|йҖҹеәҰи¶…еҝ«пјҒеӯ—иҠӮи·іеҠЁејҖжәҗеәҸеҲ—жҺЁзҗҶеј•ж“ҺLightSeq
жңәеҷЁд№ӢеҝғеҸ‘еёғ
жңәеҷЁд№Ӣеҝғзј–иҫ‘йғЁ
иҝҷеә”иҜҘжҳҜдёҡз•Ң第дёҖж¬ҫе®Ңж•ҙж”ҜжҢҒ TransformerгҖҒGPT зӯүеӨҡз§ҚжЁЎеһӢй«ҳйҖҹжҺЁзҗҶзҡ„ејҖжәҗеј•ж“Һ гҖӮ
2017 е№ҙ Google жҸҗеҮәдәҶ Transformer [1] жЁЎеһӢ пјҢ д№ӢеҗҺеңЁе®ғеҹәзЎҖдёҠиҜһз”ҹдәҶи®ёеӨҡдјҳз§Җзҡ„йў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢе’ҢжңәеҷЁзҝ»иҜ‘жЁЎеһӢ пјҢ еҰӮ BERT [2] гҖҒGPT зі»еҲ—[13]зӯү пјҢ дёҚж–ӯеҲ·ж–°зқҖдј—еӨҡиҮӘ然иҜӯиЁҖеӨ„зҗҶд»»еҠЎзҡ„иғҪеҠӣж°ҙе№і гҖӮ дёҺжӯӨеҗҢж—¶ пјҢ иҝҷдәӣжЁЎеһӢзҡ„еҸӮж•°йҮҸд№ҹеңЁе‘ҲзҺ°иҝ‘д№ҺжҢҮж•°еўһй•ҝпјҲеҰӮдёӢеӣҫжүҖзӨәпјү гҖӮ дҫӢеҰӮжңҖиҝ‘еј•еҸ‘зғӯзғҲи®Ёи®әзҡ„ GPT-3 [3] пјҢ жӢҘжңү 1750 дәҝеҸӮж•° пјҢ еҶҚж¬ЎеҲ·ж–°дәҶеҸӮж•°йҮҸзҡ„и®°еҪ• гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еҰӮжӯӨе·ЁеӨ§зҡ„еҸӮж•°йҮҸ пјҢ д№ҹдёәжЁЎеһӢжҺЁзҗҶйғЁзҪІеёҰжқҘдәҶжҢ‘жҲҳ гҖӮ д»ҘжңәеҷЁзҝ»иҜ‘дёәдҫӢ пјҢ зӣ®еүҚ WMT[4]жҜ”иөӣдёӯ SOTA жЁЎеһӢе·Із»ҸиҫҫеҲ°дәҶ 50 еұӮд»ҘдёҠ гҖӮ дё»жөҒж·ұеәҰеӯҰд№ жЎҶжһ¶дёӢ пјҢ зҝ»иҜ‘дёҖеҸҘиҜқйңҖиҰҒеҘҪеҮ з§’ гҖӮ иҝҷеёҰжқҘдәҶдёӨдёӘй—®йўҳпјҡдёҖжҳҜзҝ»иҜ‘ж—¶й—ҙеӨӘй•ҝ пјҢ еҪұе“Қдә§е“Ғз”ЁжҲ·дҪ“йӘҢпјӣдәҢжҳҜеҚ•еҚЎ QPS пјҲжҜҸз§’жҹҘиҜўзҺҮпјүеӨӘдҪҺ пјҢ еҜјиҮҙжңҚеҠЎжҲҗжң¬иҝҮй«ҳ гҖӮ
