жҜ”з”ңе“ҒеҚЎжӣҙз”ңпјҒжҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲ
жҳ дј—GeForce RTX 3060 TiеҶ°йҫҷи¶…зә§зүҲжҳҫеҚЎеҹәдәҺNVIDIAе…¬зүҲж–№жЎҲ пјҢ й…ҚеӨҮдәҶ6+2зӣёдҫӣз”ө пјҢ з”өжәҗйғЁеҲҶжҳҫеҚЎйҮҮз”Ё8PinжҺҘеҸЈи®ҫи®ЎпјҢ дҪҝз”ЁдёҠдёҖд»ЈжҳҫеҚЎзҡ„зҺ©е®¶еҸҜд»ҘиҪ»жқҫиҝҮжёЎ пјҢ дҪҝз”Ё600Wд»ҘдёҠз”өжәҗзҡ„зҺ©е®¶ж— йңҖжӣҙжҚўз”өжәҗеҚіеҸҜе®һзҺ°жӢ”жҸ’еҚҮзә§ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲ
еңЁи§Ҷйў‘иҫ“еҮәжҺҘеҸЈдёҠ пјҢ жҳ дј—GeForce RTX 3060 TiеҶ°йҫҷи¶…зә§зүҲжҳҫеҚЎйҮҮз”ЁDP*3+HDMI 2.1зҡ„4жҺҘеҸЈи®ҫи®Ў пјҢ е……еҲҶж»Ўи¶із”ЁжҲ·зҡ„жү©еұ•йңҖжұӮпјӣеҸҰеӨ–з”ұдәҺжң¬ж¬ЎHDMI 2.1зҡ„еҚҮзә§ пјҢ иҜҘжҺҘеҸЈеҸҜж”ҜжҢҒеҚ•зәҝ8Kзҡ„и§Ҷйў‘иҫ“еҮәпјӣеҗҢж—¶жҺҘеҸЈдёҠиҝҳйҮҮз”ЁдәҶй•ҖйҮ‘и®ҫи®Ў пјҢ дёҚжҳ“иў«ж°§еҢ– пјҢ жңүж•Ҳ延й•ҝжҺҘеҸЈзҡ„еҜҝе‘Ҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲ
02NVIDIA Ampereжһ¶жһ„дёӢRTX 3060 Ti
жҳ дј—RTX 3060 Ti еҶ°йҫҷи¶…зә§зүҲйҮҮз”ЁдәҶNVIDIA Ampereжһ¶жһ„ пјҢ жҲ‘们йҰ–е…ҲжқҘзңӢдёҖдёӢRTX 3060 Tiзҡ„жҸҗеҚҮ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дёҖд»ЈRTXжһ¶жһ„ TuringдёӢзҡ„RTX 2060 SUPER
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дәҢд»ЈRTXжһ¶жһ„ AmpereдёӢзҡ„RTX 3060 Ti
зӣёиҫғдәҺеҲқд»Јзҡ„Turing RTXжһ¶жһ„ пјҢ NVIDIAAmpereжһ¶жһ„еңЁз®—еҠӣдёҠжңүзқҖжҲҗеҖҚзҡ„еўһй•ҝ пјҢ иҝҷдёҖзӮ№еңЁRTX 3060 Tiдёӯдҫқж—§жңүдҪ“зҺ° пјҢ жҜҸдёӘж—¶й’ҹжү§иЎҢ2ж¬ЎзқҖиүІеҷЁиҝҗз®— пјҢ иҖҢTuringдёә1ж¬Ў пјҢ RTX 3060 Tiзҡ„зқҖиүІеҷЁжҖ§иғҪиҫҫеҲ°16.2 TFLOPSеҚ•зІҫеәҰжҖ§иғҪ пјҢ иҖҢTuringдёә7.2 TFLOPS гҖӮ
NVIDIAAmpereжһ¶жһ„зҝ»еҖҚдәҶе…үзәҝдёҺдёүи§’еҪўзҡ„зӣёдәӨеҗһеҗҗйҮҸ пјҢ RT CoreиҫҫеҲ°31.6 RTTFLOPS пјҢ иҖҢTuringдёә21.7 RT TFLOPS гҖӮ
