iTunes|算法之“算法”:所有机器学习算法都可以表示为神经网络
文章图片
文章图片
文章图片

文章图片

文章图片
全文共2660字 , 预计学习时长7分钟
【iTunes|算法之“算法”:所有机器学习算法都可以表示为神经网络】图源:unsplash
大概从20世纪50年代的早期研究开始 , 机器学习的所有工作就都是随着神经网络的创建积累而来的 。 随后出现了一个又一个新算法 , 从逻辑回归到支持向量机 。 但是众所周知 , 神经网络是算法的算法及机器学习的巅峰 。 我们可以说 , 神经网络是对机器学习的普遍概括 , 而不是仅仅一次尝试 。与其说神经网络是简单的算法 , 不如说是框架和概念 , 这是显而易见的 , 因为在构建神经网络时有很大的自由度——比如对于隐藏层&节点个数、激活函数、优化器、损失函数、网络类型(卷积神经网络、循环神经网络等)以及特殊层(批归一化、随机失活等) 。
如果把神经网络看作是概念而非严格的算法 , 一个有趣的推论就应运而生了:任何机器学习算法 , 无论是决策树还是k近邻 , 都可以用神经网络表示 。 直觉上 , 我们可以通过几个例子理解 , 更严谨地讲 , 这种说法也可以通过数学方法证明 。
我们先来定义一下什么是神经网络:它是一个体系结构 , 包括输入层、隐藏层和输出层 , 各层的节点之间互相连接 。 信息通过线性变换(权重和偏置)和非线性变换(激活函数)从输入层转换到输出层 , 有一些方法可以更新模型的可训练参数 。
逻辑回归可以简单定义为一个标准回归 , 每个输入的乘法系数和附加截距都要通过一个sigmoid函数 , 这可以通过不包括隐藏层的神经网络来建模 , 结果是通过sigmoid输出神经元的多元回归;线性回归也可以通过将输出神经元激活函数替换为线性激活函数来建模(线性激活函数只是映射输出f(x)= x , 换句话说 , 它什么也不做) 。
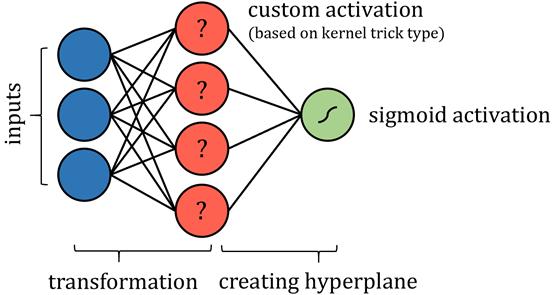
支持向量机(SVM)算法试图通过所谓的“核技巧”将数据投影到一个新的空间 , 从而优化数据的线性可分性 。 数据转换完成后 , 该算法绘制出沿组界最佳分离数据的超平面 。 超平面简单定义为现有维度的线性结合 , 很像是二维的直线和三维的平面 。
这样说来 , 可以将SVM算法看成是将数据投影到一个新的空间 , 随后进行多元回归 。 神经网络的输出可以通过某种有界输出函数来实现概率结果 。
可能需要进行一些限制 , 比如限制节点间的连接 , 并固定某些参数 , 当然这些变化不会影响“神经网络”标签的完整性 , 也许还需要添加更多层来确保支持向量机的表现与实际情况一样 。
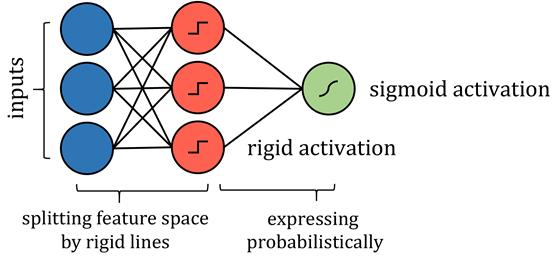
基于树的算法会更加复杂一些 , 如决策树算法 。 至于如何构建此类神经网络 , 在于它如何划分自己的特征空间 。 当一个训练点穿过一系列分割节点时 , 特征空间被分割成几个超立方体;在二维空间示例中 , 垂直线和水平线构成了正方形 。
图源:DataCamp社区
因此 , 沿着这些线分割特征空间的类似方式可以用更严格的激活函数来模拟 , 如阶跃函数 , 其中输入值本质上是分割线 。 可能需要限制权重和偏置的值 , 因此它们仅用于通过拉伸、收缩和定位来确定分界线的方向 。 为了得到概率结果 , 其结果可以通过激活函数传递 。
尽管在技术上神经网络对算法的表示和实际算法有很多差异 , 但是重点在于神经网络表达了相同的思想 , 并且可以运用相同的策略处理问题 , 其表现与实际算法也是一样的 。
然而一些人或许并不满足于粗略地将算法转换为神经网络的形式 , 或者希望看到对于更复杂算法的通用应用 , 如k近邻和朴素贝叶斯 , 而不是具体情况具体分析 。
