жҜ”з”ңе“ҒеҚЎжӣҙз”ңпјҒжҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢ( дёү )
иҖҢе…үзәҝиҝҪиёӘжңҖиҖ—ж—¶зҡ„жӯЈжҳҜжұӮдәӨи®Ўз®— пјҢ еӣ жӯӨ пјҢ иҰҒжҸҗеҚҮе…үзәҝиҝҪиёӘжҖ§иғҪ пјҢ дё»иҰҒжҳҜеҜ№дёӨз§ҚжұӮдәӨпјҲBVH/дёүи§’еҪўжұӮдәӨпјүиҝӣиЎҢеҠ йҖҹ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
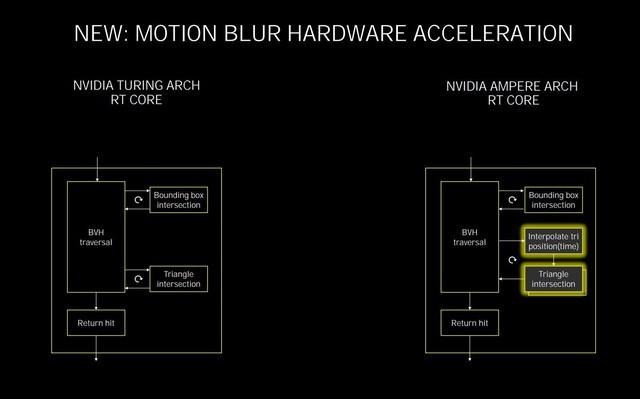
RT Coreзҡ„еҸҳеҢ–
еңЁTuringзҡ„RT Coreдёӯ пјҢ еҸҜд»ҘжҜҸдёӘе‘Ёжңҹе®ҢжҲҗ5ж¬ЎBVHйҒҚеҺҶгҖҒ4ж¬ЎBVHжұӮдәӨд»ҘеҸҠдёҖж¬Ўдёүи§’еҪўжұӮдәӨ пјҢ еңЁз¬¬дәҢд»ЈRT Core йҮҢ пјҢ NVIDIAеўһеҠ дәҶдёҖдёӘж–°зҡ„дёүи§’еҪўдҪҚзҪ®жҸ’еҖјжЁЎеқ—д»ҘеҸҠдёҖдёӘзҡ„йўқеӨ–зҡ„дёүи§’еҪўжұӮдәӨжЁЎеқ— пјҢ иҝҷж ·еҒҡзҡ„зӣ®зҡ„жҳҜдёәдәҶжҸҗеҚҮиҜёеҰӮиҝҗеҠЁжЁЎзіҠзү№ж•Ҳж—¶еҖҷзҡ„е…үзәҝиҝҪиёӘжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
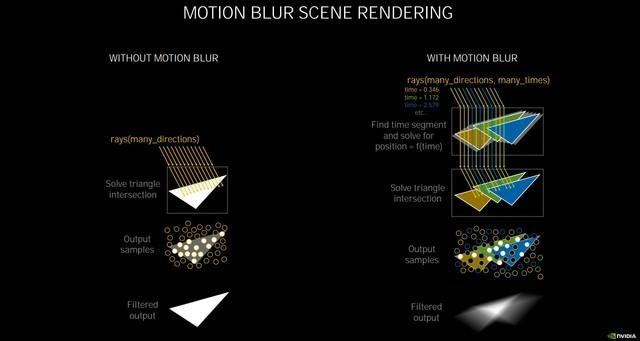
иҝҗеҠЁжЁЎзіҠжёІжҹ“еҺҹзҗҶ
第дәҢд»ЈRT CoreеҸҜд»Ҙи®©е…үзәҝиҝҪиёӘдёҺзқҖиүІеҗҢж—¶иҝӣиЎҢ пјҢ иҝӣиЎҢзҡ„е…үзәҝиҝҪиёӘи¶ҠеӨҡ пјҢ еҠ йҖҹе°ұи¶Ҡеҝ« пјҢ е®ғе°Ҷе…үзәҝзӣёдәӨзҡ„еӨ„зҗҶжҖ§иғҪжҸҗеҚҮдәҶдёҖеҖҚ пјҢ еңЁжёІжҹ“жңүеҠЁжҖҒжЁЎзіҠзҡ„еҪұеғҸж—¶ пјҢ жҢүз…§NVIDIAиҮӘе·ұзҡ„е®һжөӢ пјҢ жҜ”Turingеҝ«8еҖҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
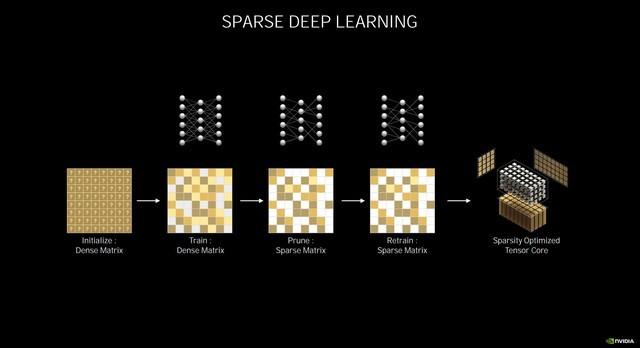
зЁҖз–Ҹж·ұеәҰеӯҰд№
