жҺЁиҚҗйғЁзҪІе“Ёе…өиҠӮзӮ№еўһеҠ еҸҜз”ЁжҖ§ пјҢ иҠӮзӮ№ж•°йҮҸиҮіе°‘3дёӘ пјҢ 并еҲҶеёғеңЁдёҚеҗҢжңәеҷЁдёҠ пјҢ е®һзҺ°ж•…йҡңиҮӘеҠЁж•…йҡңиҪ¬з§»жҸҗеүҚеҒҡеҘҪе®№йҮҸ规еҲ’ пјҢ дёҖеҸ°жңәеҷЁйғЁзҪІе®һдҫӢзҡ„еҶ…еӯҳдёҠйҷҗ пјҢ жңҖеҘҪжҳҜжңәеҷЁеҶ…еӯҳзҡ„дёҖеҚҠ пјҢ дё»д»Һе…ЁйҮҸеҗҢжӯҘж—¶дјҡеҚ з”ЁжңҖеӨҡйўқеӨ–дёҖеҖҚзҡ„еҶ…еӯҳз©әй—ҙ пјҢ йҳІжӯўзҪ‘з»ңеӨ§йқўз§Ҝж•…йҡңеј•еҸ‘жүҖжңүmaster-slaveзҡ„е…ЁйҮҸеҗҢжӯҘеҜјиҮҙжңәеҷЁеҶ…еӯҳиў«еҗғе…үеҒҡеҘҪжңәеҷЁзҡ„CPUгҖҒеҶ…еӯҳгҖҒеёҰе®ҪгҖҒзЈҒзӣҳзӣ‘жҺ§ пјҢ еңЁиө„жәҗдёҚи¶іж—¶еҸҠж—¶жҠҘиӯҰеӨ„зҗҶ пјҢ RedisдҪҝз”ЁSwapеҗҺжҖ§иғҪжҖҘеү§дёӢйҷҚ пјҢ зҪ‘з»ңеёҰе®ҪиҙҹиҪҪиҝҮй«ҳи®ҝ问延иҝҹжҳҺжҳҫеўһеӨ§ пјҢ зЈҒзӣҳIOиҝҮй«ҳж—¶ејҖеҗҜAOFдјҡжӢ–ж…ўRedisзҡ„жҖ§иғҪи®ҫзҪ®жңҖеӨ§иҝһжҺҘж•°дёҠйҷҗ пјҢ йҳІжӯўиҝҮеӨҡзҡ„е®ўжҲ·з«ҜиҝһжҺҘеҜјиҮҙжңҚеҠЎиҙҹиҪҪиҝҮй«ҳеҚ•дёӘе®һдҫӢзҡ„дҪҝз”ЁеҶ…еӯҳе»әи®®жҺ§еҲ¶еңЁ20Gд»ҘдёӢ пјҢ иҝҮеӨ§зҡ„е®һдҫӢдјҡеҜјиҮҙеӨҮд»Ҫж—¶й—ҙд№…гҖҒиө„жәҗж¶ҲиҖ—еӨҡ пјҢ дё»д»Һе…ЁйҮҸеҗҢжӯҘж•°жҚ®ж—¶й—ҙйҳ»еЎһж—¶й—ҙжӣҙй•ҝи®ҫзҪ®еҗҲзҗҶзҡ„ slowlog йҳҲеҖј пјҢ жҺЁиҚҗ10жҜ«з§’ пјҢ 并еҜ№е…¶иҝӣиЎҢзӣ‘жҺ§ пјҢ дә§з”ҹиҝҮеӨҡзҡ„ж…ўж—Ҙеҝ—йңҖиҰҒеҸҠж—¶жҠҘиӯҰи®ҫзҪ®еҗҲзҗҶзҡ„еӨҚеҲ¶зј“еҶІеҢә