通用逼近定理(UniversalApproximation Theorem)可以解决这个问题 , 它是神经网络巨大成功背后的数学解释 , 从本质上表明一个足够大的神经网络可以以任意精度模拟任何函数 。 假设有一个代表数据的函数f(x) , 对于每个数据点(x y) , f(x)总是返回一个等于或非常接近y的值 。
建模的目的是找到这个有代表性的或标注正确的函数f(x) , 并用p(x)来表示预测 。 所有机器学习算法都以不同的方法处理这个任务 , 将不同的假设视为有效 , 并且给出最佳结果p(x) 。 如果写出创建p(x)的算法 , 你可能会得到从条件列表到纯数学运算之间的任何结果 。 描述函数如何将目标映射到输入的函数实际上可以采用任何形式 。
这些函数有时有用 , 有时没用——它们有固定数量的参数 , 是否使用它们是一个需要思考的问题 。 然而 , 不同的神经网络在寻找f(x)的方法上有点不同 。 任何函数都可以用许多类似阶梯的部分进行合理的逼近 , 阶梯越多 , 逼近就越准确 。
每层阶梯都用一个神经网络来表示 , 它们是隐藏层中具有sigmoid激活函数的节点 , sigmoid激活函数本质上是概率阶跃函数 。 本质上 , 每个节点都被“分配”给f(x)的一部分 。
然后通过权重和偏置系统 , 网络可以决定节点的存在 , 使sigmoid函数的输入值达到正无穷(输出值为1) , 如果对于特定的输入值需要激活神经元 , 则输出值为负无穷 。 这种使用节点寻找数据函数特定部分的模式不仅可以在数字数据中观察到 , 在图像中也可以 。
虽然通用逼近定理已经扩大范围到适用于其他激活函数 , 如ReLU和神经网络类型 , 但是其原理依然是正确的:神经网络是完美的 。
神经网络不再依赖复杂的数学方程和关系系统 , 而是将自身的一部分委派给数据函数的一部分 , 并机械记忆其指定区域内的归纳 。 当这些节点聚合成一个巨大的神经网络时 , 结果看似是智能模型 , 实际上是设计巧妙的逼近器 。
如果神经网络可以构建——至少在理论上——一个精度符合你预期的函数(节点越多 , 逼近就越精确 , 当然不考虑过拟合的技术性) , 一个结构正确的神经网络可以模拟其他任何算法的预测函数p(x) 。 对于其他任何机器学习算法来说 , 这是不可能的 。
图源:unsplash
神经网络运用的方法不是优化现有模型中的一些参数 , 如多项式曲线和节点系统 , 而是对数据建模的一种特定视角 , 它不寻求充分利用任何独立系统 , 而是直接逼近数据函数;我们如此熟悉的神经网络架构仅仅是将思想进行建模展现 。
有了神经网络的力量和对于深度学习这一无底洞领域的持续研究 , 数据——无论是视频、声音、流行病学数据 , 还是任何介于两者之间的数据——将能够以前所未有的程度建模 , 神经网络确实是算法的算法 。
留言点赞关注
我们一起分享AI学习与发展的干货
如转载 , 请后台留言 , 遵守转载规范
推荐阅读

















- 人间风物志|游雍和宫:有人说这是北京必打卡景点之一,但我并不觉得非去不可
- 科学探索|揭秘星际物种起源:多个行星孵化器组成“生命之树”
- B社喜加一!《雷神之锤3》限时领取 截止8月21日
- 典韦新星元全面曝光,看完超清高能特效之后,玩家:吃土也要入手
- EVE萌新300问之1:换白蛋要怎么操作?
- 恶魔之魂|数毛社成员表示 PS5次世代独占策略是个明智的选择
- 以家人之名|以家人之名原著小说结局是什么 以家人之名电视剧全集观看地址
- 贺子秋|以家人之名一周更新几集 以家人之名更新时间最新剧情全集观看
- 凌霄|以家人之名凌霄的结局是什么 凌霄最后会和尖尖在一起吗
- 纪录之夜!国米750万锋霸10连杀,决赛国米占优,冠军即将到来