иҮӘ然иҜӯиЁҖеӨ„зҗҶеңЁејҖж”ҫжҗңзҙўдёӯзҡ„еә”з”Ё( дәҢ )
 ж–Үз« жҸ’еӣҫ
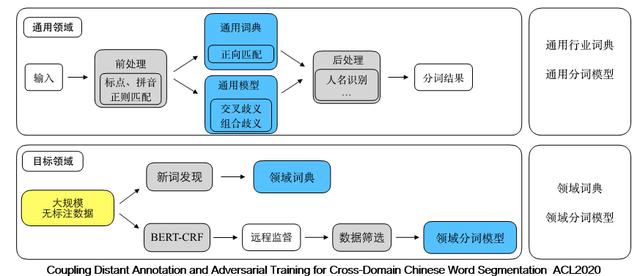
ж–Үз« жҸ’еӣҫпјҲдёҠеӣҫдёәиҮӘеҠЁи·ЁйўҶеҹҹеҲҶиҜҚжЎҶжһ¶пјүз”ЁжҲ·еҸӘйңҖиҰҒжҸҗдҫӣз»ҷжҲ‘们дёҖдәӣиҮӘе·ұдёҡеҠЎзҡ„иҜӯж–ҷж•°жҚ® пјҢ жҲ‘们е°ұеҸҜд»ҘиҮӘеҠЁзҡ„еҫ—еҲ°дёҖдёӘе®ҡеҲ¶еҢ–зҡ„еҲҶиҜҚжЁЎеһӢ пјҢ иҝҷдёҚд»…еӨ§еӨ§жҸҗеҚҮдәҶж•ҲзҺҮ пјҢ еҗҢж—¶д№ҹжӣҙеҝ«ж»Ўи¶іе®ўжҲ·зҡ„йңҖжұӮ гҖӮ йҖҡиҝҮиҝҷдёӘжҠҖжңҜ пјҢ жҲ‘们еҸҜд»ҘеңЁеҗ„дёӘйўҶеҹҹиҺ·еҫ—жҜ”ејҖжәҗйҖҡз”ЁеҲҶиҜҚ пјҢ жӣҙеҘҪзҡ„ж•Ҳжһң
 ж–Үз« жҸ’еӣҫ
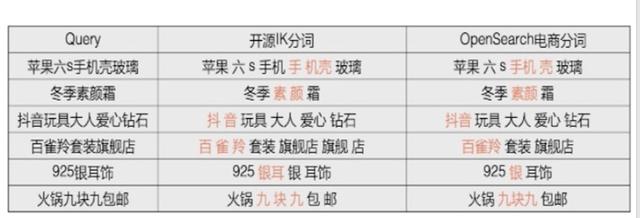
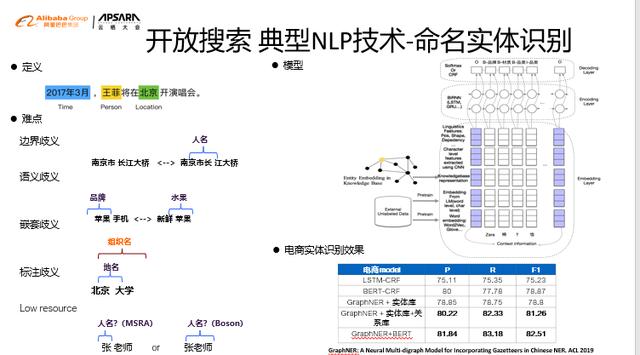
ж–Үз« жҸ’еӣҫе‘ҪеҗҚе®һдҪ“иҜҶеҲ«е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲNERпјү пјҢ дҫӢеҰӮд»ҺqueryдёӯжҸҗеҸ–дәәеҗҚ ең°еҗҚ ж—¶й—ҙзӯү гҖӮ жҢ‘жҲҳдёҺеӣ°йҡҫNERеңЁNLPйўҶеҹҹз ”з©¶йқһеёёеӨҡеҗҢж—¶д№ҹйқўдёҙеҫҲеӨҡзҡ„жҢ‘жҲҳ пјҢ е°Өе…¶еңЁдёӯж–ҮдёҠз”ұдәҺзјәд№ҸеӨ©з„¶еҲҶйҡ”з¬Ұ пјҢ йқўдёҙиҫ№з•Ңжӯ§д№үгҖҒиҜӯд№үжӯ§д№үгҖҒеөҢеҘ—жӯ§д№үзӯүеӣ°йҡҫ гҖӮ **и§ЈеҶіжҖқи·Ҝ**? дёӢеӣҫеҸідёҠи§’жҳҜжҲ‘们еңЁејҖж”ҫжҗңзҙўдёӯдҪҝз”Ёзҡ„жЁЎеһӢжһ¶жһ„еӣҫпјӣ? еңЁејҖж”ҫжҗңзҙўдёӯ пјҢ еҫҲеӨҡз”ЁжҲ·йғҪз§ҜзҙҜдәҶеӨ§йҮҸиҜҚе…ёе®һдҪ“еә“ гҖӮ дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдәӣиҜҚе…ё пјҢ жҲ‘们жҸҗеҮәдәҶдёҖз§ҚеңЁbertд№ӢдёҠ пјҢ жңүжңәиһҚеҗҲзҹҘиҜҶзҡ„graphNerжЎҶжһ¶ гҖӮ д»ҺеҸідёӢи§’зҡ„иЎЁж јеҸҜд»ҘзңӢеҮә пјҢ еңЁдёӯж–ҮдёҠиғҪеҸ–еҫ—жңҖеҘҪзҡ„ж•Ҳжһңпјӣ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжӢјеҶҷзә й”ҷејҖж”ҫжҗңзҙўеҲҶдёә4дёӘзә й”ҷжӯҘйӘӨеҢ…еҗ«дәҶжҢ–жҺҳгҖҒи®ӯз»ғгҖҒиҜ„дј°е’ҢеңЁзәҝйў„жөӢ гҖӮ дё»иҰҒзҡ„жЁЎеһӢж №жҚ®з»ҹи®Ўзҝ»иҜ‘жЁЎеһӢе’ҢзҘһз»ҸзҪ‘з»ңзҝ»иҜ‘жЁЎеһӢдёӨеҘ—зі»з»ҹ пјҢ еҗҢж—¶еңЁжҖ§иғҪгҖҒеұ•зӨәж ·ејҸе’Ңе№Ійў„дёҠжңүдёҖеҘ—е®ҢеӨҮж–№жі• гҖӮ
 ж–Үз« жҸ’еӣҫ
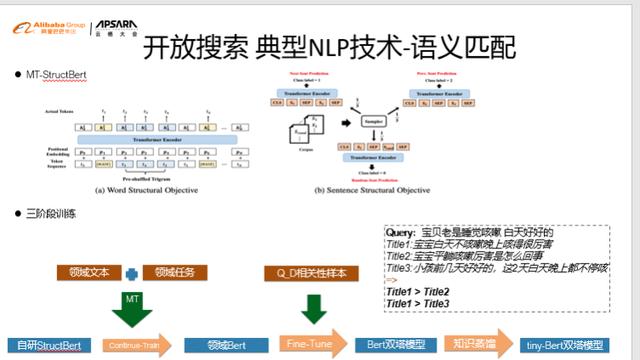
ж–Үз« жҸ’еӣҫиҜӯд№үеҢ№й…Қж·ұеәҰиҜӯиЁҖжЁЎеһӢзҡ„еҮәзҺ°з»ҷеҫҲеӨҡNLPд»»еҠЎеёҰжқҘдәҶи·Ёи¶ҠејҸзҡ„жҸҗеҚҮ пјҢ е°Өе…¶жҳҜеңЁиҜӯд№үеҢ№й…Қзӯүд»»еҠЎдёҠ гҖӮ иҫҫж‘©йҷўеңЁbertдёҠд№ҹжҸҗеҮәдәҶеҫҲеӨҡеҲӣж–° пјҢ жҸҗеҮәдәҶиҮӘз ”зҡ„StructBert гҖӮ дё»иҰҒеҲӣж–°зӮ№еңЁдәҺеңЁж·ұеәҰиҜӯиЁҖжЁЎеһӢи®ӯз»ғдёӯ пјҢ еўһеҠ дәҶеӯ—еәҸ/иҜҚеәҸзҡ„зӣ®ж ҮеҮҪж•° е’ҢжӣҙеӨҡж ·зҡ„еҸҘеӯҗз»“жһ„йў„жөӢзӣ®ж ҮеҮҪж•° пјҢ иҝӣиЎҢеӨҡд»»еҠЎеӯҰд№ гҖӮ дҪҶжҳҜиҝҷж ·зҡ„йҖҡз”Ёзҡ„structbertжҳҜж— жі•иҜ•з”Ёз»ҷејҖж”ҫжҗңзҙўйҮҢжҲҗеҚғдёҠдёҮдёӘе®ўжҲ· пјҢ жҲҗеҚғдёҠдёҮдёӘйўҶеҹҹзҡ„ гҖӮ жҲ‘们йңҖиҰҒеҒҡйўҶеҹҹйҖӮй…Қ гҖӮ жүҖд»ҘжҲ‘们жҸҗеҮәдәҶиҜӯд№үеҢ№й…Қ3йҳ¶ж®өиҢғејҸ гҖӮеҸҜд»Ҙеҝ«йҖҹзҡ„дёәе®ўжҲ·е®ҡеҲ¶йҖӮеҗҲдәҺиҮӘе·ұдёҡеҠЎзҡ„иҜӯд№үеҢ№й…ҚжЁЎеһӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫпјҲе…·дҪ“зҡ„жөҒзЁӢеҰӮеӣҫпјү
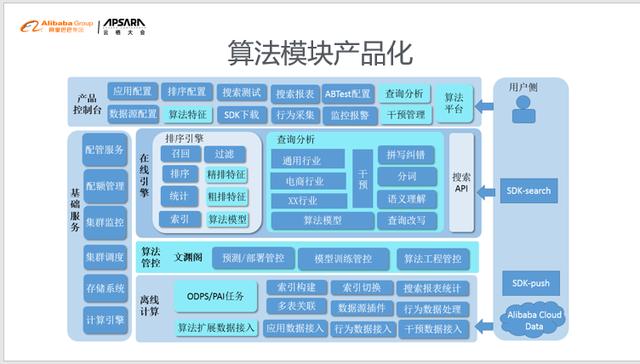