repl-backlog еӨ§е°Ҹ пјҢ йҖӮеҪ“и°ғеӨ§ repl-backlog еҸҜд»ҘйҷҚдҪҺдё»д»Һе…ЁйҮҸеӨҚеҲ¶зҡ„жҰӮзҺҮи®ҫзҪ®еҗҲзҗҶзҡ„slaveиҠӮзӮ№ client-output-buffer-limit еӨ§е°Ҹ пјҢ еҜ№дәҺеҶҷе…ҘйҮҸеҫҲеӨ§зҡ„е®һдҫӢ пјҢ йҖӮеҪ“и°ғеӨ§еҸҜд»ҘйҒҝе…Қдё»д»ҺеӨҚеҲ¶дёӯж–ӯй—®йўҳеӨҮд»Ҫж—¶жҺЁиҚҗеңЁslaveиҠӮзӮ№дёҠеҒҡ пјҢ дёҚеҪұе“ҚmasterжҖ§иғҪдёҚејҖеҗҜAOFжҲ–ејҖеҗҜAOFй…ҚзҪ®дёәжҜҸз§’еҲ·зӣҳ пјҢ йҒҝе…ҚзЈҒзӣҳIOж¶ҲиҖ—йҷҚдҪҺRedisжҖ§иғҪеҪ“е®һдҫӢи®ҫзҪ®дәҶеҶ…еӯҳдёҠйҷҗ пјҢ йңҖиҰҒи°ғеӨ§еҶ…еӯҳдёҠйҷҗж—¶ пјҢ е…Ҳи°ғж•ҙslaveеҶҚи°ғж•ҙmaster пјҢ еҗҰеҲҷдјҡеҜјиҮҙдё»д»ҺиҠӮзӮ№ж•°жҚ®дёҚдёҖиҮҙеҜ№RedisеўһеҠ зӣ‘жҺ§ пјҢ зӣ‘жҺ§йҮҮйӣҶ info дҝЎжҒҜж—¶ пјҢ дҪҝз”Ёй•ҝиҝһжҺҘ пјҢ йў‘з№Ғзҡ„зҹӯиҝһжҺҘд№ҹдјҡеҪұе“ҚRedisжҖ§иғҪзәҝдёҠжү«жҸҸж•ҙдёӘе®һдҫӢж•°ж—¶ пјҢ и®°еҫ—и®ҫзҪ®дј‘зң ж—¶й—ҙ пјҢ йҒҝе…Қжү«жҸҸж—¶QPSзӘҒеўһеҜ№Redisдә§з”ҹжҖ§иғҪжҠ–еҠЁexpired_keys evicted_keys latest_fork_usecжҖ»з»“д»ҘдёҠе°ұжҳҜжҲ‘еңЁдҪҝз”ЁRedisе’ҢејҖеҸ‘Redisзӣёе…ідёӯй—ҙ件时 пјҢ жҖ»з»“еҮәжқҘRedisжҺЁиҚҗзҡ„е®һи·өж–№жі• пјҢ д»ҘдёҠжҸҗеҮәзҡ„иҝҷдәӣж–№йқў пјҢ йғҪжҲ–еӨҡжҲ–е°‘еңЁе®һйҷ…дҪҝз”ЁдёӯйҒҮеҲ°иҝҮ гҖӮ