еӣ жӯӨ пјҢ д»ҠеӨ©з»ҷеӨ§е®¶е®үеҲ©дёҖж¬ҫйҖҹеәҰйқһеёёеҝ« пјҢ еҗҢж—¶ж”ҜжҢҒйқһеёёеӨҡзү№жҖ§зҡ„й«ҳжҖ§иғҪеәҸеҲ—жҺЁзҗҶеј•ж“ҺвҖ”вҖ”LightSeq гҖӮ е®ғеҜ№д»Ҙ Transformer дёәеҹәзЎҖзҡ„еәҸеҲ—зү№еҫҒжҸҗеҸ–еҷЁпјҲEncoderпјүе’ҢиҮӘеӣһеҪ’зҡ„еәҸеҲ—и§Јз ҒеҷЁпјҲDecoderпјүеҒҡдәҶж·ұеәҰдјҳеҢ– пјҢ ж—©еңЁ 2019 е№ҙ 12 жңҲе°ұе·Із»ҸејҖжәҗ пјҢ еә”з”ЁеңЁдәҶеҢ…жӢ¬зҒ«еұұзҝ»иҜ‘зӯүдј—еӨҡдёҡеҠЎе’ҢеңәжҷҜ гҖӮ жҚ®дәҶи§Ј пјҢ иҝҷеә”иҜҘжҳҜдёҡз•Ң第дёҖж¬ҫе®Ңж•ҙж”ҜжҢҒ TransformerгҖҒGPT зӯүеӨҡз§ҚжЁЎеһӢй«ҳйҖҹжҺЁзҗҶзҡ„ејҖжәҗеј•ж“Һ гҖӮ
LightSeq еҸҜд»Ҙеә”з”ЁдәҺжңәеҷЁзҝ»иҜ‘гҖҒиҮӘеҠЁй—®зӯ”гҖҒжҷәиғҪеҶҷдҪңгҖҒеҜ№иҜқеӣһеӨҚз”ҹжҲҗзӯүдј—еӨҡж–Үжң¬з”ҹжҲҗеңәжҷҜ пјҢ еӨ§еӨ§жҸҗй«ҳзәҝдёҠжЁЎеһӢжҺЁзҗҶйҖҹеәҰ пјҢ ж”№е–„з”ЁжҲ·зҡ„дҪҝз”ЁдҪ“йӘҢ пјҢ йҷҚдҪҺдјҒдёҡзҡ„иҝҗиҗҘжңҚеҠЎжҲҗжң¬ гҖӮ
зӣёжҜ”дәҺзӣ®еүҚе…¶д»–ејҖжәҗеәҸеҲ—жҺЁзҗҶеј•ж“Һ пјҢ LightSeqе…·жңүеҰӮдёӢеҮ зӮ№дјҳеҠҝпјҡ
1. й«ҳжҖ§иғҪ
LightSeqжҺЁзҗҶйҖҹеәҰйқһеёёеҝ« гҖӮ дҫӢеҰӮеңЁзҝ»иҜ‘д»»еҠЎдёҠ пјҢ LightSeqзӣёжҜ”дәҺTensorflowе®һзҺ°жңҖеӨҡеҸҜд»ҘиҫҫеҲ°14еҖҚзҡ„еҠ йҖҹ гҖӮ еҗҢж—¶йўҶе…Ҳзӣ®еүҚе…¶д»–ејҖжәҗеәҸеҲ—жҺЁзҗҶеј•ж“Һ пјҢ дҫӢеҰӮжңҖеӨҡеҸҜжҜ”Faster Transformerеҝ«1.4еҖҚ гҖӮ
2. ж”ҜжҢҒжЁЎеһӢеҠҹиғҪеӨҡ
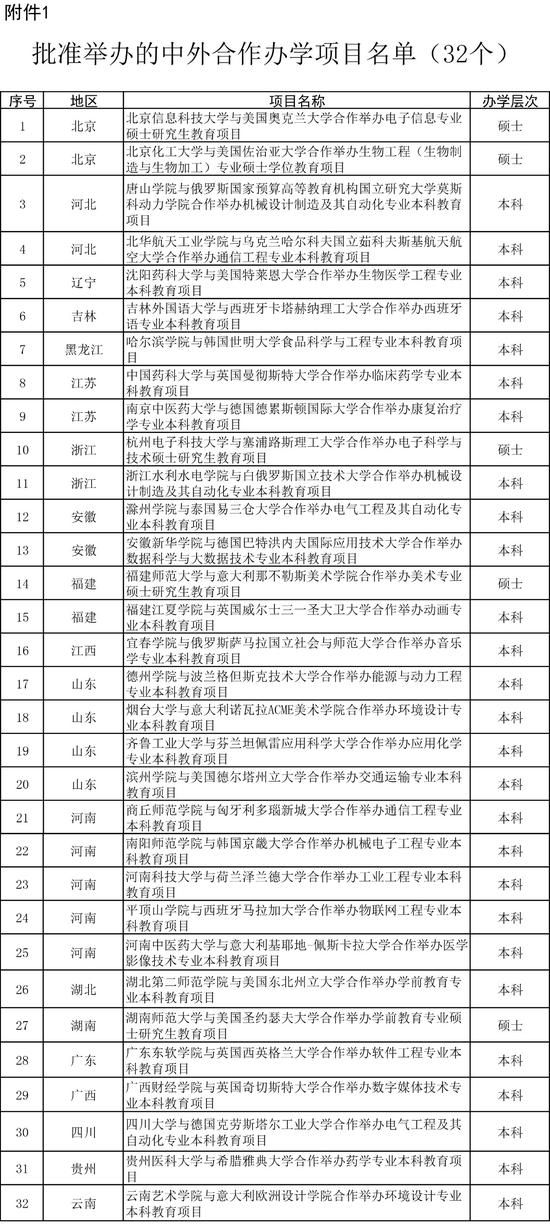
LightSeqж”ҜжҢҒBERTгҖҒGPTгҖҒTransformerгҖҒVAE зӯүдј—еӨҡжЁЎеһӢ пјҢ еҗҢж—¶ж”ҜжҢҒbeam searchгҖҒdiverse beam search[5]гҖҒsamplingзӯүеӨҡз§Қи§Јз Ғж–№ејҸ гҖӮ дёӢиЎЁиҜҰз»ҶеҲ—дёҫдәҶFaster Transformer[7]гҖҒTurbo Transformers[6]е’ҢLightSeqдёүз§ҚжҺЁзҗҶеј•ж“ҺеңЁж–Үжң¬з”ҹжҲҗеңәжҷҜзҡ„еҠҹиғҪе·®ејӮпјҡ
жң¬ж–ҮжҸ’еӣҫ
