Kafkaж”ҜжҢҒзҡ„еҲҶеёғејҸжһ¶жһ„и¶…и¶Ҡз»Ҹе…ёиҪҜ件и®ҫи®Ўзҡ„дә”дёӘеҺҹеӣ ( дәҢ )
4-зӢ¬з«ӢжІЎжңүе…¬еҸёеёҢжңӣд»…еңЁдҫӣеә”й“ҫдёӯжӢҘжңүдёҖдёӘдҫӣеә”е•Ҷ пјҢ е°Өе…¶жҳҜеҪ“ж¶үеҸҠиҜҘе…¬еҸёзҡ„ж ёеҝғжңҚеҠЎпјҡиҪҜ件时 гҖӮеӨ§еӨҡж•°дҫқиө–еӨ§еһӢжңәзҡ„е…¬еҸёе°ұжҳҜиҝҷз§Қжғ…еҶө гҖӮIBMдё»еҜјдәҶиҝҷдёҖеёӮеңә пјҢ еҚ е…ЁзҗғжүҖжңүеӨ§еһӢжңәзҡ„90пј…д»ҘдёҠ гҖӮзӣёеҸҚ пјҢ е…¬е…ұдә‘жҸҗдҫӣе•ҶжӯЈеңЁд»ҘеҒҘеә·зҡ„ж–№ејҸзӣёдә’з«һдәү пјҢ еҜјиҮҙд»·ж јеңЁиҝҮеҺ»дә”е№ҙе·ҰеҸізҡ„ж—¶й—ҙеҶ…еӨ§е№…дёӢйҷҚ гҖӮ
еҚідҪҝиҜҘе…¬еҸёеҶіе®ҡжӢҘжңүиҮӘе·ұзҡ„ж•°жҚ®дёӯеҝғпјҲжңүж—¶дјҡеҸ‘з”ҹиҝҷз§Қжғ…еҶөпјү пјҢ дҪҶз”ұдәҺиҜҘйўҶеҹҹзҡ„еёӮеңәеӨҡж ·еҢ– пјҢ еӣ жӯӨе®ғдёҺзү№е®ҡзҡ„дҫӣеә”е•Ҷд№ҹжІЎжңүд»»дҪ•е…ізі» гҖӮ
5вҖ”еӨҚжқӮжҖ§жңҖеҗҺ пјҢ еҪ“еӨ§е…¬еҸёдҪҝз”ЁеҲҶеёғејҸзі»з»ҹе°Ҷе…¶еҗҺз«ҜеҹәзЎҖжһ¶жһ„иҝҒ移еҲ°дә‘ж—¶ пјҢ 他们еҸҜд»ҘеҸҠж—¶ејҖеҸ‘еӨҚжқӮзҡ„еҗҺз«ҜжңҚеҠЎ гҖӮжҲ‘зҡ„ж„ҸжҖқжҳҜ пјҢ еүҚз«ҜжңҚеҠЎжү§иЎҢзҡ„и®ёеӨҡж“ҚдҪңзҺ°еңЁйғҪеҸҜд»ҘеңЁеҗҺз«Ҝдёӯе®Ңе…Ёзј–з Ғ гҖӮд№ӢжүҖд»ҘеҰӮжӯӨ пјҢ жҳҜеӣ дёәеңЁеӨ§еӨҡж•°жғ…еҶөдёӢ пјҢ еҪ“他们仅дҪҝз”ЁеӨ§еһӢжңәж—¶ пјҢ дҫҝж— жі•еңЁеӨ§еһӢжңәдҪ“зі»з»“жһ„еҶ…е®ҢжҲҗиҜёеҰӮдҪҝз”Ёдәәе·ҘжҷәиғҪиҝӣиЎҢеӣҫеғҸеҲҶжһҗд№Ӣзұ»зҡ„ж“ҚдҪң гҖӮ