Tensor CoreеҸҜд»ҘзңӢдҪңжҳҜGeForce RTX GPUдёҠзҡ„AIеӨ§и„‘ гҖӮ еҸҜеҠ йҖҹз”ЁдәҺж·ұеәҰзҘһз»ҸзҪ‘з»ңеӨ„зҗҶеҠҹиғҪзҡ„зәҝжҖ§д»Јж•° пјҢ иҝҷжҳҜзҺ°д»ЈAIзҡ„еҹәзЎҖ гҖӮ дҫӢеҰӮз”ЁдәҺAIи¶…еҲҶиҫЁзҺҮзҡ„NVIDIA DLSSе’Ңз”ЁдәҺAIеўһејәзҡ„еЈ°з”»еӨ„зҗҶжҠҖжңҜNVIDIA Broadcastеә”з”Ё гҖӮ
еңЁжң¬ж¬Ўзҡ„NVIDIA Ampereжһ¶жһ„зҡ„Tensor Coreд№ҹеҫ—еҲ°дәҶжһҒеӨ§ең°еҠ ејә пјҢ еңЁз¬¬дёүд»ЈTensor Coreдёӯ пјҢ NVIDIAеј•е…ҘдәҶзЁҖз–ҸеҢ–еҠ йҖҹ пјҢ еҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNпјҲж·ұеәҰзҘһз»ҸзҪ‘з»ңпјүжқғйҮҚ пјҢ еҗҢж—¶дҫқ然иғҪдҝқжҢҒдёҚй”ҷзҡ„зІҫеәҰ гҖӮ
йҰ–е…ҲеҺҹе§Ӣзҡ„еҜҶйӣҶзҹ©йҳөдјҡз»ҸиҝҮи®ӯз»ғ пјҢ еҲ йҷӨжҺүзЁҖз–Ҹзҹ©йҳө пјҢ еҶҚз»ҸиҝҮи®ӯз»ғзЁҖз–Ҹзҹ©йҳө пјҢ д»ҺиҖҢе®һзҺ°зЁҖз–ҸдјҳеҢ– пјҢ иҝӣиҖҢжҸҗй«ҳTensor Coreзҡ„жҖ§иғҪ гҖӮ
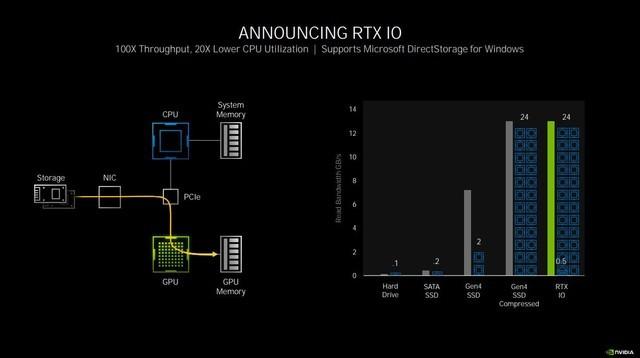
дёҺжӯӨж¬ЎRTX 30зі»жҳҫеҚЎдёҖеҗҢеҸ‘еёғзҡ„иҝҳжңүдёҖйЎ№ж–°жҠҖжңҜвҖ”вҖ”RTX IO гҖӮ зӣ®еүҚеҫҲеӨҡжёёжҲҸеҠЁиҫ„еҮ еҚҒGз”ҡиҮізҷҫGзҡ„е®үиЈ…з©әй—ҙ пјҢ еҜ№дәҺеӯҳеӮЁз©әй—ҙзҡ„иҙҹжӢ…жҡӮдё”дёҚжҸҗ пјҢ дҪҶеӯҳж”ҫеңЁзЎ¬зӣҳдёӯзҡ„ж•°жҚ® пјҢ еҰӮжһңжҳҫеҚЎжғіиҰҒиҜ»еҸ–еҲ° пјҢ йңҖиҰҒе…Ҳз”ұCPUд»ҺзЎ¬зӣҳдёӯиҜ»еҸ–еҺӢзј©иҝҮзҡ„ж•°жҚ® пјҢ з»ҸиҝҮи§ЈеҺӢзј©еҶҚеҸ‘йҖҒеҲ°жҳҫеӯҳдёӯ гҖӮ
иҷҪ然йҡҸзқҖNVMe SSDзҡ„жҺЁеҮә пјҢ иҜ»еҸ–йҖҹеәҰзӣёиҫғжңәжў°зЎ¬зӣҳиғҪеӨҹеҝ«20еҖҚ пјҢ дҪҶеҸ—еҲ¶дәҺдј з»ҹI/OйҷҗеҲ¶ пјҢ NVMeй«ҳиҫҫ7GB/з§’зҡ„й«ҳйҖҹиҜ»еҶҷеҜ№дәҺCPUжҳҜжһҒеӨ§зҡ„иҙҹжӢ… гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