3. з®ҖеҚ•жҳ“з”Ё пјҢ ж— зјқиЎ”жҺҘTensorflowгҖҒPyTorchзӯүж·ұеәҰеӯҰд№ жЎҶжһ¶
LightSeqйҖҡиҝҮе®ҡд№үжЁЎеһӢеҚҸи®® пјҢ ж”ҜжҢҒеҗ„з§Қж·ұеәҰеӯҰд№ жЎҶжһ¶и®ӯз»ғеҘҪзҡ„жЁЎеһӢзҒөжҙ»еҜје…Ҙ гҖӮ еҗҢж—¶еҢ…еҗ«дәҶејҖз®ұеҚіз”Ёзҡ„з«ҜеҲ°з«ҜжЁЎеһӢжңҚеҠЎ пјҢ еҚіеңЁдёҚйңҖиҰҒеҶҷдёҖиЎҢд»Јз Ғзҡ„жғ…еҶөдёӢйғЁзҪІй«ҳйҖҹжЁЎеһӢжҺЁзҗҶ пјҢ еҗҢж—¶д№ҹзҒөжҙ»ж”ҜжҢҒеӨҡеұӮж¬ЎеӨҚз”Ё гҖӮ
дҪҝз”Ёж–№жі•
еҲ©з”Ё LightSeq йғЁзҪІзәҝдёҠжңҚеҠЎжҜ”иҫғз®Җдҫҝ гҖӮ LightSeq ж”ҜжҢҒдәҶ Triton Inference Server[8] пјҢ иҝҷжҳҜ Nvidia ејҖжәҗзҡ„дёҖж¬ҫ GPU жҺЁзҗҶ serverпјҢ еҢ…еҗ«дј—еӨҡе®һз”Ёзҡ„жңҚеҠЎдёӯй—ҙ件 гҖӮ LightSeq ж”ҜжҢҒдәҶиҜҘ server зҡ„иҮӘе®ҡд№үжҺЁзҗҶеј•ж“Һ APIгҖӮ еӣ жӯӨеҸӘиҰҒе°Ҷи®ӯз»ғеҘҪзҡ„жЁЎеһӢеҜјеҮәеҲ° LightSeq е®ҡд№үзҡ„жЁЎеһӢеҚҸи®®[9]дёӯ пјҢ е°ұеҸҜд»ҘеңЁдёҚеҶҷд»Јз Ғзҡ„жғ…еҶөдёӢ пјҢ дёҖй”®еҗҜеҠЁз«ҜеҲ°з«Ҝзҡ„й«ҳж•ҲжЁЎеһӢжңҚеҠЎ гҖӮ жӣҙж”№жЁЎеһӢй…ҚзҪ®пјҲдҫӢеҰӮеұӮж•°е’Ң embedding еӨ§е°ҸпјүйғҪеҸҜд»Ҙж–№дҫҝж”ҜжҢҒ гҖӮ е…·дҪ“иҝҮзЁӢеҰӮдёӢпјҡ
йҰ–е…ҲеҮҶеӨҮеҘҪжЁЎеһӢд»“еә“ пјҢ дёӢйқўжҳҜзӣ®еҪ•з»“жһ„зӨәдҫӢ пјҢ е…¶дёӯ transformer.pb жҳҜжҢүжЁЎеһӢеҚҸи®®еҜјеҮәзҡ„жЁЎеһӢжқғйҮҚ пјҢ libtransformer.so жҳҜ LightSeq зҡ„зј–иҜ‘дә§зү© гҖӮ
- model_zoo/- model_repo/- config.pbtxt- transformer.pb- 1/- libtransformer.so
然еҗҺе°ұеҸҜд»ҘеҗҜеҠЁTriton Inference Server[8] пјҢ жҗӯе»әиө·жЁЎеһӢжңҚеҠЎ гҖӮ
1. trtserver --model-store=${model_zoo}
жҖ§иғҪжөӢиҜ•
