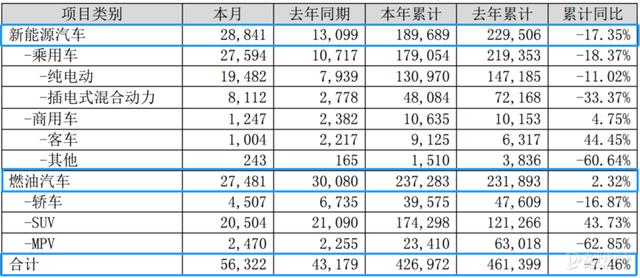
|把因果干预用到弱监督语义分割上!这篇NeurIPS 2020 oral论文不简单( 三 )
在已知X和C的情况下 , M则可以被表示为C的一种线性组合 。 如图5所示 , 包含类别信息“car” , “person” , 和“bicycle”的图像X可以被表示为0.12“bird” + 0.13“bottle” + ... + 0.29“person” , 其中“bird” , ''person''和“bottle”均为数据集中提供的目标类别 。
本文插图
图 5. CONTA中每个component的可视化
5 实施步骤
以上分析的干预后的因果图 , 其本质上是一个包含了mask信息的多标签分类模型 。 那我们如何把这个分类模型再次用到弱监督的分割任务中?
由于mask在当前步骤中已经被使用了 , 所以很容易想到的就是把模型设计为一种循环的模式 。
如图6 , 首先 , 通过初始化弱监督语义分割模型获取图像的mask信息;
然后 , 构建Confounder set并去除confounder 。 该步骤参考了我们组之前的几个工作[3,4];
最后将去除confounder后的mask拼接到下一轮的分类模型的backbone中以产生更高质量的CAM 。
产生的CAM又可以用来产生更高质量的mask , 以此形成一个良性循环(其收敛性可以由EM算法保证) 。
本文插图
图 6. 本文提出的CONTA模型
6 实验结果
我们在PASCAL VOC 2012和COCO数据集上都进行了实验 , 在以SEAM [5]和IRNet [6]为baseline的基础上 , 我们的模型在PASCAL VOC 2012和COCO均取得了当前最好的效果 。
本文插图
【|把因果干预用到弱监督语义分割上!这篇NeurIPS 2020 oral论文不简单】除了在两个SOTA模型上进行实验之外 , 我们还在SEC和DSRG模型上进行了实验 , 并report了在training set上的CAM和pseudo-mask的量化结果 。 实验结果均验证了CONTA的有效性 。
本文插图
最后 , 提供一些分割的可视化结果 。
可以看到在CONTA的帮助下 , 原本一些错误分割的目标可以被准确的分割 , 比如“狗” 。
一些较小和较细的目标的mask也得到了改善 , 比如“牛腿”和远处的“人”等等 。
除此之外 , 我们还可视化两个失败的例子:自行车和植物 。
造成这种目标分割失败的原因是由于目标本身太细了 , 而我们的分割模型最后的特征图是8倍下采样的 , 因此这类目标不能被很好的分割 。
这些问题可以通过使用一些更细粒度的特征得到解决 。
本文插图
7 总结
以往的弱监督语义分割模型往往都是一锤子买卖 , 使用pseudo-mask训练好了语义分割模型后就结束了 , 下游的模型并没有用来反哺上游的模型 , 但是下游的模型本身却往往包含着自己想要的重要信息 。
CONTA或许可以给大家提供这样一种思路 , 不仅仅适用于弱监督的语义分割模型中 , 怎么样可以使得这种类似的“multi-stage”任务活起来 , 使用一些自带的信息进行补充后 , 再用到下一轮的循环中解决存在的问题 。
本文经作者授权转载自知乎:
https://zhuanlan.zhihu.com/p/260967655
参考链接:





- [1] https://zhuanlan.zhihu.com/p/111306353
- [2] https://zhuanlan.zhihu.com/p/259569655
- [3] Xu Yang, Hanwang Zhang, and Jianfei Cai. Deconfounded image captioning: A causal retrospect. In arXiv, 2020.
推荐阅读
- 行业互联网|大数据应用到底是做什么的?
- 明朝|历朝各代之中,谈谈明朝的妃嫔出身低微的其中因果
- 制度|证监会:全面、辩证把握“建制度、不干预、零容忍”之间的有机联系
- Arm|宣布被英伟达收购后 Arm联合创始人要求英国政府干预或取消交易
- 华为|华为消费者业务软件部总裁王成录:鸿蒙系统将应用到平板等产品
- 行业互联网|倪光南院士:我国信创进入到“可用到好用”阶段
- 制度|证监会副主席阎庆民:“建制度、不干预、零容忍”的核心是依法治市