清华大学黄高——图像数据的语义层扩增方法
2020 年 9 月 25 日 , 在由中国科协主办 , 清华大学计算机科学与技术系、AI TIME 论道承办的《2020 中国科技峰会系列活动青年科学家沙龙——人工智能学术生态与产业创新》上 , 清华大学自动化系助理教授黄高博士进行了题为《图像数据的语义层扩增方法》的主题报告 , 黄高博士于 2015 年博士毕业于清华大学 , 主要的研究方向为深度学习、计算机视觉、强化学习 。
 文章插图
文章插图
图 1:深度神经网络的语义数据扩增
【清华大学黄高——图像数据的语义层扩增方法】深度学习的成功主要依赖于三个重要的因素:大数据、大计算以及算法模型的创新 , 这三个要素缺一不可 。 目前 , 有大量的研究聚焦于新的模型和算法 , 而从事硬件和架构相关研究的人员会关注如何把硬件做的更好、并行度更高 。 相比之下 , 学术界对大数据的关注热度有所下降 , 很多人似乎默认我们现在已经拥有大量可用的数据 。 然而 , 在实际应用中 , 真正拥有大量高质量标注数据的场景还是非常少的 , 人工标注数据的成本十分高昂 。
 文章插图
文章插图
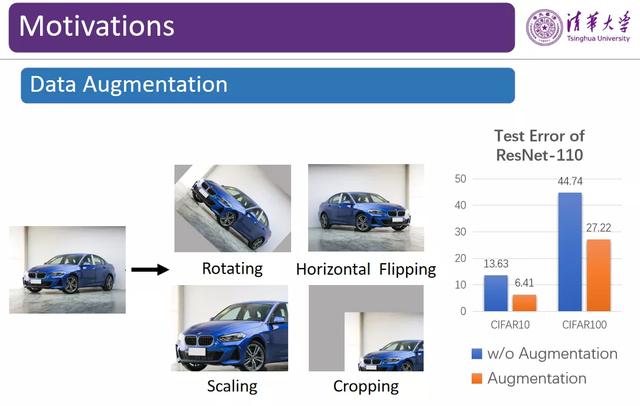
图 2:数据扩增
在标注数据不足的情况下 , 数据扩增是一种非常有效的提升模型性能的方法 。 如图 2 所示 , 在右侧的柱状图中 , 我们比较了在相同的实验设置(优化器、训练时长等)下在 CIFAR-10/CIFAR-100 数据集上进行数据扩增前后的测试误差 , 其中蓝色代表未使用数据扩增的实验结果 , 橙色代表使用数据扩增的实验结果 。 在 CIFAR-10 数据集上 , 测试误差从 13.6% 降至 6.4%;在 CIFAR-100 数据集上 , 测试误差从 44% 降至 27% , 模型的性能提升十分显著 。 相对于深度学习模型和其它方面的优化 , 数据扩增的有效性举足轻重 。
对于图像数据而言 , 我们可以对其进行一系列变换来实现数据扩增 。 例如 , 对于图 2 中的汽车图像 , 我们可以对原始的汽车图像应用旋转、左右翻转、裁剪、放缩等变换 , 这并不会改变图像的类别 。 通过这种方式 , 我们可以根据一张图像扩展出多张图像 , 有效地增加训练数据 , 防止模型的过拟合现象 。
 文章插图
文章插图
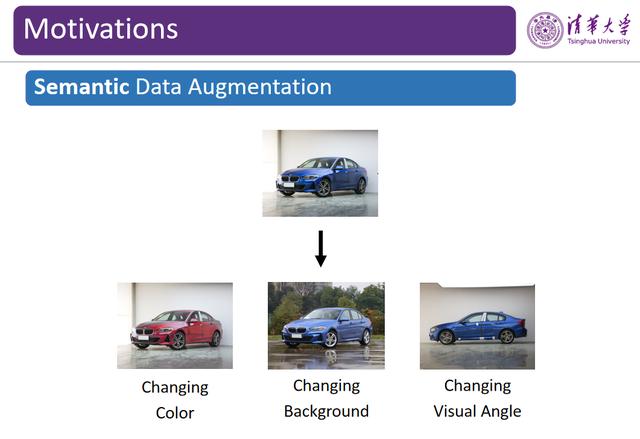
图 3:语义数据增强