еңЁ NVIDIA Tesla P4 е’Ң NVIDIA Tesla T4 жҳҫеҚЎдёҠ пјҢ 笔иҖ…жөӢиҜ•дәҶ LightSeq зҡ„жҖ§иғҪ пјҢ йҖүжӢ©дәҶж·ұеәҰеӯҰд№ жЎҶжһ¶ Tensorflow v1.13 е’Ңи§Јз ҒеңәжҷҜж”ҜжҢҒиҫғдёәдё°еҜҢзҡ„ Faster Transformer v2.1 е®һзҺ°дҪңдёәеҜ№жҜ” гҖӮ Turbo Transformers и§Јз Ғж–№жі•жҜ”иҫғеҚ•дёҖпјҲеҸӘж”ҜжҢҒ Beam SearchпјҢ дёҚж”ҜжҢҒж–Үжң¬з”ҹжҲҗдёӯеёёз”Ёзҡ„йҮҮж ·и§Јз Ғпјү пјҢ е°ҡжңӘж»Ўи¶іе®һйҷ…еә”з”ЁйңҖжұӮ пјҢ еӣ жӯӨжңӘдҪңеҜ№жҜ” гҖӮ


жҺЁиҚҗйҳ…иҜ»

![[зҷҪеҝ—еі°]зқЎи§үе§ҝеҠҝжңүеӨ§еӯҰй—®](/renwen/images/defaultpic.gif)











- з ҚжҹҙзҪ‘|иӢ№жһң M1 жІЎжғіиұЎеҝ«пјҢеҗҜеҠЁ Office иҰҒеӨҡиҠұ 20 з§’ иӢ№жһңжүҝи®ӨпјҡйҖҹеәҰдјҡжңүзӮ№ж…ў
- йӣ·еёқи§ҰзҪ‘|еӯ—иҠӮи·іеҠЁд»Ҡе№ҙе№ҝе‘ҠжөҒж°ҙ收е…ҘжҲ–и¶…1700дәҝ жҠ–йҹіиҙЎзҢ®еӨ§
- еҚҺдёә|дёӢиҪҪйҖҹеәҰжҜҸз§’1TBпјҢиӢ№жһңгҖҒй«ҳйҖҡзӯүиҒ”жүӢйў„з ”6GпјҡеҚҺдёәж—©е·ІејҖе§Ӣ
- и¶ЈжҠ•зЁҝ|OPPO 125Wи¶…еҝ«е……з”өеҷЁжҲ–е°ҶдәҺжҳҺе№ҙ第дёҖеӯЈеәҰжҺЁеҮә
- 科жҠҖ|жҺҢйҳ…иҺ·еӯ—иҠӮи·іеҠЁ11дәҝе…ғе…ҘиӮЎпјҡе°ҡжңӘж·ұеҢ–еҗҲдҪңпјҢе»әз«Ӣе“ҒзүҢзҹ©йҳөиҝҳйңҖж—¶ж—Ҙ
- ж•ҷиӮІ|е°ҸеҸ°зҒҜеҲҮе…ҘеӨ§ж•ҷиӮІ еӯ—иҠӮи·іеҠЁе…ЁйқўеёғеұҖж•ҷиӮІйўҶеҹҹ
- жҷҡзӮ№LatePost|жҷҡзӮ№зӢ¬е®¶пҪңеӯ—иҠӮе°Ҷз”өе•ҶеҲ—дёәжҳҺе№ҙеӨҙеҸ·еӯөеҢ–йЎ№зӣ®пјҢе°ҶиҝӣдёҖжӯҘж•ҙеҗҲ
- 科жҠҖеҜҶжҺўйў‘йҒ“|е“ҲиҖ¶е…Ӣз»ҷеј дёҖйёЈиҝҷзӮ№еҗҜеҸ‘пјҢжҳҜеӯ—иҠӮиө°еҗ‘规模еҢ–зҡ„еҹәзЎҖд№ӢдёҖ
- |дҝқйҡңвҖңеҸҢеҚҒдёҖвҖқжө·е…іжңүйҖҹеәҰ
- ж–°зі»з»ҹ|macOS Big SurжӯЈејҸзүҲ11жңҲ12ж—ҘжҺЁйҖҒ е“Қеә”йҖҹеәҰеҝ«1.9еҖҚ