Loki告警的正确姿势
正文共1255字预计阅读时间:3分钟
【Loki告警的正确姿势】小白之前有通过Grafana设置Loki数据源的骚操作来做日志告警 , 虽然能直接在Grafana面板上配置告警 , 但它们还是没办法集中维护和管理 。 小白前面介绍了那么多关于Loki的文章 , 那么它有没有像Prometheus一样的rules来管理策略呢?答案是肯定的!
根据Loki的RoadMap , Ruler组件将于Loki 1.7.0版本正式推出 。 那么小白今天先带大家尝尝鲜 , 体验下在Loki里日志告警的正确姿势 。
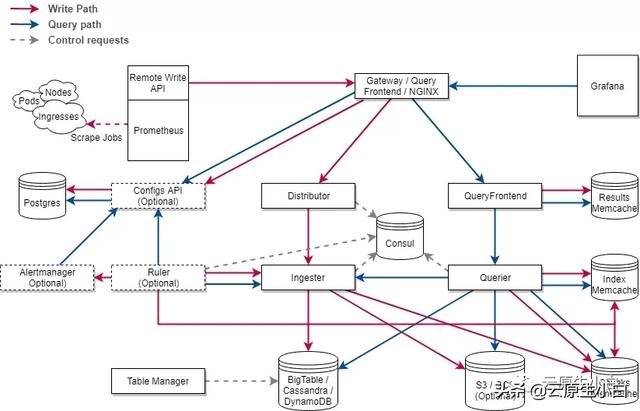
Loki RulerLoki1.7将包含一个名为Ruler的组件 , 它是从Crotex项目里面引入进来的(还记得Loki分集群的架构吗?)Ruler的主要功能是持续查询rules规则 , 并将超过阈值的事件推送给Alert-Manager或者其他Webhook服务 。
 文章插图
文章插图
结合Cortex , Loki的Ruler组件也是如上的架构 。 可以看到loki和cortex的架构主要区别只剩下Configs API了 。 不过 , 牛逼的是借助注册到consul的一致性hash环 , Loki的ruler同样支持多实例的分布式部署 , 实例和实例之间会自己根据分片协调需要使用的rules 。 不过这是一个动态的过程 , 任何ruler实例的添加或删除都会导致rules的重新分片 。
当前启用Loki的ruler组件比较简单 , 只要将下列的相关配置引入 , 并在Loki启动的参数里面加入-target=ruler即可 。
ruler:# 触发告警事件后的回调查询地址# 如果用grafana的话就配置成grafana/exploreexternal_url:# alertmanager地址alertmanager_url:enable_alertmanager_v2: true# 启用loki rules APIenable_api: true# 对rules分片 , 支持ruler多实例enable_sharding: true# ruler服务的一致性哈希环配置 , 用于支持多实例和分片ring:kvstore:consul:host: 想快速体验Ruler的同学 , 可以用小白之前docker-compose来部署demo
Alert配置Loki的rulers规则和结构与Prometheus完全兼容 , 唯一的区别在于查询语句不同 。 在Loki中我们用logQL来查询日志指标 。 一个典型的rules配置说明如下:
groups:# 组名称- name:rules:# Alert名称- alert:# logQL查询语句expr:# 产生告警的持续时间pending.[ for: 举个栗子 , 如果小白想通过日志查到某个业务日志的错误率大于5%就触发告警 , 那么可以配置成这样:
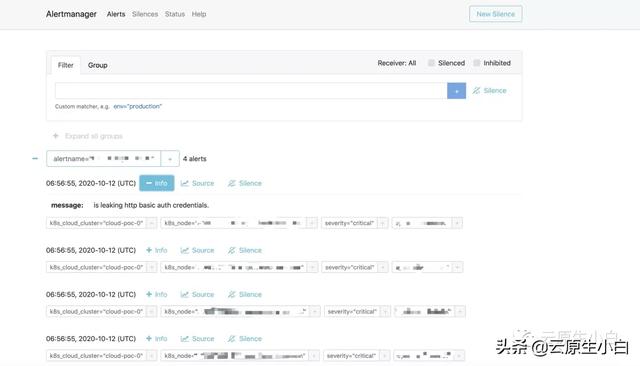
groups:- name: should_firerules:- alert: HighPercentageErrorexpr: |sum(rate({app="foo", env="production"} |= "error" [5m])) by (job)/sum(rate({app="foo", env="production"}[5m])) by (job)> 0.05for: 10mlabels:severity: pageannotations:summary: High request latency当告警事件产生时 , 我们在alert-manager上就能收到该事件的推送 。
 文章插图
文章插图
Ruler用途
- 还没用metrics做应用监控告警时
- 黑匣子监控
推荐阅读




![[国足]喜讯!国足后防线出现新选择,4大归化后卫可用,世预赛不怕了](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/a073560cdaea50289238bb24c891b90d.jpg)




![[艺术时尚人生]4种天然养胃药经常吃,一颗好胃伴你到,胃病犯了不用愁](https://imgcdn.toutiaoyule.com/20200419/20200419051056971072a_t.jpeg)








- 5nm芯片接连翻车,华为、高通无一例外,联发科才是正确决定?
- 升级RTX 30显卡,才是解锁《赛博朋克2077》完全体的正确姿势
- 缠论的中心思想是什么?如何正确的学习缠论?怎么知道自己入门?
- 如何正确地学习编程语言
- 产品|如何正确选购充电暖手宝?安全提醒来了
- 这才是正确清理苹果手机内存的方法,清理后和新机一样流畅
- 正确使用#include语句的双引号形式和角括号形式
- 领导者的核心是战略定力
- 丁香医生|低头玩手机 = 头顶 50 斤!教你 3 个玩手机的正确姿势
- 7年Java开发(月薪37K)分享正确的自学路线,不喜勿喷