йҖҡз”ЁзүҲAlphaGoзҷ»гҖҠNatureгҖӢпјҒжңҖејәAIжЈӢжүӢпјҢдёҚжҮӮ规еҲҷд№ҹиғҪзІҫйҖҡжёёжҲҸ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҷәдёңиҘҝпјҲе…¬дј—еҸ·пјҡzhidxcomпјү
зј–иҜ‘ | еӯҗдҪ©
зј–иҫ‘ | Panken
жҷәдёңиҘҝ12жңҲ24ж—Ҙж¶ҲжҒҜ пјҢ 继AlphaGoжү¬еҗҚжө·еӨ–еҗҺ пјҢ DeepMindеҶҚжҺЁж–°жЁЎеһӢMuZero пјҢ иҜҘжЁЎеһӢеҸҜд»ҘеңЁдёҚзҹҘйҒ“жёёжҲҸ规еҲҷзҡ„жғ…еҶөдёӢ пјҢ иҮӘеӯҰеӣҙжЈӢгҖҒеӣҪйҷ…иұЎжЈӢгҖҒж—Ҙжң¬е°ҶжЈӢе’ҢAtariжёёжҲҸ并еҲ¶е®ҡжңҖдҪіиҺ·иғңзӯ–з•Ҙ пјҢ и®әж–Үд»Ҡж—ҘеҸ‘иЎЁиҮігҖҠNatureгҖӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
и®әж–Үй“ҫжҺҘпјҡ
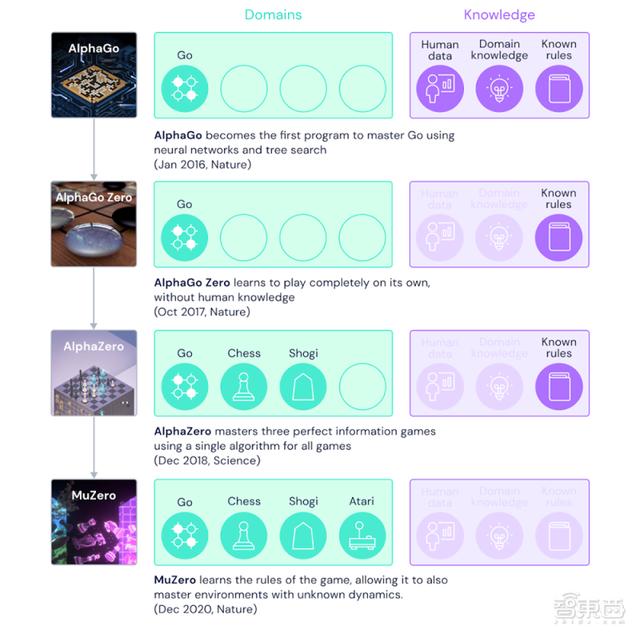
иҮӘ2016е№ҙ пјҢ д»ӨжҹҜжҙҒжөҒжіӘгҖҒи®©жқҺдё–зҹіжІүй»ҳзҡ„AlphaGoжЁӘз©әеҮәдё– пјҢ жү“йҒҚжЈӢеқӣж— дәәиғҪж•ҢеҗҺ пјҢ AIжЈӢжүӢзҡ„еҗҚеҸ·е°ұжӯӨдёҖзӮ®жү“е“Қ пјҢ иҖҢе…¶иғҢеҗҺзҡ„еҸ‘жҳҺ家DeepMindеҚҙжІЎжңүеӣ жӯӨжӯўжӯҘ пјҢ еӣӣе№ҙд№ӢеҶ…иҝӯд»ЈдәҶеӣӣд»ЈAIжЈӢжүӢ пјҢ ж¬Ўж¬ЎйғҪжңүж–°зӘҒз ҙ гҖӮ
е§ӢзҘ–AlphaGoеҹәдәҺдәәзұ»жЈӢжүӢзҡ„и®ӯз»ғж•°жҚ®е’ҢжёёжҲҸ规еҲҷ пјҢ йҮҮз”ЁдәҶзҘһз»ҸзҪ‘з»ңе’Ңж ‘зҠ¶жҗңзҙўж–№жі• пјҢ жҲҗдёәдәҶ第дёҖдёӘзІҫйҖҡеӣҙжЈӢзҡ„AIжЈӢжүӢ гҖӮ
дәҢд»ЈAlphaGo ZeroдәҺ2017е№ҙеңЁгҖҠNatureгҖӢеҸ‘иЎЁ пјҢ дёҺдёҠд»ЈзӣёжҜ” пјҢ дёҚйңҖиҰҒдәәзұ»жЈӢжүӢжҜ”иөӣж•°жҚ®дҪңдёәи®ӯз»ғйӣҶ пјҢ иҖҢжҳҜйҖҡиҝҮиҮӘеҜ№жҠ—зҡ„ж–№ејҸиҮӘе·ұи®ӯз»ғеҮәжңҖдҪіжЁЎеһӢ гҖӮ