NLPз®—жі•дә§е“ҒеҢ–з®—жі•жЁЎеқ—дә§е“ҒеҢ–зҡ„зі»з»ҹжһ¶жһ„ пјҢ еҢ…еҗ«дәҶзҰ»зәҝи®Ўз®—гҖҒеңЁзәҝеј•ж“Һд»ҘеҸҠдә§е“ҒжҺ§еҲ¶еҸ° гҖӮ еӣҫдёӯжө…и“қиүІзҡ„йғЁеҲҶжҳҜNLPеңЁејҖж”ҫжҗңзҙўдёҠејҖж”ҫзҡ„з®—жі•зӣёе…іеҠҹиғҪ пјҢ з”ЁжҲ·еҸҜд»ҘзӣҙжҺҘеңЁжҺ§еҲ¶еҸ°дҪ“йӘҢе’ҢдҪҝз”Ё гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»ҘдёҠе°ұжҳҜжң¬ж¬Ўдә‘ж –еӨ§дјҡ--вҖңиҮӘ然иҜӯиЁҖеӨ„зҗҶеңЁејҖж”ҫжҗңзҙўдёӯзҡ„еә”з”ЁвҖқзҡ„еҶ…е®№ гҖӮ еҰӮжһңжӮЁеҜ№жҗңзҙўдёҺжҺЁиҚҗзӣёе…іжҠҖжңҜж„ҹе…ҙи¶Ј пјҢ ж¬ўиҝҺеҠ е…Ҙй’үй’үзҫӨеҶ…дәӨжөҒ~
гҖҗејҖж”ҫжҗңзҙўгҖ‘ж–°з”ЁжҲ·жҙ»еҠЁпјҡйҳҝйҮҢдә‘е®һеҗҚи®ӨиҜҒз”ЁжҲ·дә«1дёӘжңҲе…Қиҙ№иҜ•з”Ё
жҺЁиҚҗйҳ…иҜ»













- iQOO 7жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁе’Ң120Wи¶…е……пјҢ3798е…ғиө·е”®
- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- иҷҫзұійҹід№җж’ӯж”ҫеҷЁе°ҶдәҺ2жңҲ5ж—ҘеҒңжӯўжңҚеҠЎпјҢд»ҠејҖеҗҜз”ЁжҲ·иө„дә§еӨ„зҗҶйҖҡйҒ“
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- жңҖеӨ§йЈһиЎҢй«ҳеәҰ25зұіпјҒе°Ҹй№ҸйЈһиЎҢжұҪиҪҰдә®зӣёпјҢиҜ•д№ҳиҜ•й©ҫе°Ҷд»Ҡе№ҙејҖж”ҫ
- RHEL 9жҸҗеҚҮдәҶx86_64еӨ„зҗҶеҷЁзҡ„е…Ҙй—ЁиҰҒжұӮ
- 2020зҷҫеәҰең°еӣҫз”ҹжҖҒеӨ§дјҡпјҡејҖж”ҫе№іеҸ°еҚҒе‘Ёе№ҙ дёәиЎҢдёҡйҖҒеҮәеӨҡдёӘи§ЈеҶіж–№жЎҲвҖңеӨ§зӨјеҢ…вҖқ
- иҒ”жғіIdeaPad 5 Proзі»еҲ—笔记жң¬еҸ‘еёғ еҸҜйҖүдёӨз§ҚеӨ„зҗҶеҷЁе’ҢдёӨз§Қе°әеҜё
- иҒ”жғіжҺЁеҮәжҗӯиҪҪйӘҒйҫҷеӨ„зҗҶеҷЁзҡ„IdeaPad 5G
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј