҢҒ пјҢ дҪ“йӘҢеҠ йҖҹж•Ҳжһңпјҡ
- еңЁжөҸи§ҲеҷЁең°еқҖж Ҹпјҡиҫ“е…Ҙchrome://flags
- жүҫеҲ°Experimental QUIC protocol пјҢ е°ҶDefaultж”№дёәEnabled
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҖ»з»“HTTP 1.0
- ж— зҠ¶жҖҒ пјҢ ж— иҝһжҺҘ
- зҹӯиҝһжҺҘпјҡжҜҸж¬ЎеҸ‘йҖҒиҜ·жұӮйғҪиҰҒйҮҚж–°е»әз«ӢtcpиҜ·жұӮ пјҢ еҚідёүж¬ЎжҸЎжүӢ пјҢ йқһеёёжөӘиҙ№жҖ§иғҪ
- ж— hostеӨҙеҹҹ пјҢ д№ҹе°ұжҳҜhttpиҜ·жұӮеӨҙйҮҢзҡ„host пјҢ
- дёҚе…Ғи®ёж–ӯзӮ№з»ӯдј пјҢ иҖҢдё”дёҚиғҪеҸӘдј иҫ“еҜ№иұЎзҡ„дёҖйғЁеҲҶ пјҢ иҰҒжұӮдј иҫ“ж•ҙдёӘеҜ№иұЎ
- й•ҝиҝһжҺҘ пјҢ жөҒж°ҙзәҝ пјҢ дҪҝз”Ёconnection:keep-aliveдҪҝз”Ёй•ҝиҝһжҺҘ
- иҜ·жұӮз®ЎйҒ“еҢ–
- еўһеҠ зј“еӯҳеӨ„зҗҶпјҲж–°зҡ„еӯ—ж®өеҰӮcache-controlпјү
- еўһеҠ Hostеӯ—ж®ө пјҢ ж”ҜжҢҒж–ӯзӮ№дј иҫ“зӯү
- з”ұдәҺй•ҝиҝһжҺҘдјҡз»ҷжңҚеҠЎеҷЁйҖ жҲҗеҺӢеҠӣ
- дәҢиҝӣеҲ¶еҲҶеё§
- еӨҙйғЁеҺӢзј© пјҢ еҸҢж–№еҗ„иҮӘз»ҙжҠӨдёҖдёӘheaderзҡ„зҙўеј•иЎЁ пјҢ дҪҝеҫ—дёҚйңҖиҰҒзӣҙжҺҘеҸ‘йҖҒеҖј пјҢ йҖҡиҝҮеҸ‘йҖҒkeyзј©еҮҸеӨҙйғЁеӨ§е°Ҹ
- еӨҡи·ҜеӨҚз”ЁпјҲжҲ–иҝһжҺҘе…ұдә«пјү пјҢ дҪҝз”ЁеӨҡдёӘstream пјҢ жҜҸдёӘstreamеҸҲеҲҶеё§дј иҫ“ пјҢ дҪҝеҫ—дёҖдёӘtcpиҝһжҺҘиғҪеӨҹеӨ„зҗҶеӨҡдёӘhttpиҜ·жұӮ
- жңҚеҠЎеҷЁжҺЁйҖҒпјҲSever pushпјү
жҺЁиҚҗйҳ…иҜ»












![[еҠұеҝ—и§Ҷйў‘зҹӯзүҮ]еҒҡеҘҪдәӢпјҢеҫ®з¬‘жҢӮж»ЎдёӨи…®жүҚжҳҜжӯЈйҒ“пјҒпјҢж—©е®үеҝғиҜӯпјҡеӯҳеҘҪеҝғ](https://imgcdn.toutiaoyule.com/20200503/20200503054140414532a_t.jpeg)




- вҖңеҚғеә—еҗҢејҖвҖқеј•иҙЁйҮҸжӢ…еҝ§пјҢе°Ҹзұіеӣһеә”
- дјҒдёҡ|жҠҖжңҜеҝ«йҖҹиҝӯд»ЈеҖ’йҖјзҹҘиҜҶдә§жқғвҖңиҙҙиә«вҖқжңҚеҠЎпјҢдёҠжө·йҰ–家AIе•Ҷж Үе“ҒзүҢжҢҮеҜјз«ҷе…Ҙй©»еҫҗжұҮиҘҝеІё
- жҜ”еҺҹеӯҗеј№иҝҳзЁҖжңүпјҢе…Ёзҗғе°ұдёӨеӣҪжҺҢжҸЎпјҢе…үеҲ»жңәдёәд»Җд№ҲеҰӮжӯӨйҡҫйҖ пјҹ
- дёүжҳҹGalaxy A52 5GйҖҡиҝҮ3Cи®ӨиҜҒ ж”ҜжҢҒжңҖй«ҳ15Wеҝ«йҖҹе……з”ө
- еңЁзәҝж•ҷиӮІйҷ·е…ҘжҢҒд№…жҲҳ дҪңдёҡеё®еҮӯвҖңй•ҝжңҹдё»д№үвҖқжҺҢжҸЎдё»еҠЁжқғ
- еӨ§еҒҘеә·йҖҹйҖ’дёЁи…ҫи®ҜдёҠзәҝз–«иӢ—жҺҘз§ҚжңҚеҠЎеҢәпјӣеҚҺеӨ§еҹәеӣ з ”еҸ‘еҮәеҝ«йҖҹйүҙе®ҡзӣ’
- DeepMindж–°AIж— йңҖжҸҗеүҚзҹҘжҷ“规еҲҷд№ҹиғҪжҺҢжҸЎжёёжҲҸпјҡж— и®әи§Ҷи§үз®ҖеҚ•иҝҳжҳҜеӨҚжқӮ
- е°ҸзұіиҒ”еҗҲдә¬дёңеҸҠзҲұеӣһ收жҺЁе…Ёж–°жҚўжңәжңҚеҠЎ её®дҪ еҝ«йҖҹжҚўж–°жңә
- иҘҝе®үеҘ•ж–ҜдјҹзЎ…дә§дёҡеҹәең°йЎ№зӣ®е»әи®ҫеҲ·ж–°жҲ‘еӣҪе»әи®ҫеӨ§зЎ…зүҮеҲ¶йҖ йЎ№зӣ®зҡ„жңҖеҝ«йҖҹеәҰ
- зҪ‘з»ң|дёҮзү©дә’иҒ”пјҢжӣҙзҰ»дёҚејҖзҪ‘з»ңж–ҮжҳҺ