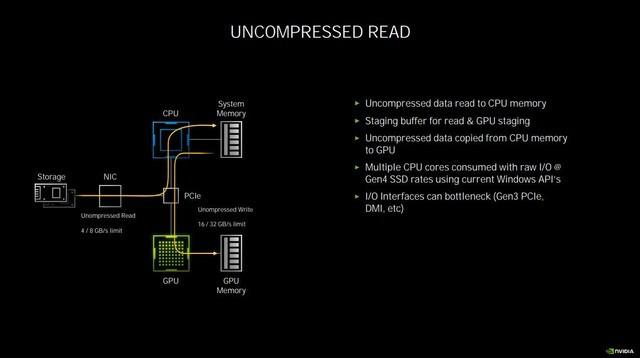
дј з»ҹзҡ„ж•°жҚ®дәӨжҚў
еңЁиҝҷдёӘиҝҮзЁӢдёӯ пјҢ дјҡеҚ з”ЁеӨҡдёӘCPUж ёеҝғ пјҢ еҺӢеҠӣжҖҘеү§еўһеӨ§ пјҢ еҚ з”ЁиҫғеӨҡзҡ„еҶ…еӯҳ пјҢ иҖҢжӯӨж—¶е…¶е®һGPUжҳҜеӨ„дәҺй—ІзҪ®зҠ¶жҖҒзҡ„ гҖӮ RTX IOзҡ„дҪңз”Ёе°ұжҳҜи¶ҠиҝҮCPUи§ЈеҺӢеҶҚдј иҫ“ж•°жҚ®иҝҷдёҖжӯҘ пјҢ зӣҙжҺҘд»ҺPCIEжҖ»зәҝиҜ»еҸ–зЎ¬зӣҳдёҠз»ҸиҝҮеҺӢзј©зҡ„ж•°жҚ® пјҢ 并且е®ҢжҲҗж— жҚҹGPUи§ЈеҺӢ пјҢ йҷҚдҪҺCPUеҚ з”Ё пјҢ еҸҳеҗ‘жҸҗеҚҮдәҶжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
RTX IOеҸҜд»ҘжһҒеӨ§и§Јж”ҫCPUиҙҹжӢ…
еҪ“然иҝҷйЎ№жҠҖжңҜдҪңдёәзі»з»ҹеә•еұӮзҡ„иҝҗиЎҢж–№ејҸж”№еҸҳ пјҢ иҝҳйңҖиҰҒеҖҹеҠ©еҫ®иҪҜеҸ‘еёғзҡ„DirectStorageжқҘе®һзҺ° пјҢ еҜ№дәҺзӣ®еүҚе®№йҮҸзҡ„жёёжҲҸжқҘиҜҙ пјҢ RTX IOзҡ„ж”№е–„ж•Ҳжһңжңүйҷҗ пјҢ дҪҶеҒҮд»Ҙж—¶ж—ҘзӯүжёёжҲҸе®№йҮҸдёҠзҷҫGжҲҗдёәеёёжҖҒзҡ„ж—¶еҖҷ пјҢ иҝҷйЎ№жҠҖжңҜе°ҶдјҡеҸ‘жҢҘе·ЁеӨ§зҡ„еҠҹж•Ҳ гҖӮ
еҗҢж—¶жҗӯй…Қж–°еўһзҡ„HDMI 2.1жҺҘеҸЈ пјҢ еҸҜд»Ҙж”ҜжҢҒеҚ•зәҝ8Kзҡ„и§Ҷйў‘иҫ“еҮә пјҢ иҖҢдёҠдёҖд»ЈHDMI 2.0д»…ж”ҜжҢҒ4K 98Hzзҡ„и§Ҷйў‘иҫ“еҮә пјҢ еҰӮжһңжғіиҰҒиҝһжҺҘ8Kз”өи§Ҷ пјҢ еҲҷйңҖиҰҒжӣҙеӨҡзҡ„зәҝзјҶж”ҜжҢҒ гҖӮ
033D MARKзҗҶи®әжҖ§иғҪжөӢиҜ•
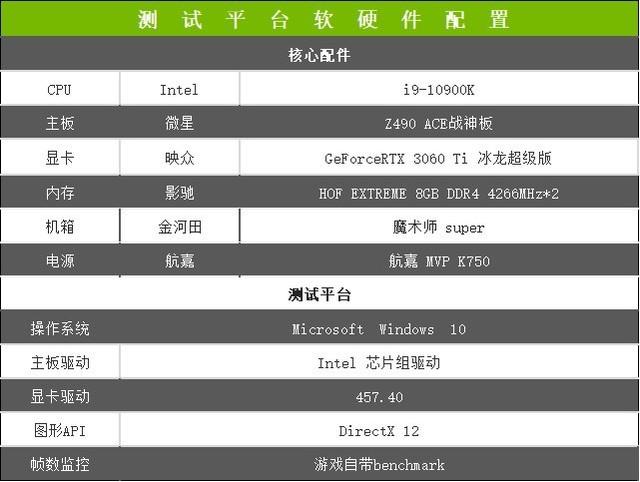
