ZipInputStream е’Ң RSA з®—жі•зҡ„зә и‘ӣ
иғҢжҷҜд»ҘеүҚе®һзҺ°иҝҮдёҖдёӘзі»з»ҹеҚҮзә§ж“ҚдҪңпјҡйҖҡиҝҮдёҠдј zip еҺӢзј©еҢ…гҖҒ并йҖҡиҝҮ RMI ж–№ејҸи°ғз”ЁеҸҰдёҖдёӘ Java зЁӢеәҸжү§иЎҢupgrade.sh и„ҡжң¬е®ҢжҲҗзҡ„ гҖӮ е…¶дёӯжңүдёҖдёӘзі»з»ҹзүҲжң¬дҝЎжҒҜж ЎйӘҢзҡ„йҖ»иҫ‘ пјҢ зүҲжң¬дҝЎжҒҜжҳҜдёҖж®өз»ҸиҝҮ RSA з®—жі•еҠ еҜҶзҡ„ xml дҝЎжҒҜ пјҢ зӣҙжҺҘжү“еҢ…еҲ° zip ж–Ү件дёӯ гҖӮ
зі»з»ҹеҚҮзә§ж“ҚдҪң пјҢ йҰ–е…ҲдјҡеҜ№ zipж–Ү件дёӯзҡ„зүҲжң¬жҸҸиҝ°дҝЎжҒҜиҝӣиЎҢи§ЈеҜҶ пјҢ дёҺеҪ“еүҚзі»з»ҹж•°жҚ®еә“дёӯз»ҙжҠӨзҡ„зүҲжң¬дҝЎжҒҜиҝӣиЎҢжҜ”еҜ№ пјҢ ж ЎйӘҢйҖҡиҝҮжүҚиҝҗиЎҢжү§иЎҢеҚҮзә§ж“ҚдҪң гҖӮ
иҜҘеҠҹиғҪеӯҳеңЁдёҖдёӘиҜЎејӮзҡ„й—®йўҳ пјҢ еҸӘжңүжҲ‘жң¬жңәзҡ„ 360еҺӢзј©е·Ҙе…·з”ҹжҲҗзҡ„ zip ж–Ү件 пјҢ и§ЈеҜҶд»Јз ҒжүҚдёҚдјҡеҮәй”ҷ пјҢ иҖҢз”Ё winRAR жҲ–иҖ… 7Zip е·Ҙе…·з”ҹжҲҗзҡ„еҺӢзј©ж–Ү件йғҪжҠҘи§ЈеҜҶејӮеёё гҖӮ
иҝҷдёӘй—®йўҳеӣ°жү°дәҶжҲ‘дёҖе№ҙ пјҢ еӣ дёәиҝҷдёӘдёҚеёёз”Ёзҡ„еҠҹиғҪ пјҢ жүҖд»Ҙзјәйҷ·еҸӘжңүжҲ‘зҹҘйҒ“ гҖӮ дҪҶжҳҜ пјҢ иҝҷжҳҜдёӘеӨ§еқ‘ пјҢ еҰӮжһңдёҚи§ЈеҶі пјҢ дёҮдёҖжҲ‘зҡ„з”өи„‘жҢӮдәҶжҲ–иҖ…зҰ»иҒҢдәҶ пјҢ иҝҷдёӘеҠҹиғҪе°ұж— жі•жӯЈеёёиҝҗиҪ¬дәҶ гҖӮ
жҹҗдёҖеӨ©жІЎдәӢе„ҝ пјҢ жғізқҖжҠҠиҝҷдёӘеқ‘жҠ№е№і пјҢ е°ұдёӢеҶіеҝғиҰҒжүҫжүҫеҺҹеӣ гҖӮ жңҖз»ҲжүҫеҲ°ж №жәҗдәҶ пјҢ жң¬ж–ҮжқҘеҲҶдә«дёҖдёӢ Java IO ж“ҚдҪңдёӯзҡ„еқ‘ гҖӮ
зӣҙжҺҘиҜ»еҸ– ZIP ж–Ү件еҚҮзә§ж“ҚдҪңзӣҙжҺҘиҜ»еҸ–zipж–Ү件жөҒдёӯзҡ„еҠ еҜҶеҜҶж–Ү пјҢ Java зӣҙжҺҘиҜ»еҸ– Zipж–Ү件зҡ„жөҒзЁӢеҰӮдёӢпјҡ
public static void readFromZip(String zipFileName) throws IOException{ZipFile zf = null;InputStream in = null;ZipInputStream zin = null;try{zf = new ZipFile(zipFileName);in = new BufferedInputStream(new FileInputStream(zipFileName));zin = new ZipInputStream(in);ZipEntry ze = null;while ((ze = zin.getNextEntry()) != null) {String zipName = ze.getName();if(zipName.contains("descriptor")){//жүҫеҲ°еҜҶж–Үж–Ү件并иҜ»еҸ–InputStream inputStream = zf.getInputStream(ze);byte[] data = http://kandian.youth.cn/index/new byte[inputStream.available()];int len = 0;while ((len = inputStream.read(data))> 0) {System.out.println("length:"+len);}System.out.println("data is :"+Arrays.toString(data));}}} finally {try {zin.closeEntry();in.close();zf.close();} catch (IOException e1) {e1.printStackTrace();}} }зӣҙжҺҘдҪҝз”Ё ZipInputStreamзұ» пјҢ йҖҗдёӘйҒҚеҺҶеҺӢзј©еҢ…дёӯзҡ„жҜҸдёӘж–Ү件 пјҢ жүҫеҲ°еҠ еҜҶж–Ү件еҗҺиҜ»еҸ–иҜҘж–Ү件зҡ„еҶ…е®№еҲ°еӯ—иҠӮж•°з»„дёӯ гҖӮ иҝҷйҮҢеӨ„зҗҶж—¶жңүдёҖдёӘй—®йўҳ пјҢ Java еҜ№дёҚеҗҢеҺӢзј©е·Ҙе…·з”ҹжҲҗзҡ„еҺӢзј©ж–Ү件еӨ„зҗҶж–№ејҸжңүе·®ејӮ гҖӮ
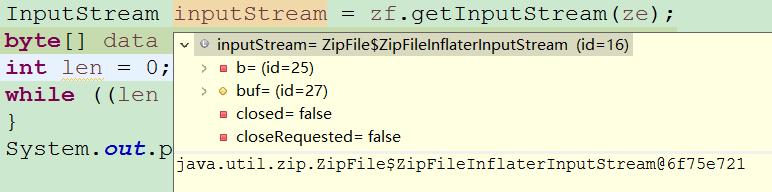
дёҚеҗҢеҺӢзј©е·Ҙе…·зҡ„еҜ№еә”Javaе®һзҺ°зҡ„е·®ејӮ1 гҖҒWinRARеҺӢзј©ж–Ү件еңЁдҪҝз”ЁJava IOе·Ҙе…·иҜ»еҸ–ж—¶ пјҢ zf.getInputStream()жөҒзҡ„е®һдҫӢеҜ№иұЎдёәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷдёӘзұ»зҡ„read(data)ж“ҚдҪң пјҢ еҲҶдәҶдёӨж¬ЎжүҚиҜ»е®Ңж•°жҚ® гҖӮ жү§иЎҢжү“еҚ°з»“жһңдёәпјҡ
length:765length:3
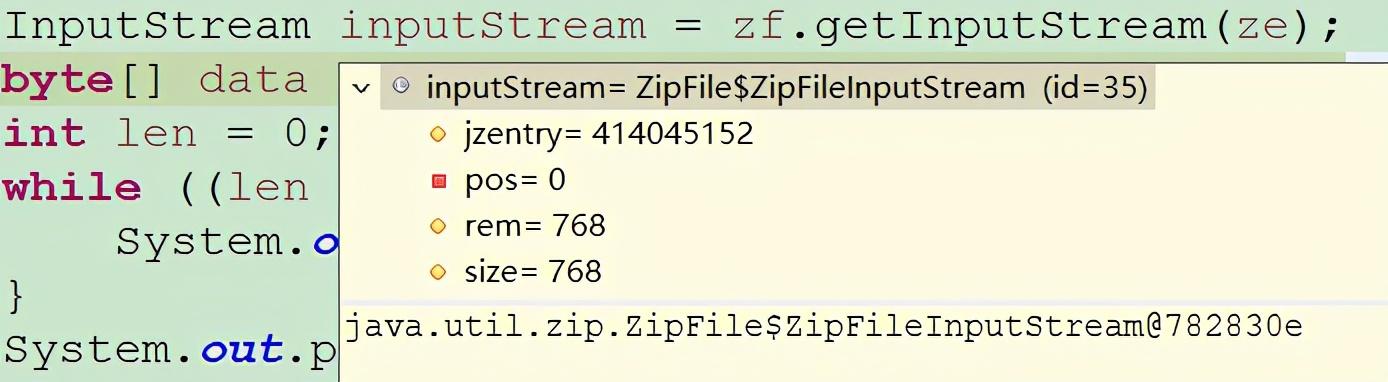
2гҖҒ360еҺӢзј©ж–Ү件еңЁдҪҝз”ЁJava IOе·Ҙе…·иҜ»еҸ–ж—¶ пјҢ zf.getInputStream()жөҒзҡ„е®һдҫӢеҜ№иұЎдёәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷдёӘзұ»зҡ„read(data)ж“ҚдҪң пјҢ дёҖж¬ЎиҜ»е®Ңж•°жҚ® гҖӮ жү§иЎҢжү“еҚ°з»“жһңдёәпјҡ
length:768
дҪҝз”ЁBufferedInputStream пјҢ е®ҡд№үзј“еӯҳеҸ–еҗҺ пјҢ дёӨз§ҚжөҒйғҪиғҪдёҖж¬ЎиҜ»е®ҢеҠ еҜҶж•°жҚ® гҖӮ