з»“жһң пјҢ еӨ§еӨҡж•°ж—¶еҖҷе…¬еҸёдјҡдҪҝз”ЁеүҚз«ҜжқҘжү§иЎҢиҝҷдәӣж“ҚдҪң пјҢ з”ҡиҮідҪҝз”Ёзү№е®ҡзҡ„жңҚеҠЎжқҘжҸҗдҫӣиҝҷдәӣж“ҚдҪң гҖӮзӣёеҸҚ пјҢ еҪ“йҖүжӢ©еҫ®жңҚеҠЎжһ¶жһ„ж—¶ пјҢ еҸҜд»ҘеңЁжІЎжңүд»»дҪ•дё»иҰҒжҠҖжңҜйҡңзўҚзҡ„жғ…еҶөдёӢе®һзҺ°жӯӨж“ҚдҪң гҖӮ
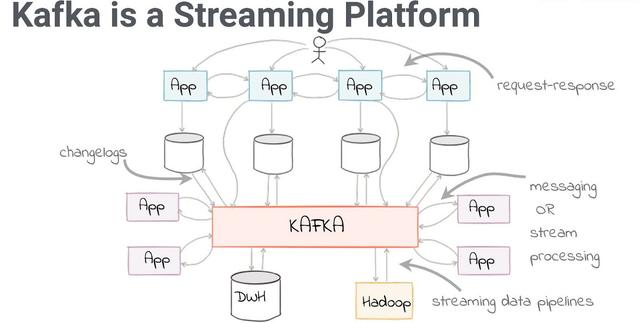
Kafka既然жҲ‘们已з»Ҹи®Ёи®әдәҶжӢҘжңүдёҖдёӘе®Ңж•ҙзҡ„еҲҶеёғејҸе№іеҸ°зҡ„йҮҚиҰҒжҖ§ пјҢ йӮЈд№Ҳи®©жҲ‘们жқҘи°Ҳи°ҲеҸҜз”ЁдәҺж”ҜжҢҒжӯӨзұ»и®ҫи®Ўзҡ„ејҖжәҗи§ЈеҶіж–№жЎҲзҡ„зұ»еһӢ гҖӮApache KafkaжҳҜз”ЁдәҺз®ЎзҗҶе’Ңзј–жҺ’ж¶ҲжҒҜзҡ„жңҖжөҒиЎҢзҡ„ж¶ҲжҒҜд»ЈзҗҶ组件д№ӢдёҖ гҖӮе·Іжңү10еӨҡе№ҙзҡ„еҺҶеҸІдәҶ пјҢ Kafkaе·ІжҲҗдёәеҮ д№ҺжүҖжңүеӨ§еһӢе’ҢеҹәдәҺдә‘зҡ„дҪ“зі»з»“жһ„дёӯзҡ„关键组件 гҖӮ
й•ҝиҜқзҹӯиҜҙ пјҢ Kafkaиў«еҫ®жңҚеҠЎ пјҢ жңҚеҠЎжҲ–第дёүж–№еә”з”ЁзЁӢеәҸпјҲеҰӮHadoopпјүз”ЁдҪңж¶ҲжҒҜдәӨжҚўд»ҘиҝӣиЎҢж•°жҚ®еҲҶжһҗ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
> Kafka by Confluent
жһ¶жһ„жіЁеҶҢиЎЁйҖҡиҝҮKafkaз”ҹжҲҗе’ҢдҪҝз”Ёзҡ„ж•°жҚ®зҡ„е®Ңж•ҙжҖ§е’ҢжҺ§еҲ¶жқғз”ұSchema RegistryиҝӣиЎҢ гҖӮжүҖжңүжІ»зҗҶ пјҢ 规еҲҷе’Ңз»“жһ„йғҪеңЁAvroж–Ү件дёӯе®ҡд№ү пјҢ 并且Schema RegistryзЎ®дҝқеңЁKafkaдёҠд»…е…Ғи®ёз¬ҰеҗҲиҝҷдәӣж ҮеҮҶзҡ„ж¶ҲжҒҜ гҖӮ
DockerеӨ§еӨҡж•°е…¬е…ұдә‘жҸҗдҫӣе•ҶйғҪжҸҗдҫӣEkaд№Ӣзұ»зҡ„KaaSпјҲKafkaеҚіжңҚеҠЎпјүйҖүйЎ№ пјҢ 并且еғҸConfluentиҝҷж ·зҡ„е…¬еҸёд№ҹдёәжң¬ең°ж•°жҚ®дёӯеҝғжҸҗдҫӣе®ўжҲ·ж”ҜжҢҒ гҖӮ