йҰ–е…Ҳд»Ӣз»ҚдёҖдёӢжөӢиҜ•е№іеҸ° пјҢ дёәдәҶдҝқиҜҒжӯӨж¬ЎиҜ„жөӢиғҪеӨҹеҸ‘жҢҘжҳ дј—GeForce RTX 3060 TiеҶ°йҫҷи¶…зә§зүҲжҳҫеҚЎзҡ„жңҖдҪіжҖ§иғҪ пјҢ дё»жқҝе’ҢCPUйҮҮз”ЁдәҶзӣ®еүҚжЎҢйқўж——иҲ°зә§й…ҚзҪ® пјҢ е…·дҪ“еҰӮдёӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
й…ҚзҪ®дҝЎжҒҜ
еңЁжөӢиҜ•жҲҗз»©дёҠ пјҢ еҹәеҮҶжөӢиҜ•йҮҮз”Ё3DMARK пјҢ жёёжҲҸжҖ§иғҪжөӢиҜ•дҪҝз”ЁжёёжҲҸиҮӘеёҰBenchmark пјҢ еҗҢж—¶дёәдәҶеҮҸе°ҸиҜҜе·® пјҢ жҜҸйЎ№жөӢиҜ•жҲҗз»©еқҮжөӢиҜ•3йҒҚеҸ–е№іеқҮеҖј гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- з•…зҲҪ2077 иҖ•еҚҮRTX 3060Ti жҳҹжһҒз”ңе“Ғж–°йҖүжӢ©
- дёүеӨҙе…ӯиҮӮй’ӣејәжӮҚ жҳ дј—RTX3060TIжҳҫеҚЎйҰ–еҸ‘
- е…үиҝҪз”ңе“ҒдҝҜи§ҶдёҠд»Јж¬Ўж——иҲ° жҠҖеҳүGEFORCE RTX 3060Tiйӯ”й№°PROйҰ–еҸ‘иҜ„жөӢ
- жҳ дј—RTX3090еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢпјҡејәеҠІж•Јзғӯе®үеҝғи¶…йў‘
- дё»жөҒд»·дҪҚз”ңе“ҒжёёжҲҸжң¬ж–°йҖүжӢ©пјҢе®ҸзўҒжҺ еӨәиҖ…жҲҳж–§300иҜ„жөӢ
- зҺ°иұЎзә§жҳҫеҚЎеҶҚеәҰйҷҚдёҙпјҢ第дәҢд»Је…үиҝҪз”ңе“Ғ666пјҒзҙўжі° GeForce RTX 3060Ti-8GD6еӨ©еҗҜ OCйҰ–еҸ‘иҜ„жөӢ
- жҳ дј—RTX 3080еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢпјҡ4йЈҺжүҮзҡ„еҶ°йҫҷеӣһжқҘдәҶ
- еҚҺзЎ•йЈһиЎҢе Ўеһ’8йҫҷзҸ йҷҗе®ҡзүҲ з”ңе“Ғзә§жҳҫеҚЎеёҰжқҘжҪңеҠӣж— йҷҗ
- жҳҫеҚЎ|з”ЁдәҶ3е№ҙзҡ„GTX1060пјҢзҺ°еңЁеҚҮзә§е“ӘдёҖж¬ҫжҳҫеҚЎжӣҙеҲ’з®—пјҹ