为了进一步提升数据扩增的效果 , 我们试图进行更加高级的变换 。 例如 , 我们把可以更换汽车的颜色、切换一个观测视角、或者换一个车标 , 此时它仍然是一辆汽车 。 然而 , 相较于前文提到的旋转、翻转、裁剪等简单变换 , 这类相对「高级」的变换要困难得多 , 我们将其称为「语义数据增强」 。 在这里 , 我们将重点讨论如何实现更好的语义数据增强 。
 文章插图
文章插图
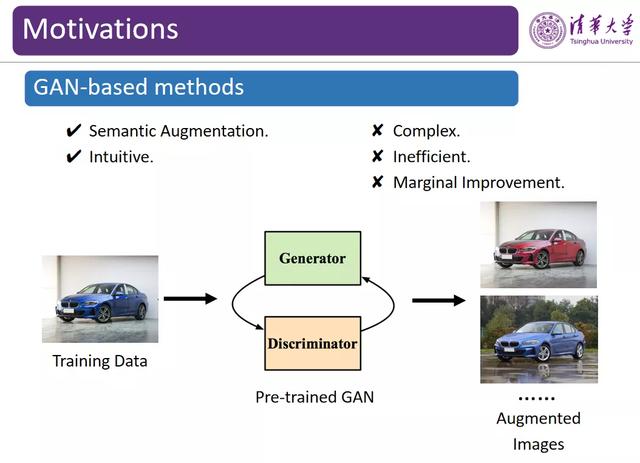
图 4:基于 GAN 的语义数据增强
目前 , 研究人员已经提出了一些进行语义数据增强的方法 。 例如 , 利用所有汽车的图像构建一个数据集 , 从而形成一个数据分布 , 其中每一类包含数十到数百张图像 。 我们可以使用该数据集训练一个对抗生成网络(GAN) , 并利用训练好的 GAN 生成无穷无尽的汽车图像 。 然而 , 基于 GAN 的方法存在诸多弊端:首先 , GAN 的训练十分困难 。 该方法将引入大量额外的计算量 , 其优化过程也十分不稳定 。 其次 , 此类方法对模型性能的提升较为有限 。 通常 , 数据集中每个类别的图像大致有数十到数百张 , 而我们只能针对每一个类别训练一个 GAN 。 尽管我们也可以使用 Conditional GAN(CGAN)类的方法 , 但是 GAN 生成的图像质量仍然较差 。 如果我们使用这样生成的数据训练下游的分类器 , 只能得到微弱的模型性能提升 。
推荐阅读







![[火星]火星有座奥林匹斯山,如果搬到地球,估计没人能爬到峰顶](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/588e44cac7127eef7b786c7914d9347f.jpg)








- 苹果地图车正在以色列、新西兰和新加坡售价Look Around图像
- Caviar恳请撤回Galaxy S21 Ultra限量版图像 外媒对此感到不解
- “像”由“芯”生:中国打造自主高端图像传感器芯片
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验
- Firefox 火狐浏览器将默认支持 AVIF 图像格式,教你在 84.0 版本开启
- Mozilla Firefox已经准备好默认启用AVIF图像处理支持
- 计算机基础:图形、图像相关知识笔记
- 清华大学这所研究院落地珠海!聚焦粤港澳大湾区智慧医疗发展
- Looking Glass Portrait相框开始预购 可以将图像转换成3D全息图显示
- 基于opencv图像处理对交通路口的红绿灯进行颜色检测