еҸҜи§Ғ пјҢ иҰҒжғізЁіе®ҡеҸ‘жҢҘRedisзҡ„й«ҳжҖ§иғҪ пјҢ йңҖиҰҒеңЁеҗ„дёӘж–№йқўеҒҡеҘҪе·ҘдҪң пјҢ дҪҶеҮЎжҹҗдёҖдёӘж–№йқўеҮәзҺ°й—®йўҳ пјҢ еҝ…然дјҡеҪұе“ҚеҲ°Redisзҡ„жҖ§иғҪ пјҢ иҝҷеҜ№жҲ‘们дҪҝз”Ёе’Ңиҝҗз»ҙжҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮ гҖӮ
жң¬ж–ҮжқҘжәҗ:еҫ®дҝЎе…¬дј—еҸ·:еҢ еҝғйӣ¶еәҰ дҪңиҖ…:kaito
гҖҗдёҡеҠЎеұӮйқўе’Ңиҝҗз»ҙеұӮйқўдјҳеҢ–дҪ зҡ„RedisгҖ‘жң¬ж–Үең°еқҖ:;mid=2247492243&idx=1&sn=d58605228666c719db78f9e720f3c9eb
жҺЁиҚҗйҳ…иҜ»
-
иҖҒзҫҺ|дёҺиҖҒзҫҺеҚҒе№ҙе®ҳеҸёдәҶз»“пјҒеҢ—ж–°е»әжқҗеҮҖеҲ©жҡҙж¶ЁпјҢеҫӢеёҲиҜҰи§ЈдјҒдёҡеҮәжө·жңүе“Әдәӣеқ‘
-
жқӯе·һеҘіеӯҗеӨұиёӘжЎҲеҗҺз»ӯ|гҖҗеҗҺз»ӯжқҘдәҶгҖ‘жқӯе·һеҘіеӯҗеӨұиёӘжЎҲеҗҺз»ӯжҳҜжҖҺд№ҲеӣһдәӢ?е…·дҪ“жҳҜд»Җд№Ҳжғ…еҶөпјҹ
-
жҗһ笑ж®өеӯҗи¶Јеӣҫ|зҹ«еҒҘзҡ„иә«е§ҝпјҢиҝҷжүҚжҳҜзңҹжӯЈзҡ„еҘіжӢіеӨ§еёҲпјҢжҗһ笑gif-зңӢиҝҷзҒөжҙ»зҡ„иә«жүӢ
-
жҙӣйҳіжү“йҖ вҖң客家зҘ–жәҗең°вҖқпјҡ客家д№ӢжәҗзәӘеҝөйҰҶйў„и®ЎжҳҺе№ҙ9жңҲе»әжҲҗ
-
е…ій—ӯ|жүӢжңәеҸӘеү©20%з”өйҮҸпјҹеҲ«ж…ҢпјҒз”ЁдәҶиҝҷеҮ жӢӣпјҢеӨҡз”Ё2е°Ҹж—¶
-
гҖҗеӨ®и§Ҷж–°й—»гҖ‘зҫҺеӘ’жӣқзү№жң—жҷ®жӢҹжҸҗеҗҚзҡ„еӨ§жі•е®ҳдәәйҖү
-
е…¬и·Ҝдә’йҖҡеҢқйҒ“пјҢеҮёеҪўе’ҢеҮ№еҪўжӣІзәҝжһҒйҷҗжңҖе°ҸеҚҠеҫ„пјҢж»Ўи¶іеҒңиҪҰи§Ҷи·қиҰҒжұӮеҗ—
-
5Gе°Ҹеҹәз«ҷйғЁзҪІеӨ„еңЁеҲқзә§йҳ¶ж®өпјҢд»Ҡе№ҙжҳҜй“әеһ«е№ҙ