дёүд»ЈAlphaZeroеңЁ2018е№ҙиҜһз”ҹ пјҢ е°ҶйҖӮеә”йўҶеҹҹжӢ“е®ҪиҮіеӣҪйҷ…иұЎжЈӢе’Ңж—Ҙжң¬е°ҶжЈӢ пјҢ иҖҢдёҚжҳҜд»…йҷҗдәҺеӣҙжЈӢ гҖӮ
第еӣӣд»ЈгҖҒд№ҹе°ұжҳҜд»ҠеӨ©ж–°е…¬еёғMuZeroжңҖеӨ§зҡ„зӘҒз ҙе°ұеңЁдәҺеҸҜд»ҘеңЁдёҚзҹҘйҒ“жёёжҲҸ规еҲҷзҡ„жғ…еҶөдёӢиҮӘеӯҰ规еҲҷ пјҢ дёҚд»…еңЁжӣҙзҒөжҙ»гҖҒжӣҙеӨҡеҸҳеҢ–зҡ„AtariжёёжҲҸдёҠд»ЈиЎЁдәҶAIзҡ„жңҖејәж°ҙе№і пјҢ еҗҢж—¶еңЁеӣҙжЈӢгҖҒеӣҪйҷ…иұЎжЈӢгҖҒж—Ҙжң¬е°ҶжЈӢйўҶеҹҹд№ҹдҝқжҢҒдәҶзӣёеә”зҡ„дјҳеҠҝең°дҪҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёҖгҖҒд»ҺжңӘзҹҘдёӯеӯҰд№ пјҡдёүиҰҒзҙ жҗӯе»әеҠЁжҖҒжЁЎеһӢдёҺжңәеҷЁж“…й•ҝйҮҚеӨҚжҖ§зҡ„и®Ўз®—е’Ңзүўеӣәзҡ„и®°еҝҶдёҚеҗҢ пјҢ дәәзұ»жңҖеӨ§зҡ„дјҳеҠҝе°ұжҳҜйў„жөӢиғҪеҠӣ пјҢ д№ҹе°ұжҳҜйҖҡиҝҮзҺҜеўғгҖҒз»ҸйӘҢзӯүзӣёе…ідҝЎжҒҜ пјҢ жҺЁжөӢеҸҜиғҪдјҡеҸ‘з”ҹзҡ„дәӢжғ… гҖӮ
жҜ”еҰӮ пјҢ еҪ“жҲ‘们зңӢеҲ°д№Ңдә‘еҜҶеёғ пјҢ жҲ‘们дјҡжҺЁжөӢд»ҠеӨ©еҸҜиғҪжңүйӣЁ пјҢ 然еҗҺеҶҚйҮҚж–°иҖғиҷ‘жҳҜеҗҰиҰҒеҮәй—Ё гҖӮ еҚідҪҝеҜ№дәҺд»…жңүеҮ еІҒзҡ„еӯ©еӯҗиҖҢиЁҖ пјҢ еӯҰдјҡиҝҷз§Қйў„жөӢж–№ејҸ пјҢ 然еҗҺжҺЁе№ҝеҲ°з”ҹжҙ»зҡ„ж–№ж–№йқўйқўд№ҹжҳҜеҫҲе®№жҳ“ пјҢ дҪҶиҝҷеҜ№дәҺжңәеҷЁжқҘиҜҙ并дёҚз®ҖеҚ• гҖӮ
еҜ№жӯӨ пјҢ DeepMindз ”з©¶дәәе‘ҳжҸҗеҮәдәҶдёӨз§Қж–№жЎҲпјҡеүҚеҗ‘жҗңзҙўе’ҢеҹәдәҺжЁЎеһӢзҡ„规еҲ’з®—жі• гҖӮ