public static byte[] bufferedReadFromInputStream(InputStream inputstream) throws IOException{BufferedInputStream bufferedInputStream = new BufferedInputStream(inputstream);byte[] data = http://kandian.youth.cn/index/new byte[inputstream.available()];int len = 0;while ((len = bufferedInputStream.read(data))> 0) {}return data; }иҝҷжҳҜеӣ дёәеҺҹе§Ӣзҡ„ InputStream зҡ„read()ж“ҚдҪң пјҢ жҳҜжҜҸе®ҢжҲҗдёҖж¬Ў IO иҜ»еҸ– пјҢ е°ұеҫҖеҶ…йғЁзј“еҶІеҢәжү§иЎҢеҶҷе…ҘдёҖж¬Ўж•°жҚ®пјӣиҖҢзј“еҶІеҢәе®ҡд№үеҗҺ пјҢ еҸӘжңүзј“еҶІеҢәеҶҷж»ЎжҲ–иҖ…иҜ»дёҚеҲ°ж•°жҚ®ж—¶жүҚеҶҷе…ҘеҶ…еӯҳ пјҢ иҝҷе°ұиғҪдҝқиҜҒжҜҸж¬ЎеҶҷе…ҘеҶ…еӯҳж—¶зҡ„ж•°жҚ®й•ҝеәҰжҳҜжңүдҝқйҡңзҡ„ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- еҗ‘ж—Ҙи‘өиҝңзЁӢжҺ§еҲ¶дјҒдёҡзүҲе®ўжҲ·з«Ҝжӣҙж–°еҚҮзә§пјҢдјҳеҢ–иҝңжҺ§UIйҖӮй…ҚSADDCеҶ…ж ёз®—жі•
- еңЁи°·жӯҢз®—жі•жӣҙж–°д№ӢеҗҺ2020е№ҙзӣ—зүҲзҪ‘з«ҷжөҒйҮҸй”җеҮҸдёүеҲҶд№ӢдёҖ
- иҜҰи§Је·ҘзЁӢеёҲдёҚеҸҜдёҚдјҡзҡ„LRUзј“еӯҳж·ҳжұ°з®—жі•
- д»ҠеӨ©дёҠжө·иҝҷдёӘжҜ”иөӣдёҠпјҢиҺ·еҘ–вҖңзЁӢеәҸеӘӣвҖқи®Іиҝ°дәҶиҮӘе·ұдёҺз®—жі•зҡ„зҲұжҒЁжғ…д»Ү
- з®—жі•иҗҢж–°еҰӮдҪ•еӯҰеҘҪеҠЁжҖҒ规еҲ’пјҲ3пјү
- иҝҷеңәиөӣдәӢзҡ„дё»и§’жҳҜз®—жі•пјҒвҖ”вҖ”йҰ–еұҠBPAAе…Ёзҗғз®—жі•жңҖдҪіе®һи·өе…ёиҢғеӨ§иөӣеңЁдёҠжө·еҗҜеҠЁ
- и°·жӯҢAIеҸҲиҺ·йҮҚеӨ§зӘҒз ҙпјҒж–°з®—жі•ж— йңҖдәҶ解规еҲҷд№ҹиғҪиҮӘеӯҰжҲҗвҖңжЈӢвҖқ
- зұіе®¶йЈһеҲ©жөҰеҸ°зҒҜ3еҸ‘е”®пјҡ199е…ғгҖҒAAзә§з…§еәҰ+иҮӘеҠЁз®—жі•и°ғиҠӮ
- еёғеұҖAIиҚҜзү©з ”еҸ‘пјҒеҚҺдёәжӢӣиҒҳиҚҜзү©з ”еҸ‘з®—жі•е·ҘзЁӢеёҲпјҢж—©жңүеҮҶеӨҮиҝӣеҶӣеҢ»з–—иЎҢдёҡпјҹ
- иӢ№жһңжӢҚз…§жҲҗеғҸеҘҪзҡ„з§ҳеҜҶпјҢжәҗдәҺжӣҙдјҳзҡ„иҪҜ件算法