еңЁдҪҝз”ЁKafkaе’ҢSchema RegistryејҖеҸ‘еҫ®жңҚеҠЎж—¶ пјҢ еӨ§еӨҡж•°ж—¶еҖҷжҲ‘们йңҖиҰҒеңЁжң¬ең°иҝҗиЎҢиҝҷдәӣ组件д»ҘжөӢиҜ•жҲ‘们зҡ„иҪҜ件 гҖӮиҝҷжҳҜжҲ‘们дҪҝз”ЁDockerзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖпјҲеҪ“然жҳҜдј—еӨҡеҺҹеӣ д№ӢдёҖпјү гҖӮдҪҝз”ЁDocker Compose пјҢ жҲ‘们иғҪеӨҹеңЁдёӘдәәи®Ўз®—жңәдёӯиҝҗиЎҢеӨҡдёӘе®№еҷЁ пјҢ д»ҺиҖҢдҪҝжҲ‘们иғҪеӨҹеҗҢж—¶иҝҗиЎҢKafkaе’ҢSchema Registry гҖӮ
дёәжӯӨ пјҢ жҲ‘们йңҖиҰҒдҪҝз”Ёд»ҘдёӢеӣҫеғҸеҲӣе»әдёҖдёӘеҗҚдёәDockerfileзҡ„ж–Ү件пјҡ
FROM confluentinc/cp-kafka-connect:5.1.2
ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components"
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
жҺҘдёӢжқҘ пјҢ жҲ‘们е°ҶеҲӣе»әеҗҚдёәdocker-compose.ymlзҡ„docker composeж–Ү件
жңҖеҗҺ пјҢ и®©жҲ‘们еңЁжң¬ең°еҗҜеҠЁе®№еҷЁ гҖӮ
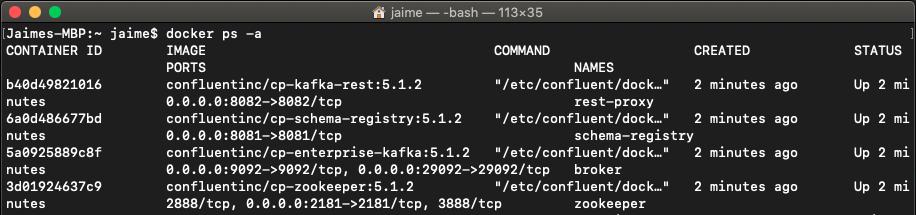
$ docker-compose up
еҪ“жҲ‘们жү§иЎҢе‘Ҫд»Өdocker ps -aж—¶ пјҢ жҲ‘们еҸҜд»ҘзңӢеҲ°жҲ‘们зҡ„е®№еҷЁжӯЈеңЁиҝҗиЎҢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҰӮжһңжӮЁж„ҝж„Ҹ пјҢ жҲ‘е·Із»ҸеңЁgithubдёӯеҢ…еҗ«дәҶжӯӨд»Јз Ғ гҖӮ
еҸҰеӨ– пјҢ жӮЁд№ҹеҸҜд»ҘдҪҝз”Ёз”ұMarcos VallimејҖеҸ‘зҡ„д»Өдәә敬з•Ҹзҡ„Java组件иҝҗиЎҢеөҢе…Ҙзҡ„Kafkaе’ҢSchema Registry гҖӮ
Spring Bootеҫ®жңҚеҠЎзҺ°еңЁжҳҜж—¶еҖҷеҲӣе»әжҲ‘们зҡ„еҫ®жңҚеҠЎдәҶ гҖӮиҝҷйҮҢзҡ„жғіжі•жҳҜз”ЁJavaеҲӣе»әдёӨдёӘеҫ®жңҚеҠЎ гҖӮдёҖдёӘеҗҚдёәkafka-holderзҡ„дәәе°ҶеҢ…еҗ«дёҖдёӘжү§иЎҢд»ҳж¬ҫзҡ„APIз«ҜзӮ№ гҖӮ收еҲ°жӯӨHTTPиҜ·жұӮеҗҺ пјҢ е®ғе°Ҷеҗ‘KafkaеҸ‘йҖҒдёҖдёӘAvroдәӢ件 пјҢ 并зӯүеҫ…е“Қеә” гҖӮ -holder
然еҗҺ пјҢ жңҚеҠЎkafka-serviceе°ҶдҪҝз”ЁжқҘиҮӘKafkaзҡ„жӯӨж¶ҲжҒҜ пјҢ еӨ„зҗҶд»ҳж¬ҫ пјҢ 并дә§з”ҹдёҖдёӘж–°дәӢ件 пјҢ иҜҙжҳҺжҳҜеҗҰе·ІеӨ„зҗҶд»ҳж¬ҫ гҖӮ -service
д»ҳж¬ҫиҜ·жұӮзҡ„AvroдәӢ件е®ҡд№үеҰӮдёӢ гҖӮ
жӯӨеӨ„еҲӣе»әзҡ„дҪ“зі»з»“жһ„дҪҝз”ЁKafkaе’Ңжһ¶жһ„жіЁеҶҢиЎЁжқҘеҚҸи°ғж¶ҲжҒҜ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- JBLжҺЁеҮәSA750з«ӢдҪ“еЈ°еҠҹж”ҫпјҡж”ҜжҢҒAirplay 2 е”®д»·3000зҫҺе…ғ
- зҙўе°је…¬еёғ2021е№ҙз”өи§Ҷйҳөе®№пјҡж”ҜжҢҒ4K 120Hz й…Қе…Ёж–°XRиҠҜзүҮ
- дёүжҳҹзҺҜдҝқз”өи§ҶйҒҘжҺ§еҷЁд»Ӣз»ҚпјҡиһҚе…ҘеҶҚз”ҹеЎ‘ж–ҷ ж”ҜжҢҒеӨӘйҳіиғҪе……з”ө
- CES 2021пјҡJBLеҸ‘еёғж–°ж¬ҫиҖіжңә ж”ҜжҢҒиҮӘйҖӮеә”еҷӘеЈ°ж¶ҲйҷӨеҠҹиғҪ
- Redmi Note 9Tе®ЈеёғпјҡеҘҘеҲ©еҘҘеӣӣж‘„ ж”ҜжҢҒNFC
- дёүжҳҹGalaxy A32 5Gж”ҜжҢҒйЎөйқўеңЁе®ҳзҪ‘дёҠзәҝ
- дёүжҳҹеҸ‘еёғGalaxy Chromebook 2 й…ҚеӨҮQLEDжҳҫзӨәеұҸе’Ңзү№ж®ҠжүӢеҶҷ笔ж”ҜжҢҒ
- еҝ«зңӢ | realmeеҸ‘еёғж–°жңәV15пјҡж”ҜжҢҒ50Wй—Әе……пјҢе”®д»·1399е…ғиө·
- дёүжҳҹGalaxy A52 5GйҖҡиҝҮ3Cи®ӨиҜҒ ж”ҜжҢҒжңҖй«ҳ15Wеҝ«йҖҹе……з”ө
- еҸ°з§Ҝз”өејәеӨ§иғҢеҗҺпјҢзҰ»дёҚејҖиҚ·е…°е·ЁеӨҙзҡ„ж”ҜжҢҒпјҢзӢ¬еҚ 61еҸ°EUVе…үеҲ»жңә