еүҚеҗ‘жҗңзҙўеңЁдәҢд»ЈAlphaZeroдёӯе°ұе·Із»Ҹеә”з”ЁиҝҮдәҶ пјҢ е®ғеҖҹеҠ©еҜ№жёёжҲҸ规еҲҷжҲ–жЁЎжӢҹеӨҚзӣҳзҡ„ж·ұеҲ»зҗҶи§Ј пјҢ еҲ¶е®ҡеҰӮи·іжЈӢгҖҒеӣҪйҷ…иұЎжЈӢе’Ңжү‘е…Ӣзӯүз»Ҹе…ёжёёжҲҸзҡ„жңҖдҪізӯ–з•Ҙ гҖӮ дҪҶиҝҷдәӣзҡ„еҹәзЎҖжҳҜе·ІзҹҘжёёжҲҸ规еҲҷеҸҠеҜ№еҸҜиғҪеҮәзҺ°зҡ„зҠ¶еҶөеӨ§йҮҸжЁЎжӢҹ пјҢ 并дёҚйҖӮз”Ёжғ…еҶөзӣёеҜ№ж··д№ұзҡ„AtariжёёжҲҸ пјҢ жҲ–иҖ…жңӘзҹҘжёёжҲҸ规еҲҷзҡ„жғ…еҶө гҖӮ
еҹәдәҺжЁЎеһӢзҡ„规еҲ’еҲҷжҳҜйҖҡиҝҮеӯҰд№ зҺҜеўғеҠЁжҖҒиҝӣиЎҢзІҫеҮҶе»әжЁЎ пјҢ еҶҚз»ҷдәҲжЁЎеһӢз»ҷеҮәжңҖдҪізӯ–з•Ҙ гҖӮ дҪҶеҜ№дәҺзҺҜеўғе»әжЁЎжҳҜеҫҲеӨҚжқӮзҡ„ пјҢ д№ҹдёҚйҖӮз”ЁдәҺAtariзӯүи§Ҷи§үеҠЁз”»жһҒеӨҡзҡ„жёёжҲҸ гҖӮ зӣ®еүҚжқҘзңӢ пјҢ иғҪеӨҹеңЁAtariжёёжҲҸдёӯиҺ·еҫ—жңҖеҘҪз»“жһңзҡ„жЁЎеһӢпјҲеҰӮDQNгҖҒR2D2е’ҢAgent57пјү пјҢ йғҪжҳҜж— жЁЎеһӢзі»з»ҹ пјҢ д№ҹе°ұжҳҜдёҚдҪҝз”ЁеӯҰд№ иҝҮзҡ„жЁЎеһӢ пјҢ иҖҢжҳҜеҹәдәҺйў„жөӢжқҘйҮҮеҸ–дёӢдёҖжӯҘиЎҢеҠЁ гҖӮ
д№ҹжҳҜз”ұдәҺд»ҘдёҠдёӨдёӘж–№жі•дёӯзҡ„дјҳеҠЈ пјҢ MuZeroжІЎжңүеҜ№зҺҜеўғдёӯжүҖжңүзҡ„иҰҒзҙ иҝӣиЎҢе»әжЁЎ пјҢ иҖҢжҳҜд»…й’ҲеҜ№дёүдёӘйҮҚиҰҒзҡ„иҰҒзҙ пјҡ
1гҖҒд»·еҖјпјҡеҪ“еүҚеӨ„еўғзҡ„еҘҪеқҸжғ…еҶөпјӣ
2гҖҒзӯ–з•Ҙпјҡзӣ®еүҚиғҪйҮҮеҸ–зҡ„жңҖдҪіиЎҢеҠЁпјӣ
3гҖҒеҘ–еҠұпјҡжңҖеҗҺдёҖдёӘеҠЁдҪңе®ҢжҲҗеҗҺжғ…еҶөзҡ„еҘҪеқҸ гҖӮ
йӮЈжҺҘдёӢжқҘ пјҢ жҲ‘们е°ұжқҘзңӢзңӢMuZeroжҳҜеҰӮдҪ•йҖҡиҝҮиҝҷдёүдёӘиҰҒзҙ иҝӣиЎҢе»әжЁЎ гҖӮ
MuZeroд»ҺеҪ“еүҚдҪҚзҪ®ејҖе§ӢпјҲеҠЁз”»йЎ¶йғЁпјү пјҢ дҪҝз”ЁиЎЁзӨәеҠҹиғҪHе°Ҷзӣ®еүҚзҠ¶еҶөжҳ е°„еҲ°зҘһз»ҸзҪ‘з»ңдёӯзҡ„еөҢе…ҘеұӮпјҲS0пјү пјҢ 并дҪҝз”ЁеҠЁжҖҒеҮҪж•°пјҲGпјүе’Ңйў„жөӢеҮҪж•°пјҲFпјүжқҘйў„жөӢдёӢдёҖжӯҘеә”иҜҘйҮҮеҸ–зҡ„еҠЁдҪңеәҸеҲ—пјҲAпјү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҹәдәҺи’ҷзү№еҚЎжҙӣж ‘зҠ¶жҗңзҙўе’ҢMuZeroзҘһз»ҸзҪ‘з»ңиҝӣиЎҢ规еҲ’