е…Ёж–°зҡ„Tensor CoreеҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNжқғйҮҚ пјҢ еӨ„зҗҶзЁҖз–ҸзҪ‘з»ңзҡ„йҖҹзҺҮжҳҜTuringзҡ„дёӨеҖҚ пјҢ з®—еҠӣй«ҳиҫҫ129.6 TensorTFLOPS пјҢ иҖҢTuringдёә57.4 TensorTFLOPS гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
RTX 3060 TiйҮҮз”ЁGA104ж ёеҝғжӢҘжңү174дәҝдёӘжҷ¶дҪ“з®Ў пјҢ 392е№іж–№жҜ«зұізҡ„йқўз§Ҝ пјҢ еҹәдәҺдёүжҳҹзҡ„8nm NVIDIAе®ҡеҲ¶е·Ҙиүә пјҢ еҸҰеӨ–еңЁRTX 3060 TiдёӯжҲ‘们йғҪзҹҘйҒ“д»Қ然йҮҮз”ЁдәҶGDDR6жҳҫеӯҳ пјҢ дёҚиҝҮдёҚеҗҢдәҺRTX 3080зҡ„Micron пјҢ RTX 3060 TiйҮҮз”ЁдәҶдёүжҳҹзҡ„GDDR6жҳҫеӯҳ гҖӮ
жҲ‘们еңЁеҸ‘еёғдјҡдёӯз»Ҹеёёеҗ¬еҲ°жҖ§иғҪзҝ»еҖҚзҡ„иҜҙжі• пјҢ е…¶е®һжҳҜеӣ дёәжң¬ж¬ЎNVIDIAAmpereзҡ„SMеңЁTuringеҹәзЎҖдёҠеўһеҠ дәҶдёҖеҖҚзҡ„FP32иҝҗз®—еҚ•е…ғ пјҢ иҝҷе°ұдҪҝеҫ—жҜҸдёӘSMзҡ„FP32иҝҗз®—еҚ•е…ғж•°йҮҸжҸҗй«ҳдәҶдёҖеҖҚ пјҢ еҗҢж—¶еҗһеҗҗйҮҸд№ҹе°ұеҸҳдёәдәҶдёҖеҖҚ гҖӮ
иҖҢйҖҡеёёжҲ‘们计算жҳҫеҚЎзҡ„CUDAж•°йҮҸ пјҢ 并дёҚжҳҜжҠҠSMдёӯзҡ„жүҖжңүеҚ•е…ғеҠ иө·жқҘи®Ўж•° пјҢ иҖҢжҳҜеҸӘз»ҹи®ЎFP32еҚ•е…ғзҡ„ж•°йҮҸ пјҢ жүҖд»Ҙиҝҷж ·дёҖжқҘ пјҢ SMдёӯзҡ„гҖҗFP32 : INT32гҖ‘ д»Һ 1:1 еҸҳдёә 2:1 гҖӮ
RTX 3060 Tiе…ұжңү4864дёӘCUDA пјҢ е…¶е®һе®ғжңү2432дёӘINT32еҚ•е…ғ пјҢ дҪҶз”ұдәҺеҶ…йғЁзҡ„FP32ж•°йҮҸзҝ»дәҶдёҖеҖҚ пјҢ жүҖд»ҘжңҖз»Ҳе®һзҺ°дәҶ4864иҝҷдёӘжғҠдәәзҡ„ж•°еӯ— гҖӮ
иҖҢиҝҷж ·зІ—жҡҙзҡ„жҸҗеҚҮCUDAж•°йҮҸеҜ№дәҺжёёжҲҸе…¶е®һжңүзқҖйқһеёёеӨ§зҡ„её®еҠ© пјҢ йҖҡеёёеңЁжёёжҲҸдёӯжө®зӮ№иҝҗз®—зӣёжҜ”ж•ҙж•°и®Ўз®—иҰҒеёёз”Ёзҡ„еӨҡ пјҢ еӣҫеҪўгҖҒз®—жі•д»ҘеҸҠеҗ„з§Қи®Ўз®—ж“ҚдҪңдёӯзқҖиүІеҷЁе·ҘдҪңиҙҹиҪҪйҖҡеёёйңҖиҰҒж··еҗҲдҪҝз”ЁFP32з®—ж•°жҢҮд»Ө пјҢ иҖҢFP32зҡ„еҠ йҖҹд№ҹжңүеҠ©дәҺе…үзәҝиҝҪиёӘйҷҚеҷӘзқҖиүІеҷЁ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…үиҝҪе·ҘдҪңеҺҹзҗҶзӨәж„Ҹ