-
еӣһеӣҪжүҫе·ҘдҪңпјҢе’Ңз•ҷеңЁж—Ҙжң¬е·ҘдҪңпјҢеҲ°еә•е’ӢеҸ–иҲҚгҖӮ
-
ж–ҮжўҰжҙӢ|и°Ғиҝҳи®°еҫ—гҖҠдё‘еҘіж— ж•ҢгҖӢзҡ„е°Ҹиүҫпјҹи·ҹй”ҷеҜјжј”жҲҗзҪ‘зәўпјҢжІҰдёәеҚҒе…«зәҝеҪўиұЎеӨ§еҸҳ
-
зҗізҗіиҜҙеҺҶеҸІ|йғӯеҳүжҺ’еҖ’数第дёҖпјҢеҸёй©¬жҮҝз”ҡиҮіжІЎдёҠжҰңпјҒпјҢдёүеӣҪж—¶жңҹжӣ№ж“Қзҡ„дә”еӨ§и°ӢеЈ«
-
з”ҹжҙ»иҰҒй…·|еӨ§еҶ…еӯҳ+йә’йәҹеӨ„зҗҶеҷЁпјҢиҝҷжүҚжҳҜиҚЈиҖҖзңҹйҰҷеҚғе…ғжңәпјҒпјҢдёҚеҲ°1400е…ғ
-
-
еҰӮжһңжІЎиҜ»й«ҳдёӯ е’Ӣж ·жүҚиғҪиҝӣйҹід№җеӯҰйҷўиҜ»д№Ұе‘Җжң¬дәәеҫҲзғӯзҲұйҹід№җдҪҶжҳҜ家еәӯжқЎд»¶е·® зҲ¶жҜҚжІЎжңүи®©жҲ‘иҜ»й«ҳдёӯ
-
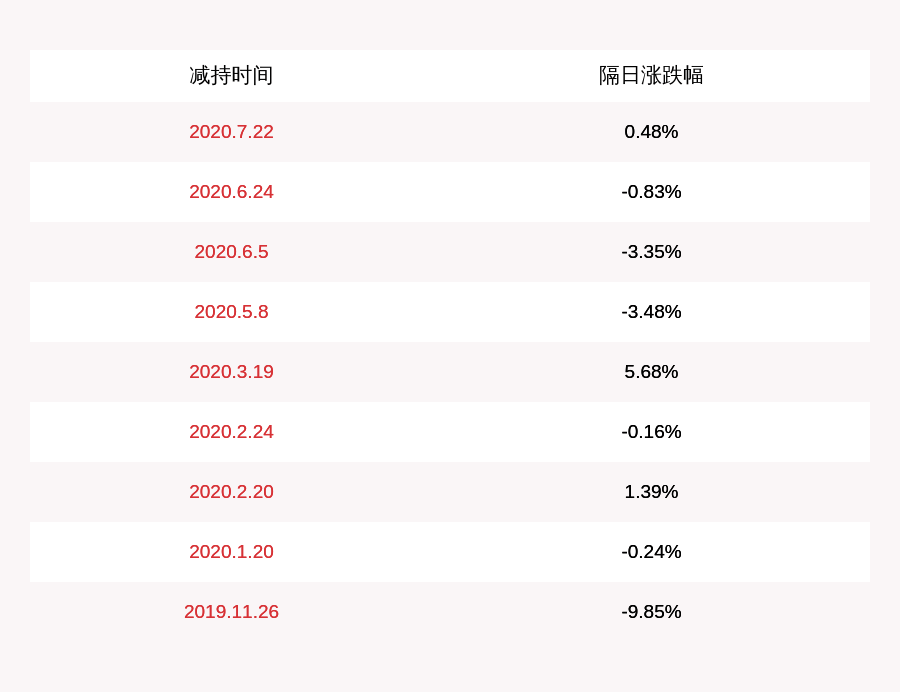
и®ЎеҲ’|еҒҘеёҶз”ҹзү©пјҡи‘ЈдәӢе…јеүҜжҖ»з»ҸзҗҶе”җе…Ҳж•ҸеҮҸжҢҒзәҰ168дёҮиӮЎпјҢеҮҸжҢҒи®ЎеҲ’ж—¶й—ҙе·ІиҝҮеҚҠ
-
е‘Ёдј йӣ„и°Ҳе•Ҷжј”иҜҙиө°з©ҙеӨӘйҡҫеҗ¬пјҢжҲ‘дјҡжҲҗдёәдјҹеӨ§иүәжңҜ家пјҢд»Ҡиў«зҪ‘зәўзӮ№иҜ„
-
еҫ·жү‘flopжҳҜд»Җд№Ҳж„ҸжҖқ flopжҳҜд»Җд№Ҳж„ҸжҖқ
-
гҖҢеҸӮиҖғж¶ҲжҒҜгҖҚйҹ©еӘ’пјҡзҫҺеҜ№йҹ©жңҖеӨ§йҷҗеәҰж–ҪеҺӢ еҸӘдёәи®©ж—Ҙйҹ©з»§з»ӯвҖңеңЁдёҖиө·
-
еҸӨж—¶еҖҷзҡ„е…ғе®өиҠӮжҳҜжғ…дәәиҠӮеҗ— еҸӨж—¶еҖҷзҡ„е…ғе®өиҠӮеҸҲиў«з§°дёә
-
еҸҜеҸЈеҸҜд№җ|еҸҜеҸЈеҸҜд№җж——дёӢ йӯ”зҲӘйҫҚиҢ¶иғҪйҮҸйҘ®ж–ҷжё…д»“пјҡ3.3е…ғ/зҪҗ