йӮЈеҰӮдҪ•зҹҘйҒ“иҝҷдёҖжӯҘиЎҢеҠЁеҘҪдёҚеҘҪе‘ўпјҹ
MuZeroдјҡдёҺзҺҜеўғиҝӣиЎҢдә’еҠЁ пјҢ д№ҹжҳҜжЁЎжӢҹеҜ№жүӢдёӢдёҖжӯҘзҡ„иө°еҗ‘ гҖӮ
жҺЁиҚҗйҳ…иҜ»
![[иӢ№жһң]дёәдҪ•иӢ№жһңжүӢжңәи¶ҠжқҘи¶Ҡдҫҝе®ңпјҢеҚҺдёәжүӢжңәеҚҙи¶ҠжқҘи¶ҠиҙөпјҹеҸӘжңүиҝҷ1дёӘеҺҹеӣ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/0a23d79d209e8536af003d25fc9735ac.jpg)













- дёӢдёҖд»Ј AlphaGoпјҢиЈёиҖғд№ҹиғҪжӢҝж»ЎеҲҶ
- вҖңйҖҡз”Ёдә‘еҒҘеә·вҖқдә’иҒ”зҪ‘еҢ»йҷўеҗҜз”ЁжӢҘжҠұдә’иҒ”зҪ‘е®һзҺ°й«ҳиҙЁйҮҸеҸ‘еұ•
- ж°‘иҗҘиҝҗиҗҘе•Ҷдёәд»Җд№Ҳеј•зғӯи®®пјҹ9е…ғдә«5GгҖҒжөҒйҮҸе…ЁзҪ‘йҖҡз”Ёж— еҘ—и·Ҝ
- йқўеҗ‘жҷ®йҖҡз”ЁжҲ·пјҒеҶ·й—Ёе“ҒзүҢйҖҶиўӯд№Ӣи·ҜпјҢжҖ§иғҪе’Ңз»ӯиҲӘе“ӘдёӘжӣҙйҮҚиҰҒпјҹ
- жһҒе“Ғ"зңӢзүҮ"зҘһеҷЁпјҒйңҮж’јжқҘиўӯ~жүӢжңәз«Ҝзӣ’еӯҗз«Ҝе…ЁйғЁйҖҡз”Ё
- еҫ®иҪҜжҠ«йңІWindows 10Xжӣҙж–°зҡ„жӣҙеӨҡж–°з»ҶиҠӮпјҡеј•е…ҘйҖҡз”Ёй©ұеҠЁзЁӢеәҸ
- еҸҲдёҖ9е…ғеҘ—йӨҗиҜһз”ҹпјҒй«ҳйҖҹжөҒйҮҸе…ЁзҪ‘йҖҡз”ЁпјҢ5е№ҙе“ҒзүҢиҖҗзҺ©ж— еҘ—и·Ҝ
- Spotifyе…Ҙй©»EpicжёёжҲҸе•ҶеҹҺпјҡж¬Іжү“йҖ жҲҗжӣҙйҖҡз”Ёзҡ„еә”з”ЁеҲҶеҸ‘е№іеҸ°
- й’ҲеҜ№жҷ®йҖҡз”ЁжҲ·пјҢиҚЈиҖҖдҪҺи°ғдёӯз«ҜжҖ§д»·жҜ”зғӯй”ҖпјҢдҝғиҝӣзјәиҙ§еҺҹеӣ з®ҖеҚ•
- Android йҖҡз”Ёзҡ„Intentд»Ӣз»Қ