终于把Redis场景设计搞清楚了,需要掌握的都在这了
分布式缓存是分布式系统中的重要组件 , 主要解决高并发、大数据场景下 , 热点数据访问的性能问题 , 提供高性能的数据快速访问 。
使用缓存常见场景是:项目中部分数据访问比较频繁 , 对下游 DB(例如 MySQL)造成服务压力 , 这时候可以使用缓存来提高效率 。 下面来讲BAT等一线企业中Redis各种应用场景核心设计!
一、常用指令接下来看看每个数据结构常用的指令有哪些 , 我们用一张表比较清晰的展示:
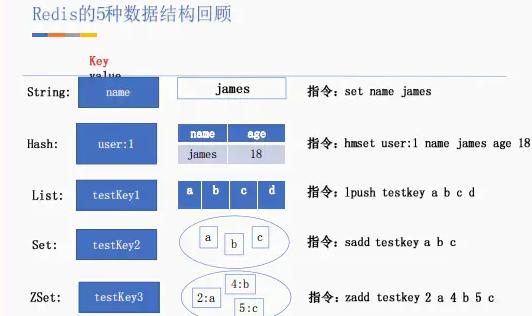 文章插图
文章插图
二、场景解析1.1string存储 文章插图
文章插图
1.2String 类型使用场景场景一:商品库存数从业务上 , 商品库存数据是热点数据 , 交易行为会直接影响库存 。 而 Redis 自身 String 类型提供了:
- set goods_id 10; 设置 id 为 good_id 的商品的库存初始值为 10;
- decr goods_id; 当商品被购买时候 , 库存数据减 1 。
场景二:时效信息存储Redis 的数据存储具有自动失效能力 。 也就是存储的 key-value 可以设置过期时间:set(key, value, expireTime) 。
比如 , 用户登录某个 App 需要获取登录验证码 ,验证码在 30 秒内有效 。 那么我们就可以使用 String 类型存储验证码 , 同时设置 30 秒的失效时间 。
 文章插图
文章插图2.1hash存储数据
 文章插图
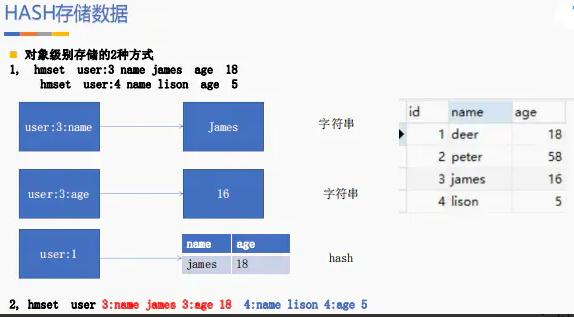
文章插图2.2Hash 类型使用场景Redis 在存储对象(例如:用户信息)的时候需要对对象进行序列化转换然后存储 。
还有一种形式 , 就是将对象数据转换为 JSON 结构数据 , 然后存储 JSON 的字符串到 Redis 。
对于一些对象类型 , 还有一种比较方便的类型 , 那就是按照 Redis 的 Hash 类型进行存储 。
例如 , 我们存储一些网站用户的基本信息 ,我们可以使用:
这样就存储了一个用户基本信息 , 存储信息有:{name : 小明 ,phone : “123456” , sex : “男”}
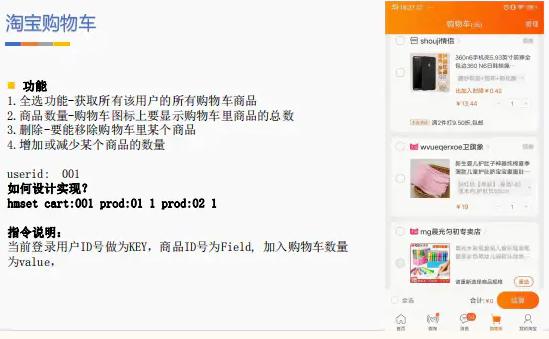
当然这种类似场景还非常多 ,比如存储订单的数据 , 产品的数据 , 商家基本信息等 。 以淘宝购物车为主
 文章插图
文章插图2.3实现信息存储的优缺点1.原生:
- set user: 1:name james;
- set user:1:age 23;
- set user:1:sex boy;
缺点:键数过多 , 占用内存多 , 用户信息过于分散 , 不用于生产环境
2.将对象序列化存入
redis set user:1 serial ize (userInfo);
优点:编程简单 , 若使用序列化合理内存使用率高
缺点:序列化与反序列化有一定开销 , 更新属性时需要把userInfo全取出来进行反序列化 , 更新后再序列化到redis
3.hash存储:
hmset user:1 name james age 23 sex boy
优点:简单直观 , 使用合理可减少内存空间消耗
缺点:要控制ziplist 与hashtable两种编码转换 , Mhashtable会消耗更多内存 。
3.1List 类型使用场景list 是按照插入顺序排序的字符串链表 。 可以在头部和尾部插入新的元素(双向链表实现 , 两端添加元素的时间复杂度为 O(1))。
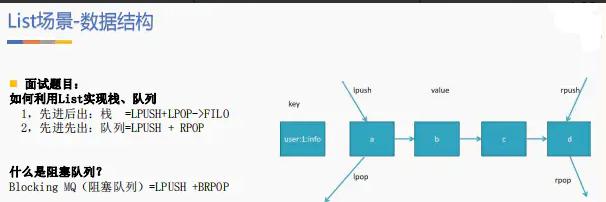 文章插图
文章插图
推荐阅读
















- V-Moda发布M-200 ANC耳机新品 经典机型终于有了主动降噪
- 2021 年,微软 Windows 的 ARM 转型终于能成了?
- 微信又迎来更新!你们想要的功能终于来了
- 虾米音乐正式关停:成立12年错失很多机会,将转型商业场景服务
- 美的探索工业互联网+5G+AI应用场景,成本可降低10%
- 1月12日!荣耀V40系列终于要来了!将采用库存“芯片”
- 微信也准备“收费”了?2大业务开始付费,网友:终于要来了
- 广受诟病的Edge同步短板终于补齐:现可同步历史记录
- 继iQOO、华为官宣后,雷军终于坐不住了,为小米11做准备
- 华为全场景落地山东省会大剧院:用科技谱写“城市音符”