 文章插图
文章插图
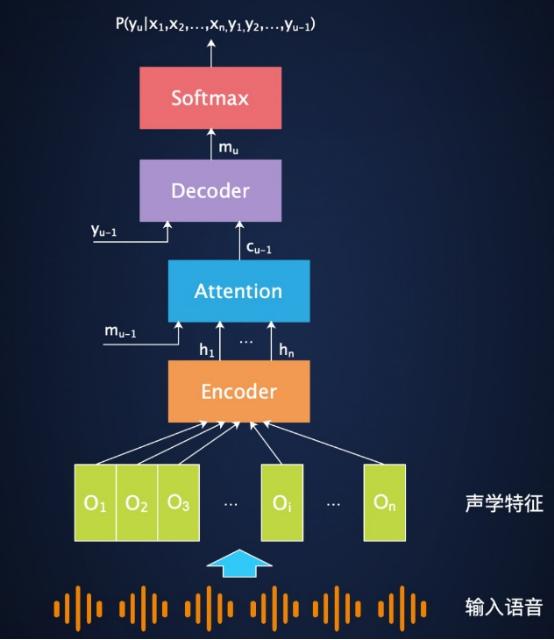
基于注意力机制的语音识别端到端建模的通用框架
2015-2020年期间 , 智能音箱产业在中国乃至世界范围内 , 都得到巨大的发展和普及 。 在智能音箱使用场景下 , 目标声源距离拾音器较远 , 致使目标信号衰减严重 , 加之环境嘈杂干扰信号众多 , 最终导致信噪比较低 , 语音识别性能较差 。 为了提升远场语音识别准确率 , 一般会使用麦克风阵列作为拾音器 , 然后利用数字信号处理领域的多通道语音信号处理技术 , 增强目标信号 , 最终产生一路清晰信号 , 送给后面的语音识别系统进行语音识别 。 这时候数字处理信号系统和语音识别系统相互级联是主流的远场语音识别技术 , 这种级联技术也成为第一代智能音箱远场语音交互技术的主流技术 。 随后 , 语音学术界开始进行一系列的技术创新 , 从数字信号处理到语音识别一体化的端到端建模成为热点 。 这是一种创新的远场语音交互技术 , 一套深度学习模型打穿数字信号处理和语音识别两个领域 。 国际上 , Google 最先试图解决这个问题 。 谷歌的解决方案采用的深度学习模型结构 , 来自于类似于 filtering and sum 的数字信号处理思想 , 模型底部的结构设计 , 模拟了数字信号处理的多路麦克处理过程 。 在此之上 , 模型仍然是采用传统的近场语音识别的深度学习模型 。 该模型直接建立了从远场语音多路信号到识别文字之间的端到端的进行 。 百度团队针对远场语音识别的特殊需求 , 也提出了自己的基于复数 CNN 的远场端到端建模方案 , 并大规模应用于工业产品 。
语音技术从之前的云端竞争开始逐渐向端侧芯片延伸
2020年左右的AI芯片的发展 , 也对语音交互行业产生了巨大的推动作用 。 在AI技术快速普及的今天 , 算力已经成为推动 AI 行业发展的根本核心力量 。 2011年微软的科学家能够把深度学习应用于语音识别工业界 , 除了科学家的勤奋工作之外 , 更重要的背后的推手是GPU 。 没有 GPU 的算力支持 , 就不可能一个月完成数千小时的 DNN 模型训练 。 从2011年至今 , 英伟达的股价已经从十几美金 , 暴涨了几十倍 。 这一点充分证明了 AI 算力的价值 , 在语音识别行业 , 远场识别的兴起催生了 AI 语音芯片的发展 。 一颗芯片完成端侧信号处理和唤醒成为一个明显的市场需求 。 在智能音箱领域 , 这种 AI 语音芯片能够显著降低音箱的成本 , 并且提供更高精度的唤醒和识别能力 。 在汽车车载导航领域 , AI 语音芯片可以保证主芯片的负载安全 , 提升驾驶安全 。 各大语音公司都开始推出自己的语音芯片 , 语音技术从之前的云端竞争又开始逐渐的向端侧芯片延伸 。
2020 年百度语音技术成果盘点
智能语音交互系统是人工智能产业链的关键环节 , 面对未来智能语音产业链的新需求 , 百度研发了新一代适合大规模工业化部署的全新端到端语音交互系统 , 实现了语音交互全链路协同处理 , 软硬件一体优化 , 信号语音一体化建模 , 语音语言一体建模 , 语音语义一体交互 , 语音图像多模态融合 , 全深度学习的语音识别、语音唤醒以及千人千面个性化语音合成等 , 其中重大技术创新如下 。
1. Attention(注意力) 技术早已经广泛应用于 NLP、图像等商业产品领域 , 但是语音识别领域 , 从 2015 年开始 , 实验室内就广泛进行了基于 Attention 的声学建模技术 , 也获得了广泛的成功 , 但是在语音识别最广泛使用的语音交互领域 , Attention 机制一直没办法应用于工业产品 。 核心原因是语音识别的流式服务要求:语音必须分片传输到服务器上 , 解码过程也必须是分片解码 , 用户话音刚落 , 语音识别结果就要完成 , 这时候人的说话过程、语音分片上传过程和语音识别的解码过程三者都是并行的 。 这样用户话音一落 , 就可以拿到识别结果 , 用户的绝对等待时间最短 , 用户体验最佳 。 传统注意力建模技术必须拿到全局语音之后 , 才开始做注意力特征抽取 , 然后再解码 , 这样一来解码器过程的耗时就不能和语音识别的解码过程同步起来 , 用户等待时间就会很长 , 不满足语音交互的实时性要求 。
推荐阅读


















- 通话数量增加超50%!WhatsApp用户在跨年夜打出14亿个语音视频通话
- 畅谈联想手机十年进化史:临时换将是没落的导火索
- 微软推“语音启动器”功能:改善用户跟Windows 10互动体验
- 获评IDC 报告7项第一,阿里语音语言AI领跑云厂商
- 科大讯飞公开质疑云知声招股书造假,语音病历市场谁主沉浮?
- Telegram新增群组语音聊天功能
- 外媒:Telegram发布了一项创新的群组语音聊天功能
- 外媒专访OPPO Benelux AED总经理 畅谈与nendo的概念设计合作
- WhatsApp测试Mac桌面客户端的语音和视频通话功能
- 手机信号栏中的HD,代表“高清语音通话”,流量不够记得要关闭