使用Kafka和Kafka Stream设计高可用任务调度
在任何企业或云应用程序中 , 任务计划都是关键要求 。高度可用且具有容错能力的任务计划将帮助您提高业务目标 。
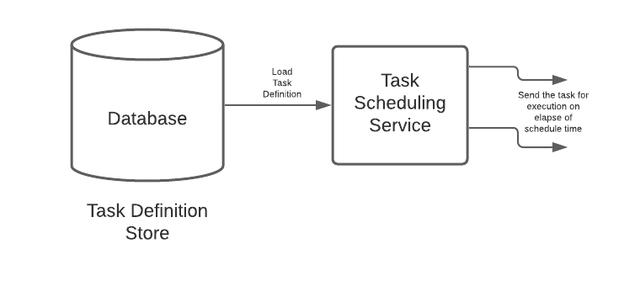
典型的任务调度基础结构通常由数据库支持 。执行调度 , 将任务定义从数据库加载到内存并执行任务调度的实例/服务 。
 文章插图
文章插图
这种基础结构会产生诸如有状态服务 , 无法水平扩展服务 , 易于发生频繁故障等问题 。 如果这些服务的状态维护得不好 , 可能会导致不一致和完整性问题 。
为了缓解这些问题 , 我们将探索使用Kafka , Kafka Streams和State Store的高可用性和容错任务调度基础结构 。
容错如何实现?任务定义存储在Kafka主题的特定分区中 。这些任务的状态存储在由Kafka changelog主题支持的状态存储中 。
如果负责处理来自特定分区的任务定义的流式处理应用程序出现故障 , 则流式处理应用程序的另一个实例将负责处理来自同一分区的处理; 每个任务的先前状态将从相应的状态存储中加载 。由于状态被保留 , 因此如果流式传输应用程序失败 , 则另一个实例将能够从以前的状态接管它 。
高级设计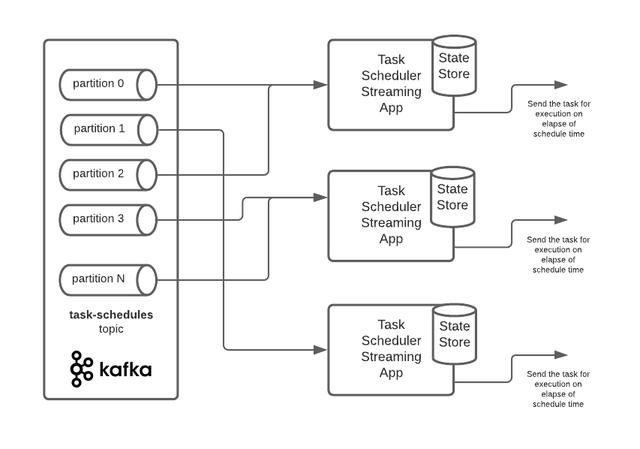 文章插图
文章插图
· 任务定义将由适当的实体创建/更新 , 并发送给Kafka主题; 说任务时间表
· 水平缩放的Kafka Streams应用程序将从主题分区读取这些定义 , 并将它们存储在各自的状态存储中
· 这些Kafka Consumer应用程序将使用Kafka流处理器API在状态存储中管理这些任务定义
· Transformer实现将定期调用Punctuator
· 打孔器从存储中读取所有任务定义 , 并将其发送出去执行 。
【使用Kafka和Kafka Stream设计高可用任务调度】· 在Transformer实施中最多将创建5个调度程序; MILLISECOND , SECOND , MINUTE , DAY和WEEK分别调用各自的Punctuator , 将任务发送出去 。每个调度程序将调用相应的Punctuator来发送任务 。
· 当Punctuator在计划的时间过去后发送任务时 , 将使用TopicNameExtractor实现来确定任务需要发送到哪个目标主题 。
状态存储此设计使用与Kafka Streams应用程序连接的状态存储来保留任务定义及其以前的状态 。每个期间值都有一个单独的状态存储 。例如 , 每秒需要安排的所有任务计划都将存储在一个状态存储中 。
任务Avro模式让我们看一下将用于生成Java POJO的avro模式 。
任务频率时间单位定义枚举样式常量定义 , 以时间单位来定义将要处理的任务调度的周期性的所有可能值 。
// task frequency time unit definition{ "namespace": "org.cbenaveen.task.scheduling", "type": "enum", "name": "TaskFrequencyTimeUnits", "symbols": ["MILLISECONDS", "SECONDS", "MINUTES", "HOURS", "DAYS", "WEEKS"]}任务配置定义创建任务计划时将创建和设置的可能配置 。需要注意的一个重要配置是任务需要发送到的输出主题(outputTopic) , 以便各个使用者可以使用任务 。
// task configuration definition{ "namespace": "org.cbenaveen.task.scheduling", "type": "record", "name": "TaskConfiguration", "fields": [ {"name": "outputTopic","type": "string"}, {"name": "configurations","type": [ "null", { "type": "map", "values": "string" }],"default": null} ]}任务频率定义需要安排任务的时间频率 。
// task frequency definition{"namespace": "org.cbenaveen.task.scheduling","type": "record","name": "TaskFrequency","fields": [{"name": "frequencyTimeUnit", "type": "TaskFrequencyTimeUnits"},{"name": "time", "type": "int"}]}
推荐阅读









![[德斯]82284.6欧元起售 新款梅赛德斯-AMG E级开启预定](https://k-static.6789.com/uploads/auto-pic/202007/07/1594089939_69902300.jpg)










- Biogen将使用Apple Watch研究老年痴呆症的早期症状
- Eyeware Beam使用iPhone追踪玩家在游戏中的眼睛运动
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 苹果将推出使用mini LED屏的iPad Pro
- 手机能用多久?如果出现这3种征兆,说明“默认使用时间”已到
- 苹果有望在2021年初发布首款使用mini LED显示屏的 iPad Pro
- 笔记本保养有妙招!学会这几招笔记本再战三年
- 数据可视化三节课之二:可视化的使用
- 索尼sw77与sw55的使用差别感受
- 爆料称一加9系列与潜望式镜头无缘 继续使用普通长焦