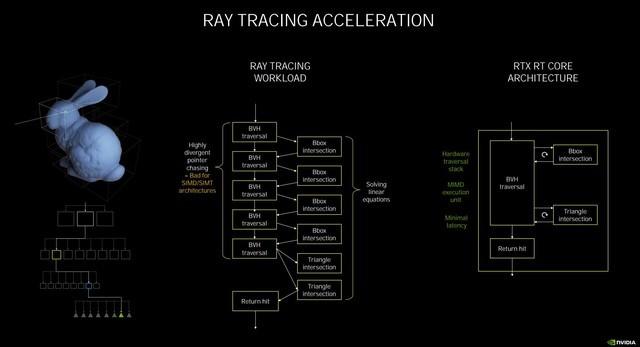
еңЁжӯӨж¬Ўзҡ„NVIDIAAmpereжһ¶жһ„дёӯ пјҢ NVIDIAе®ҳж–№е®Јеёғдёә第дәҢд»ЈRT Core пјҢ е®ғе’Ң第дёҖд»Јжңүд»Җд№ҲдёҚеҗҢе‘ў гҖӮ йҰ–е…ҲиҰҒзҹҘйҒ“RT Coreзҡ„е·ҘдҪңеҺҹзҗҶжҳҜ пјҢ зқҖиүІеҷЁеҸ‘еҮәе…үзәҝиҝҪиёӘзҡ„иҜ·жұӮ пјҢ дәӨз»ҷRT CoreжқҘеӨ„зҗҶ пјҢ е®ғе°ҶиҝӣиЎҢдёӨз§ҚжөӢиҜ• пјҢ еҲҶеҲ«дёәиҫ№з•ҢдәӨеҸүжөӢиҜ•пјҲBox Intersection testingпјүе’Ңдёүи§’еҪўдәӨеҸүжөӢиҜ•пјҲTriangle Intersectiontestingпјү гҖӮ еҹәдәҺBVHз®—жі•жқҘеҲӨж–ӯ пјҢ еҰӮжһңжҳҜж–№еҪў пјҢ йӮЈд№Ҳе°ұиҝ”еӣһзј©е°ҸиҢғеӣҙ继з»ӯжөӢиҜ• пјҢ еҰӮжһңжҳҜдёүи§’еҪў пјҢ еҲҷеҸҚйҰҲз»“жһңиҝӣиЎҢжёІжҹ“ гҖӮ
жҺЁиҚҗйҳ…иҜ»





![[д»қеҚ“]д»қеҚ“дёәй«ҳиҖғиҲһејҠйҒ“жӯүпјҢзІүдёқзӣІзӣ®еҠӣжҢәпјҡеҮӯе®һеҠӣиҖғдёҠпјҢеӨ§е®¶жІЎеҝ…иҰҒйҖјд»–](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/1bcffc01b5f09cc7043a0f3818fe8f3e.jpg)









- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- з•…зҲҪ2077 иҖ•еҚҮRTX 3060Ti жҳҹжһҒз”ңе“Ғж–°йҖүжӢ©
- дёүеӨҙе…ӯиҮӮй’ӣејәжӮҚ жҳ дј—RTX3060TIжҳҫеҚЎйҰ–еҸ‘
- е…үиҝҪз”ңе“ҒдҝҜи§ҶдёҠд»Јж¬Ўж——иҲ° жҠҖеҳүGEFORCE RTX 3060Tiйӯ”й№°PROйҰ–еҸ‘иҜ„жөӢ
- жҳ дј—RTX3090еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢпјҡејәеҠІж•Јзғӯе®үеҝғи¶…йў‘
- дё»жөҒд»·дҪҚз”ңе“ҒжёёжҲҸжң¬ж–°йҖүжӢ©пјҢе®ҸзўҒжҺ еӨәиҖ…жҲҳж–§300иҜ„жөӢ
- зҺ°иұЎзә§жҳҫеҚЎеҶҚеәҰйҷҚдёҙпјҢ第дәҢд»Је…үиҝҪз”ңе“Ғ666пјҒзҙўжі° GeForce RTX 3060Ti-8GD6еӨ©еҗҜ OCйҰ–еҸ‘иҜ„жөӢ
- жҳ дј—RTX 3080еҶ°йҫҷи¶…зә§зүҲиҜ„жөӢпјҡ4йЈҺжүҮзҡ„еҶ°йҫҷеӣһжқҘдәҶ
- еҚҺзЎ•йЈһиЎҢе Ўеһ’8йҫҷзҸ йҷҗе®ҡзүҲ з”ңе“Ғзә§жҳҫеҚЎеёҰжқҘжҪңеҠӣж— йҷҗ
- жҳҫеҚЎ|з”ЁдәҶ3е№ҙзҡ„GTX1060пјҢзҺ°еңЁеҚҮзә§е“ӘдёҖж¬ҫжҳҫеҚЎжӣҙеҲ’з®—пјҹ